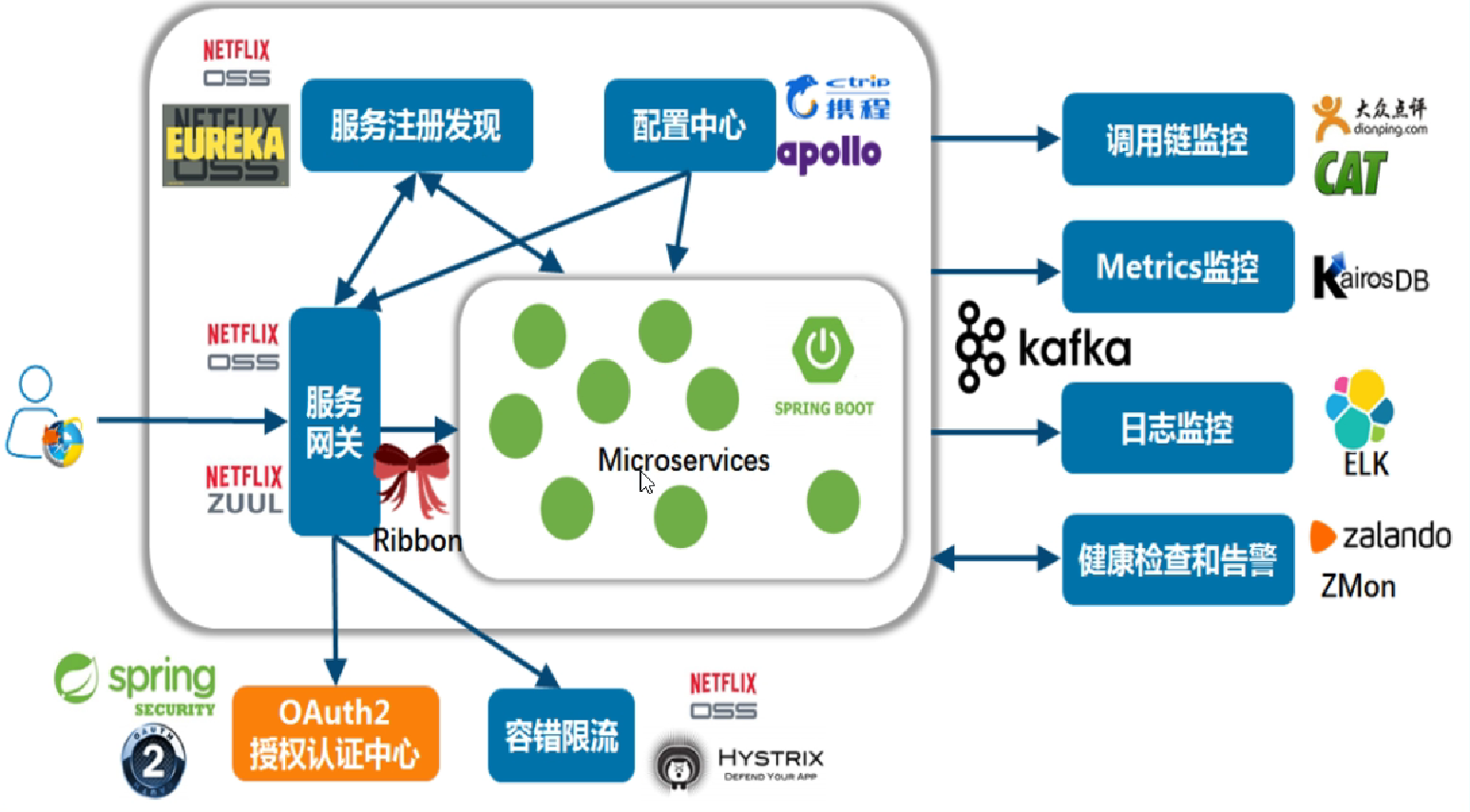
一、微服务的概述
1、什么是微服务,什么是微服务架构?
业界大牛马丁.福勒(Martin Fowler) 这样描述微服务:
论文网址:https://martinfowler.com/articles/microservices.html
微服务
- 强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,
- 狭意的看,可以看作Eclipse里面的一个个微服务工程/或者Module
微服务架构

微服务架构是⼀种架构模式,它提倡将单⼀应⽤程序划分成⼀组⼩的服务,服务之间互相协调、互相配合,为⽤户提供最终价值。每个服务运⾏在其独⽴的进程中,服务与服务间采⽤轻量级的通信机制互相协作(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体业务进⾏构建,并且能够被独⽴的部署到⽣产环境、类⽣产环境等。另外,应当尽量避免统⼀的、集中式的服务管理机制,对具体的⼀个服务⽽⾔,应根据业务上下⽂,选择合适的语⾔、⼯具对其进⾏构建。
技术维度理解
微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事,从技术角度看就是一种小而独立的处理过程,类似进程概念,能够自行单独启动或销毁,拥有自己独立的数据库。
2、微服务技术栈有哪些?
| 微服务条目 | 落地技术 | 备注 |
|---|---|---|
| 服务开发 | Springboot、Spring、SpringMVC | |
| 服务配置与管理 | Netflix公司的Archaius、阿里的Diamond等 | |
| 服务注册与发现 | Eureka、Consul、Zookeeper等 | |
| 服务调用 | Rest、RPC、gRPC | |
| 服务熔断器 | Hystrix、Envoy等 | |
| 负载均衡 | Ribbon、Nginx等 | |
| 服务接口调用(客户端调用服务的简化工具) | Feign等 | |
| 消息队列 | Kafka、RabbitMQ、ActiveMQ等 | |
| 服务配置中心管理 | SpringCloudConfig、Chef等 | |
| 服务路由(API网关) | Zuul等 | |
| 服务监控 | Zabbix、Nagios、Metrics、Spectator等 | |
| 全链路追踪 | Zipkin,Brave、Dapper等 | |
| 服务部署 | Docker、OpenStack、Kubernetes等 | |
| 数据流操作开发包 | SpringCloud Stream(封装与Redis,Rabbit、Kafka等发送接收消息) | |
| 事件消息总线 | Spring Cloud Bus |

现在有些已经不再使用,有新的技术进行替代
详情看组件替换
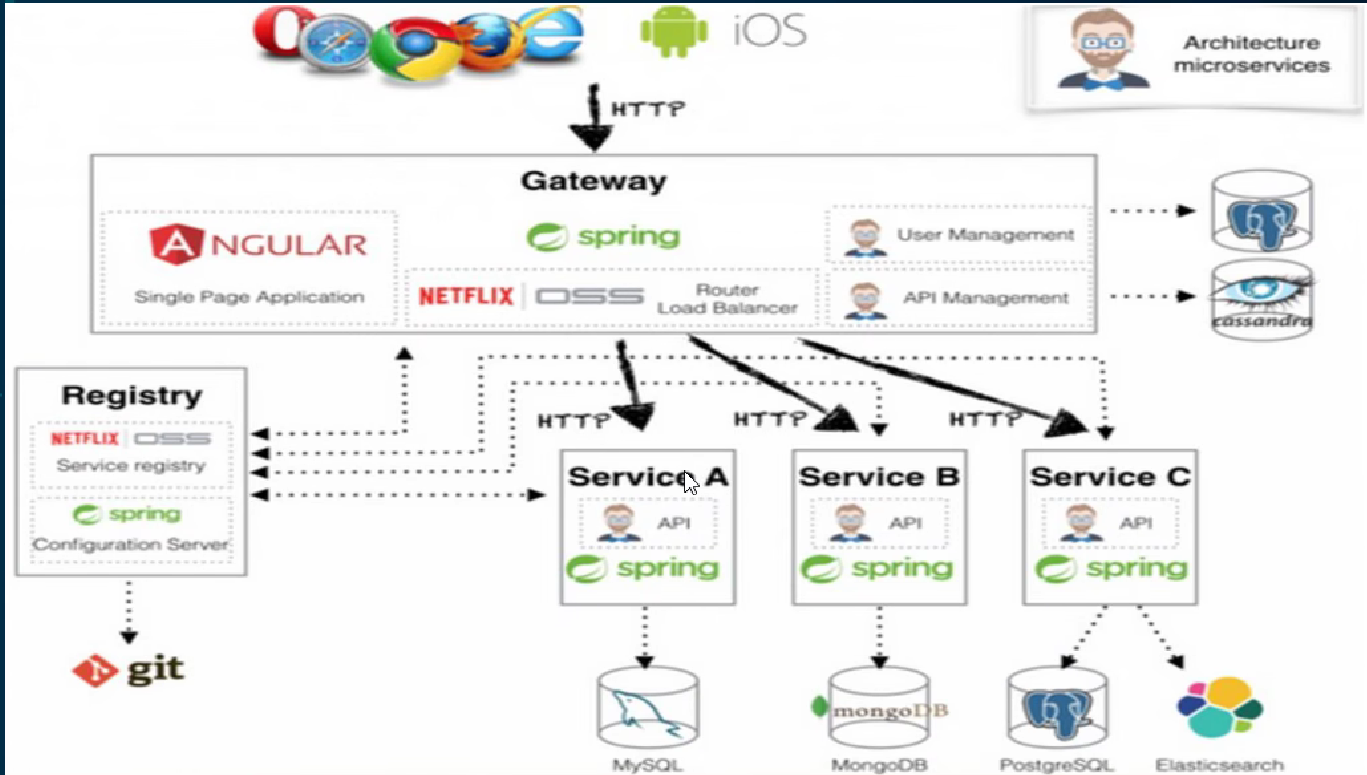
二、SpringCloud
1、官网说明
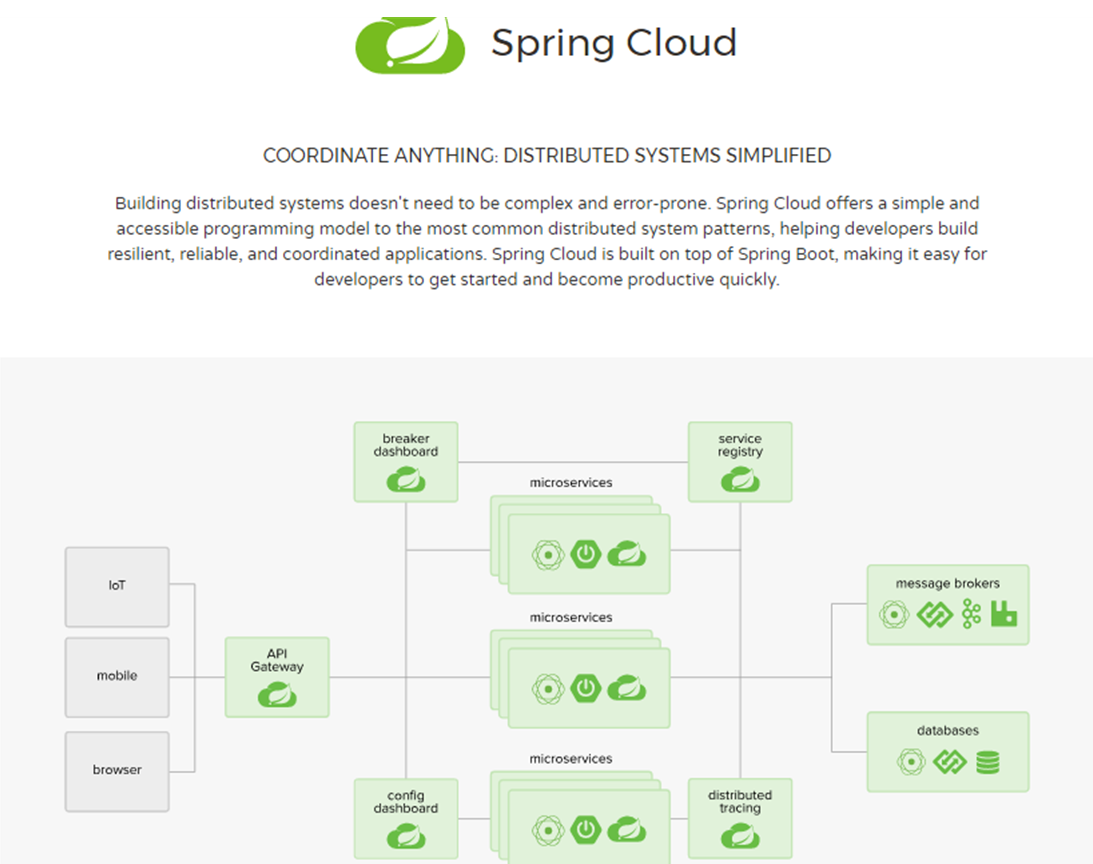
1 | SpringCloud,基于SpringBoot提供了一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件,除了基于NetFlix的开源组件做高度抽象封装之外,还有一些选型中立的开源组件。 |
2、概述
SpringCloud=分布式微服务架构下的一站式解决方案,
是各个微服务架构落地技术的集合体,俗称微服务全家桶
3、SpringCloud和SpringBoot的关系
SpringBoot专注于快速方便的开发单个个体微服务。
SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,
为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系.
SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
4、Dubbo是怎么到SpringCloud的?哪些优缺点让你去技术选型
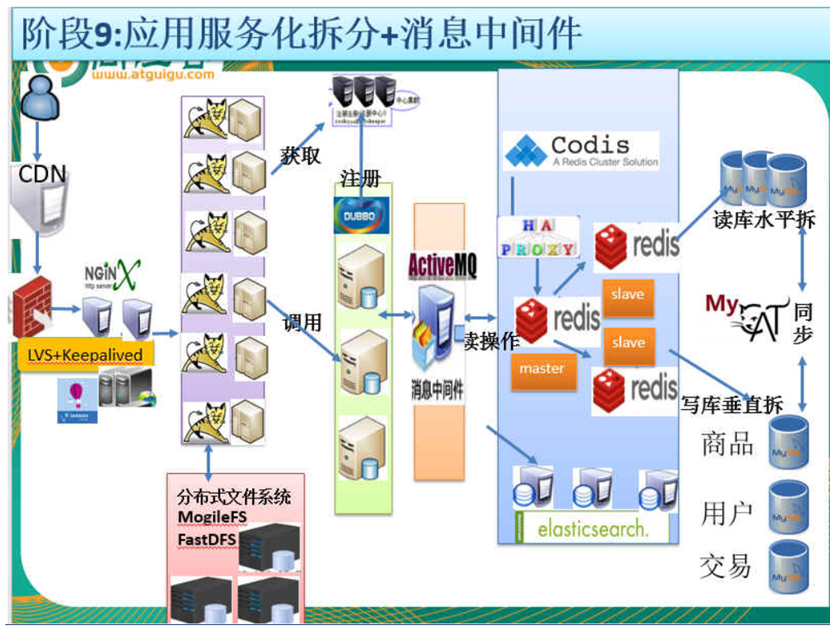
4.1、目前成熟的互联网架构(分布式+服务治理Dubbo)
4.2、SpringCloud和Dubbo对比
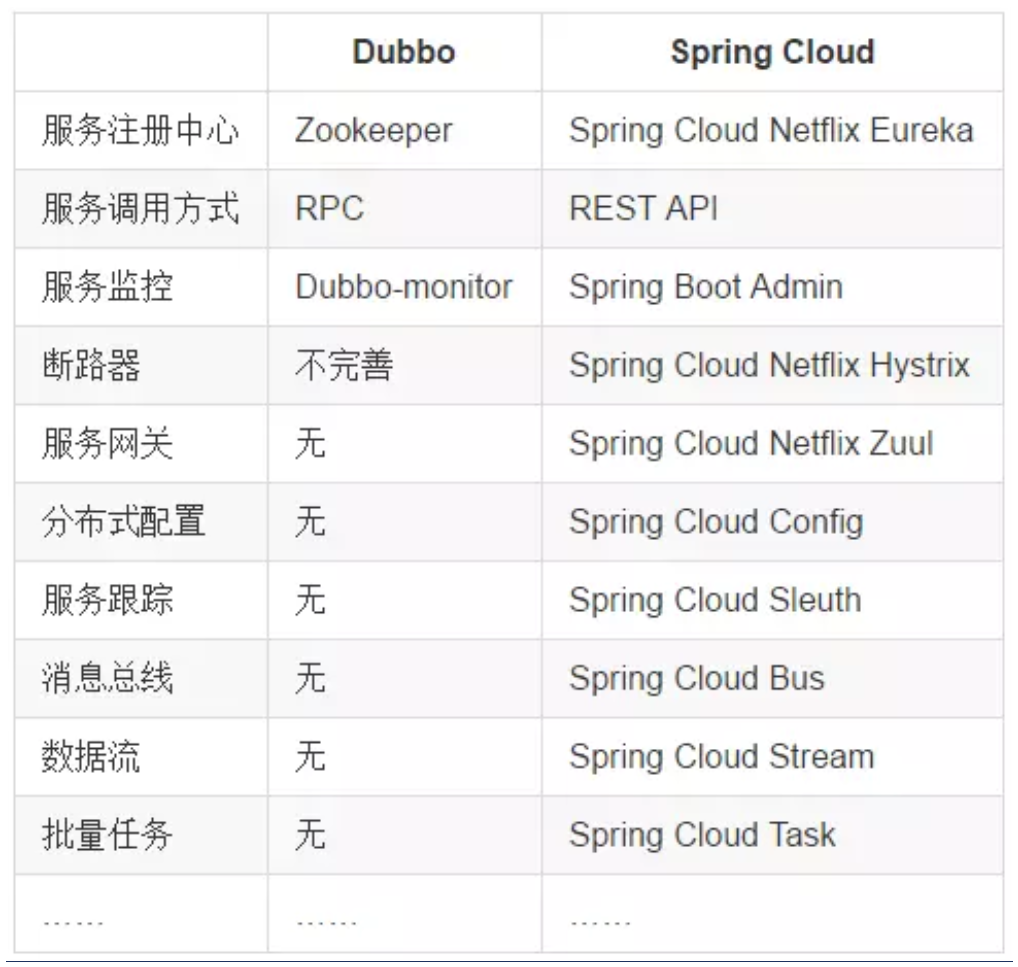
1 | 最大区别:SpringCloud抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式。 |
4.3、总结
问题:
曾风靡国内的开源 RPC 服务框架 Dubbo 在重启维护后,令许多用户为之雀跃,但同时,也迎来了一些质疑的声音。互联网技术发展迅速,Dubbo 是否还能跟上时代?Dubbo 与 Spring Cloud 相比又有何优势和差异?是否会有相关举措保证 Dubbo 的后续更新频率?
人物:Dubbo重启维护开发的刘军,主要负责人之一
刘军,阿里巴巴中间件高级研发工程师,主导了 Dubbo 重启维护以后的几个发版计划,专注于高性能 RPC 框架和微服务相关领域。曾负责网易考拉 RPC 框架的研发及指导在内部使用,参与了服务治理平台、分布式跟踪系统、分布式一致性框架等从无到有的设计与开发过程。

5、参考资料
官网:Spring Cloud
参考书:
Spring Cloud Netflix 中文文档 参考手册 中文版
springcloud中国社区:Spring Cloud中国社区
springcloud中文网:Spring Cloud中文网-官方文档中文版
三、SpringBoot和SpringCloud等其他技术的版本选择
1、查看方式
2、确定版本
老版本:
| 技术 | 版本 |
|---|---|
| springcloud | Hoxton.SR1 |
| springboot | 2.2.2.RELEASE |
| cloud alibaba | 2.1.0.RELEASE |
| java | java8 |
| Maven | 3.5及以上 |
| MySQL | 5.7及以上 |
新版本:
| 技术 | 版本 |
|---|---|
| springcloud | 2021.0.6 |
| springboot | 2.6.13 |
| cloud alibaba | 2021.0.4.0 |
| java | java8 |
| Maven | 3.5及以上 |
| MySQL | 5.7及以上 |
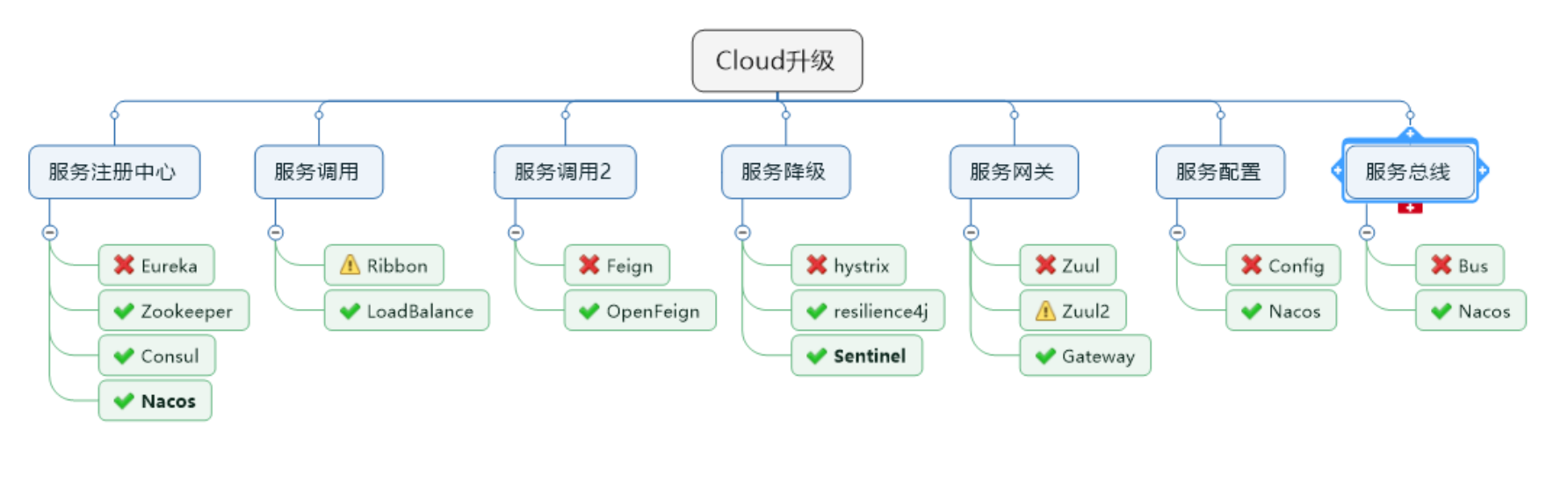
四、关于SpringCloud各种组件的停更/升级/替换
参考文档:
https://www.bookstack.cn/read/spring-cloud-docs/docs-index.md
Spring Boot 中文文档 (springdoc.cn)
五、微服务架构编码构建
首先要明确一点:约定>配置>编码
1、idea新建父工程一系列操作说明
1.1、idea新建父工程及其配置
1.1、New Project
也可
1.1.2、创建名称
名称:cloud2020
组:com.lxg.springcloud
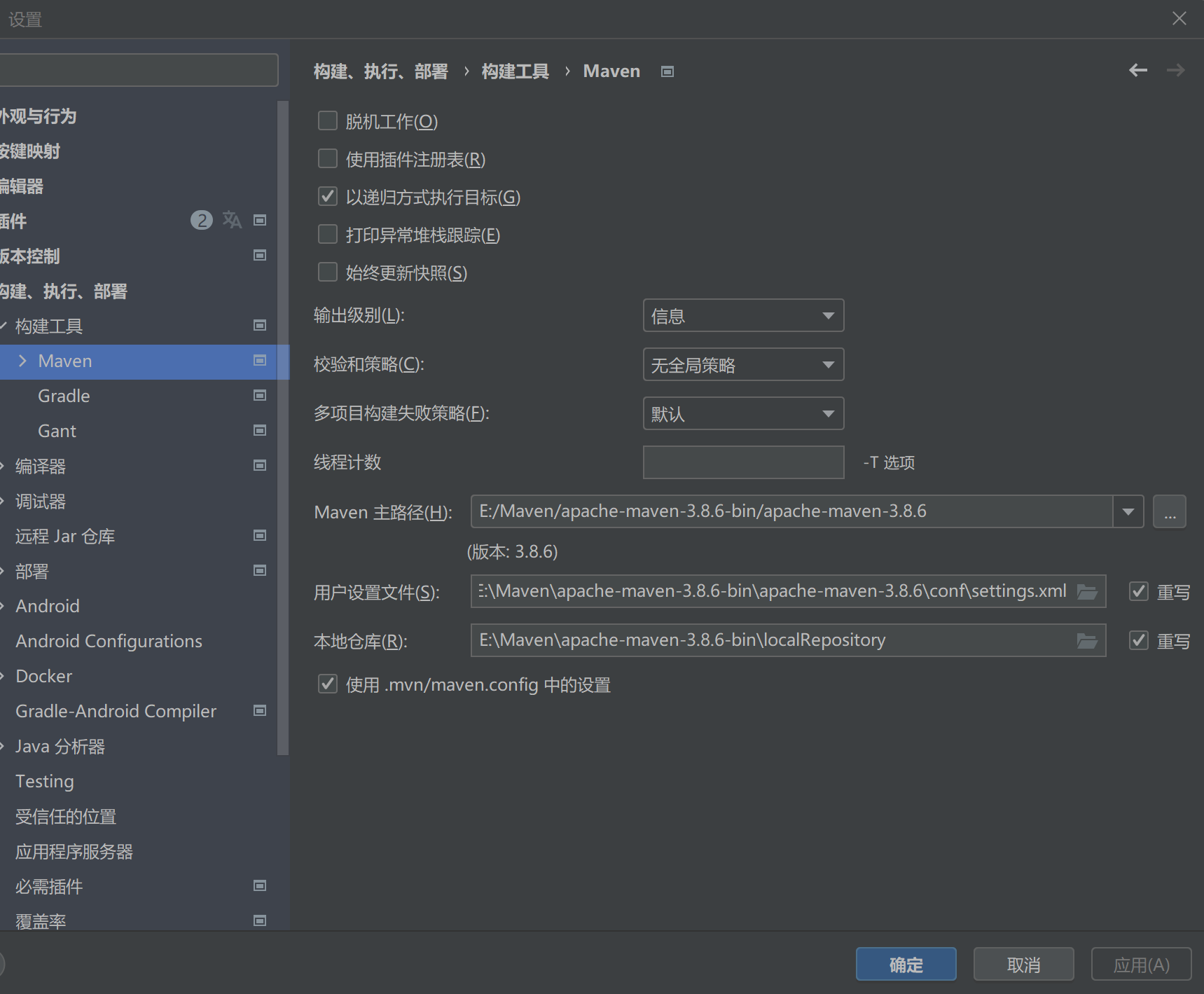
1.1.3、Maven选版本
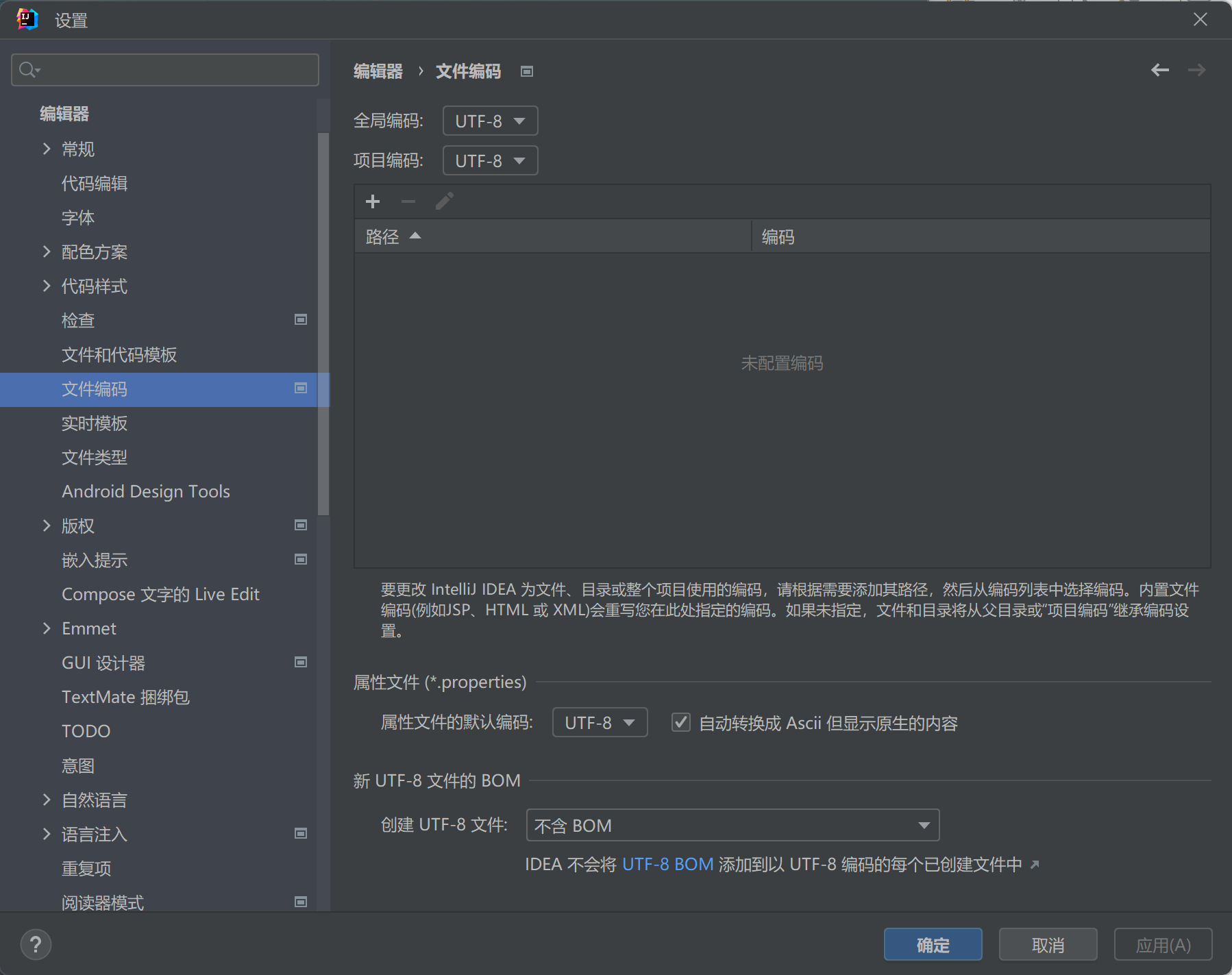
1.1.4、字符编码
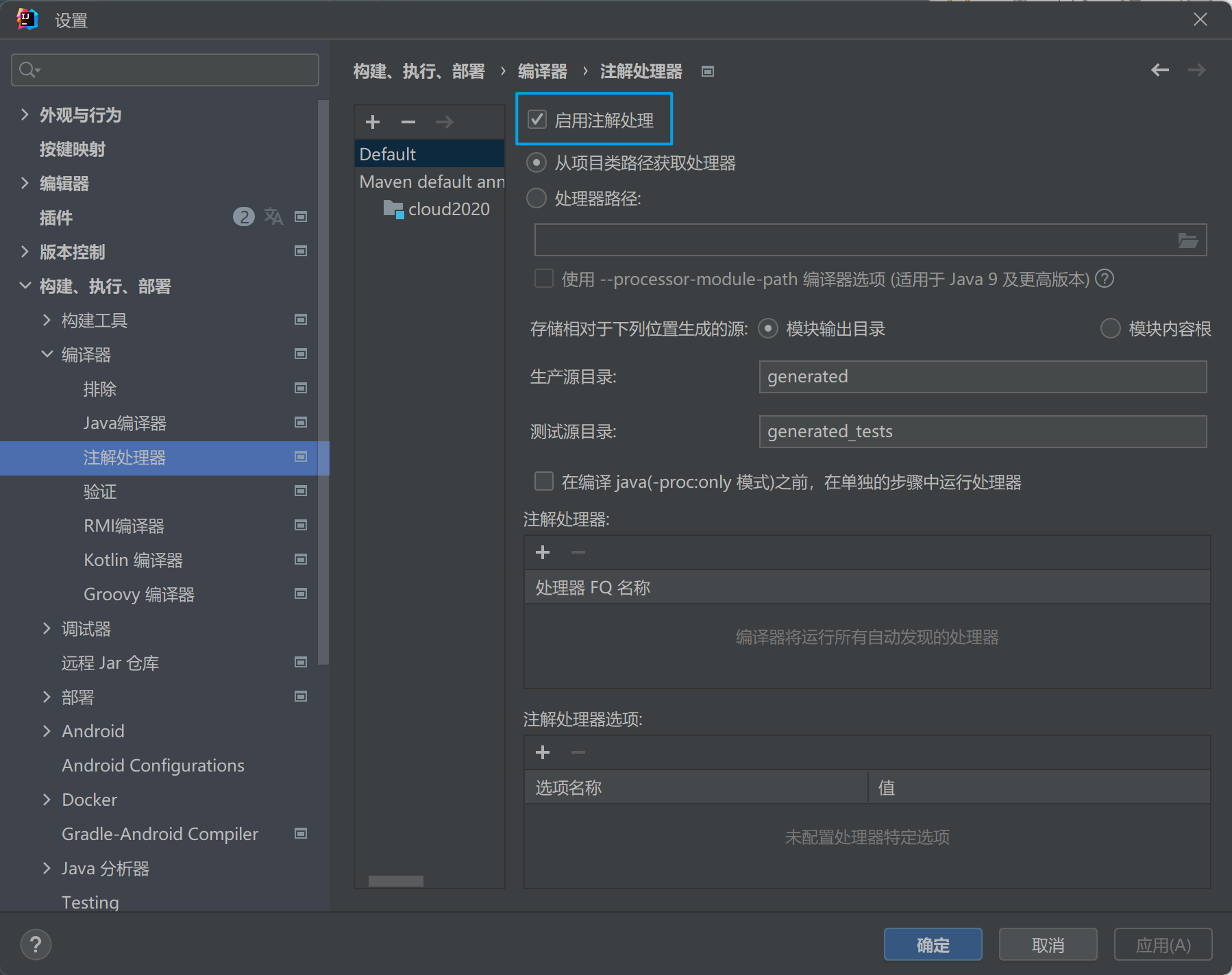
1.1.5、注解生效激活
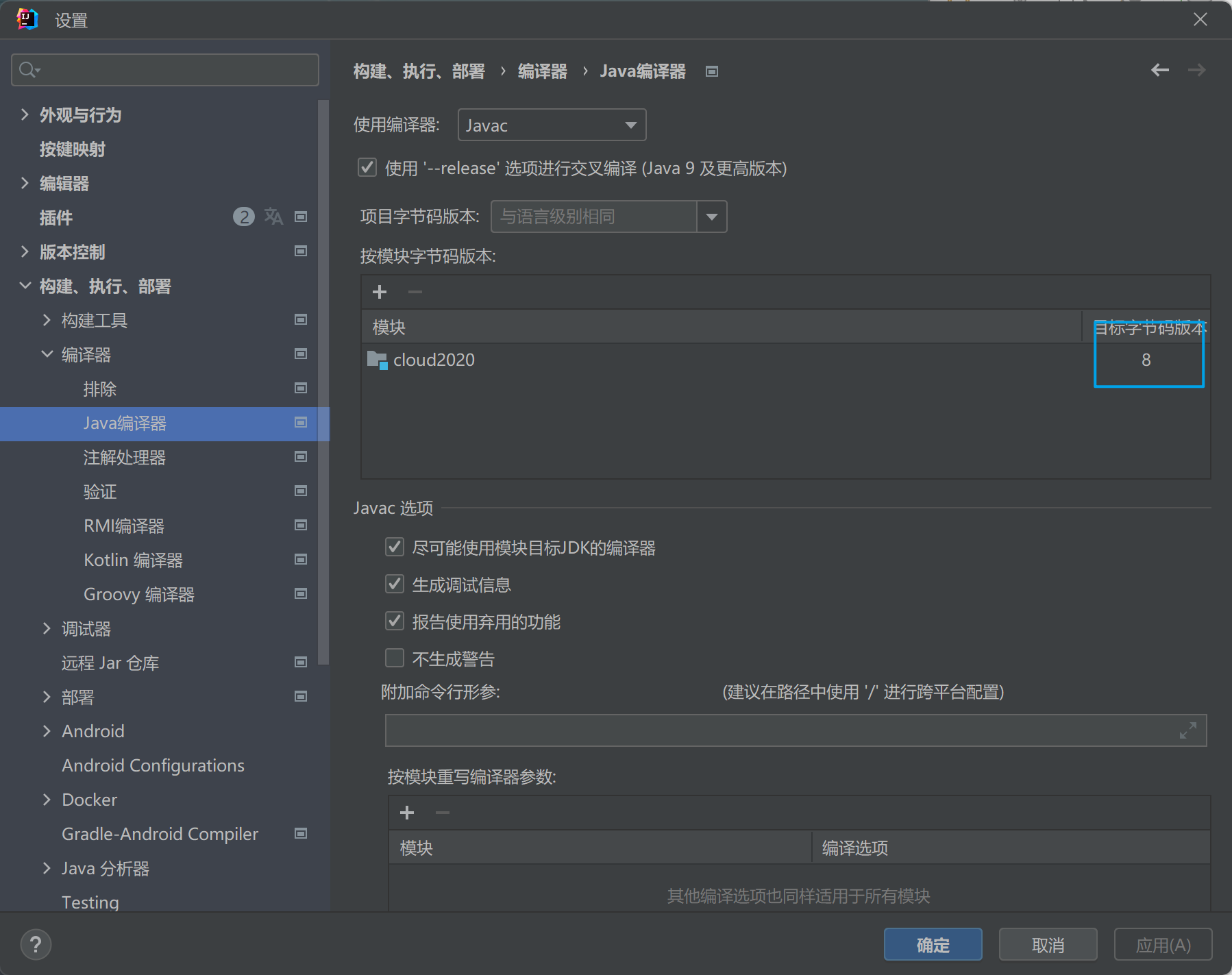
1.1.6、java编译版本选择8
1.2、父工程pom文件
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
1.3、Maven工程落地细节
1.3.1、dependencyManagement
Maven 使用dependencyManagement 元素来提供了一种管理依赖版本号的方式。
通常会在一个组织或者项目的最顶层的父POM 中看到dependencyManagement 元素。
使用pom.xml 中的dependencyManagement 元素能让所有在子项目中引用一个依赖而不用显式的列出版本号。
Maven 会沿着父子层次向上走,直到找到一个拥有dependencyManagement 元素的项目,然后它就会使用这个
dependencyManagement 元素中指定的版本号。
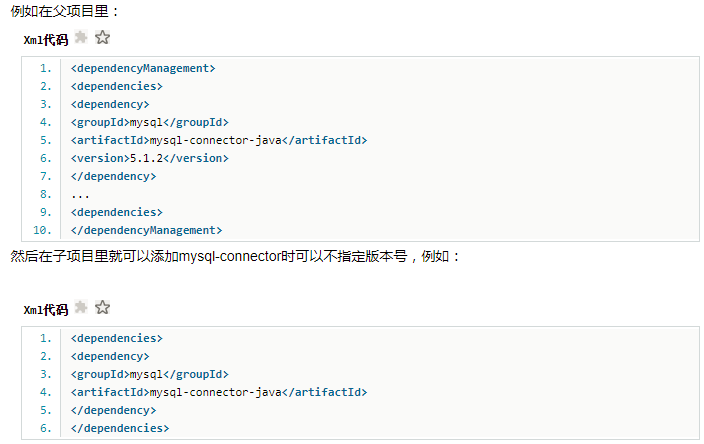
这样做的好处就是:如果有多个子项目都引用同一样依赖,则可以避免在每个使用的子项目里都声明一个版本号,这样当想升级或切换到另一个版本时,只需要在顶层父容器里更新,而不需要一个一个子项目的修改 ;另外如果某个子项目需要另外的一个版本,只需要声明version就可。
dependencyManagement里只是声明依赖,并不实现引入,因此子项目需要显示的声明需要用的依赖。- 如果不在子项目中声明依赖,是不会从父项目中继承下来的;只有在子项目中写了该依赖项,并且没有指定具体版本,
才会从父项目中继承该项,并且version和scope都读取自父pom; 如果子项目中指定了版本号,那么会使用子项目中指定的jar版本。
1.3.2、跳过测试
1.4、父工程执行install操作
1.5、msql驱动说明
1 | com.mysql.jdbc.Driver和mysql-connector-java 5一起用。 |
2、Rest微服务架构编码构建
主要流程
1 | 1、建module |
2.1、cloud-provider-payment8001模块搭建
2.1.1、创建模块
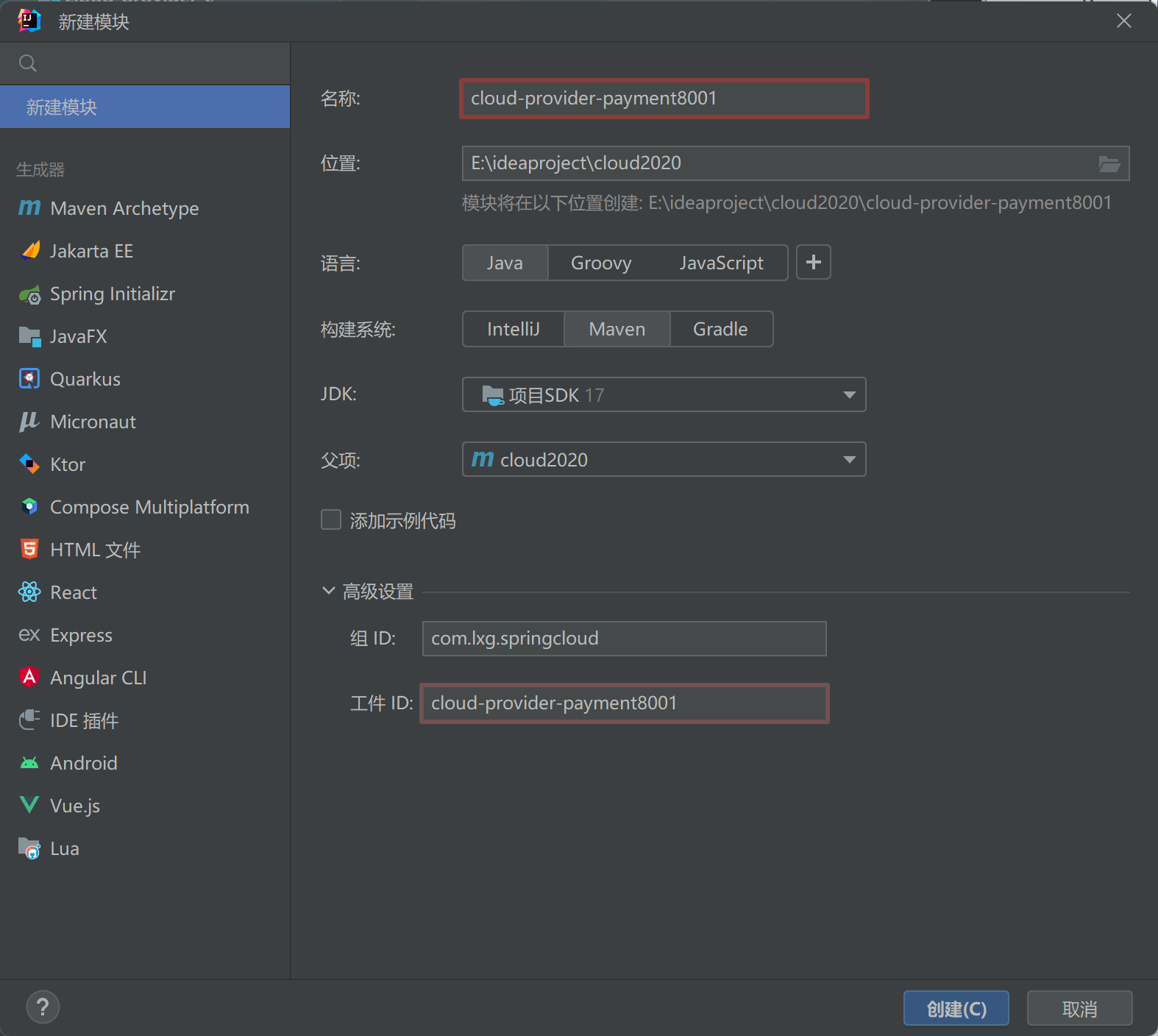
此时父工程的pom文件会多以下内容
1 | <modules> |
2.1.2、修改模块pom文件(不是父工程)
1 |
|
2.1.3、在resources下新建application.yml文件
1 | server: |
2.1.4、编写主启动类
1 | package com.lxg.springcloud; |
2.1.5、编写业务类
1、建表
1 | CREATE TABLE `payment` ( |
2、实体类enties
主实体:
1 | package com.lxg.springcloud.entities; |
json封装体(返回给前端的)
1 | package com.lxg.springcloud.entities; |
3、dao
PaymentDao:
1 | package com.lxg.springcloud.dao; |
dao对应映射文件:(resources/mapper/xxx)
1 |
|
文件模板头:
1 |
|
4、service
接口:
1 | package com.lxg.springcloud.service; |
实现类:
1 | package com.lxg.springcloud.service.impl; |
5、controller
1 | package com.lxg.springcloud.controller; |
2.1.6、测试
查询:
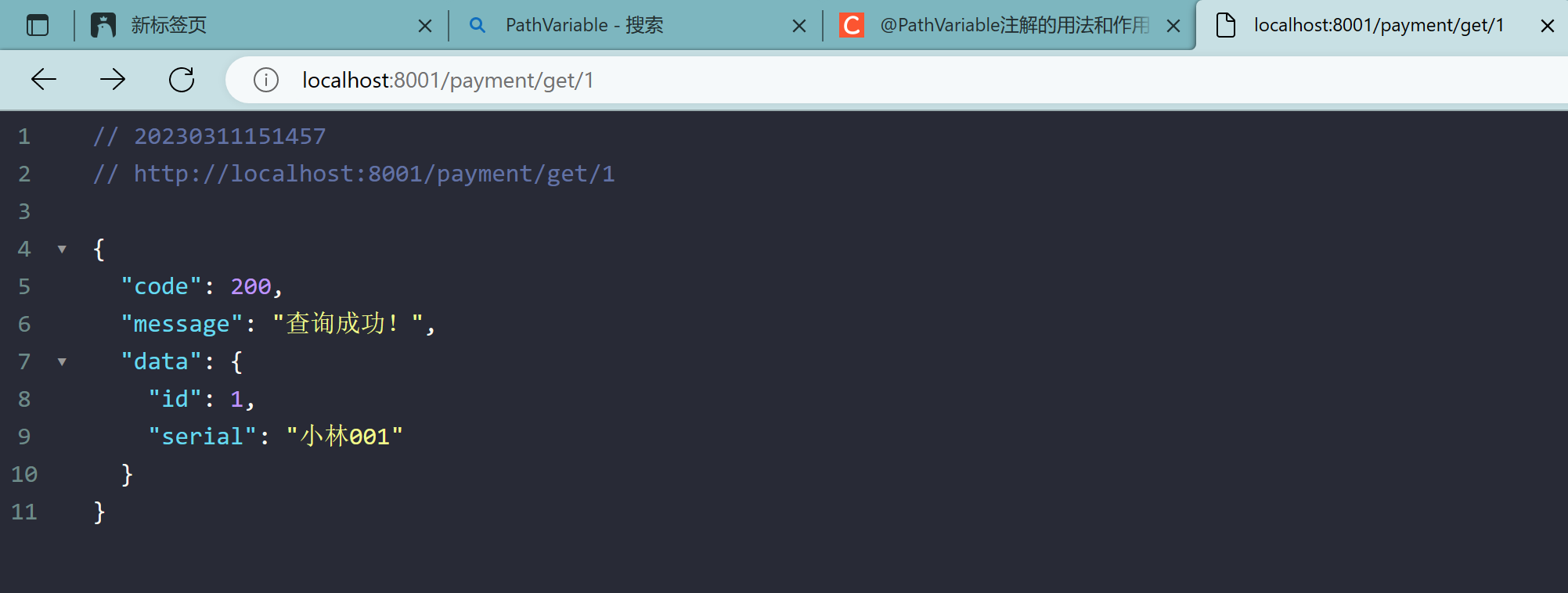
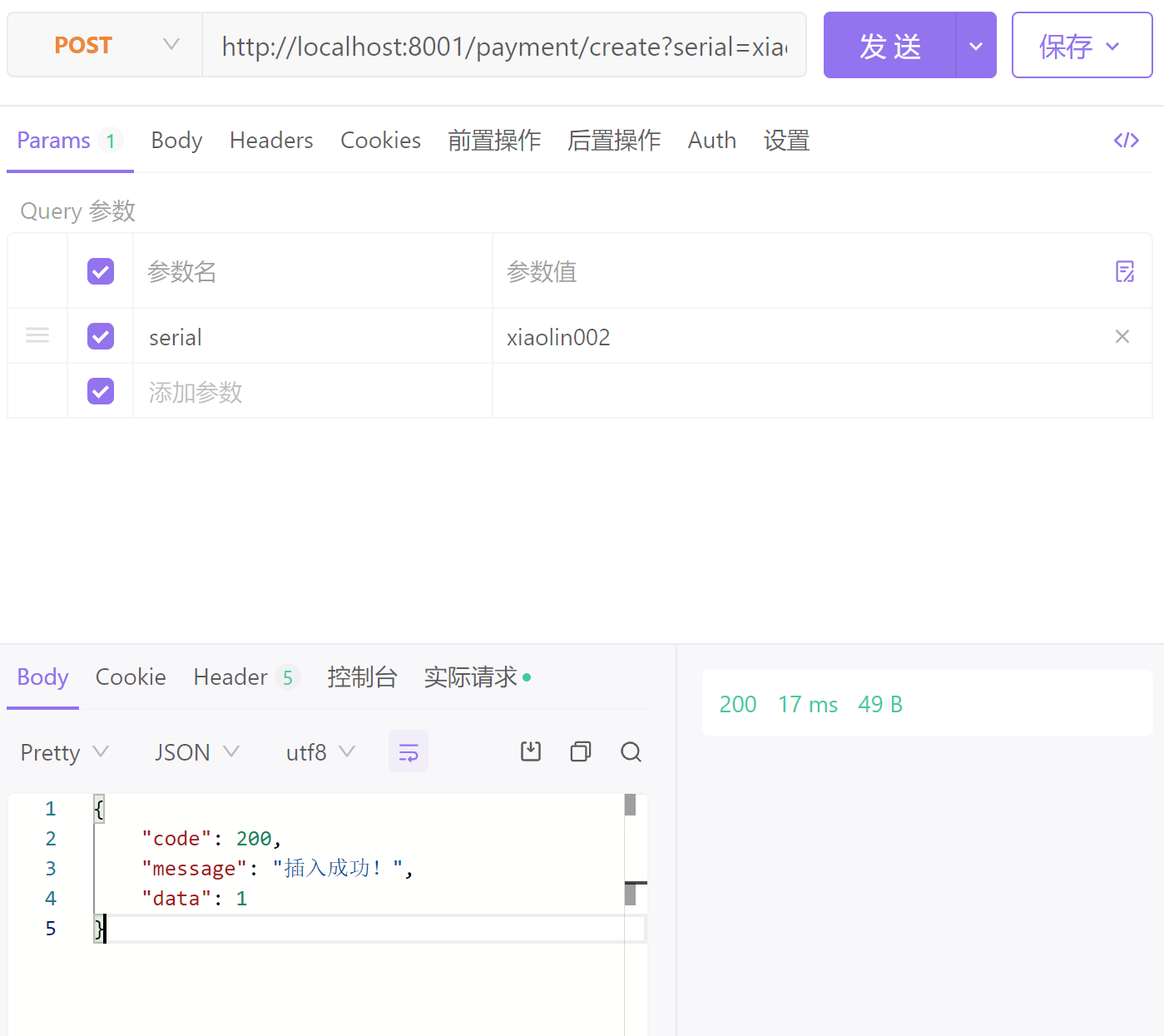
添加:由于浏览器默认都是get请求,可使用apifox或postman等工具发送其他请求
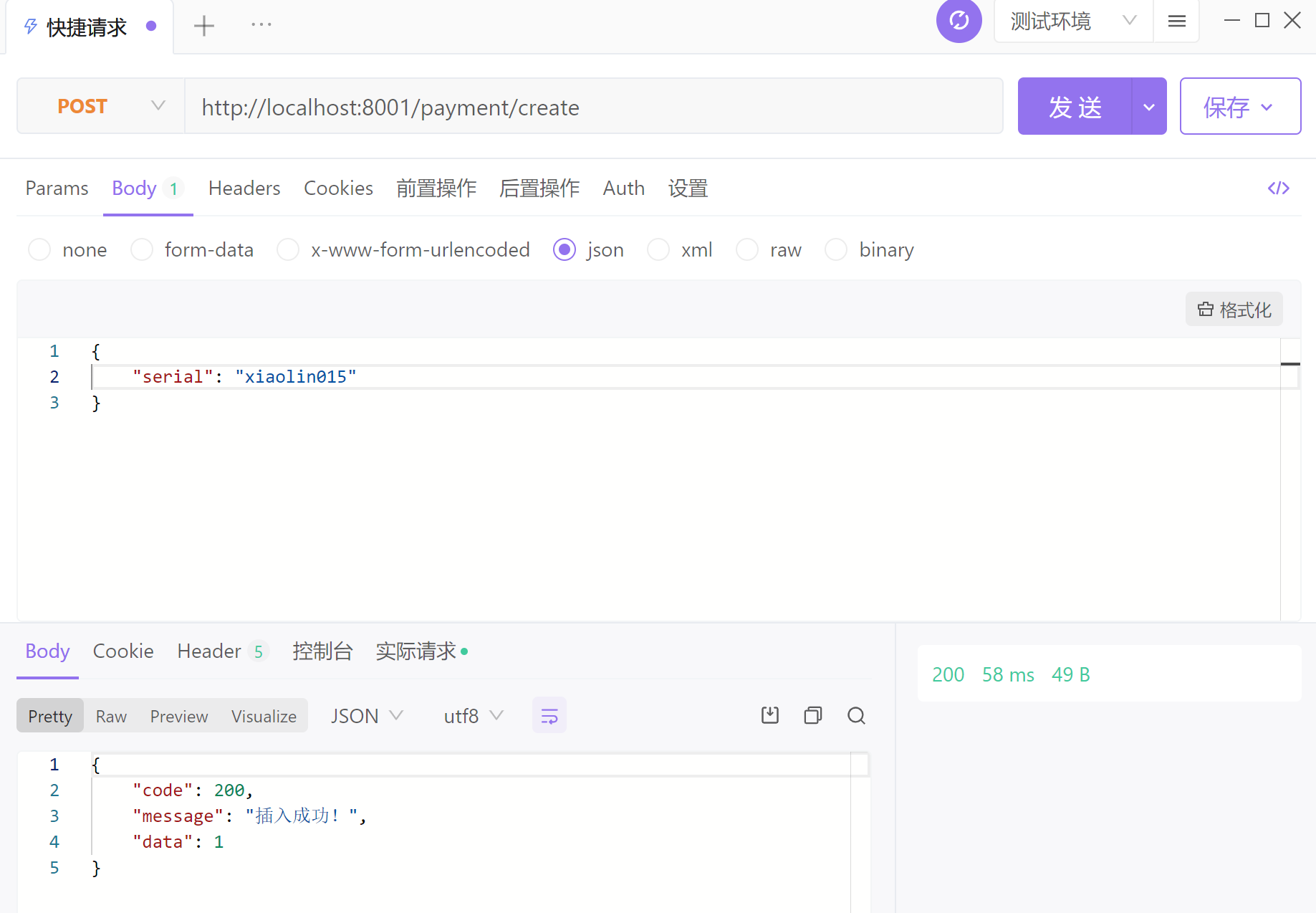
http://localhost:8001/payment/create?serial=xiaolin002
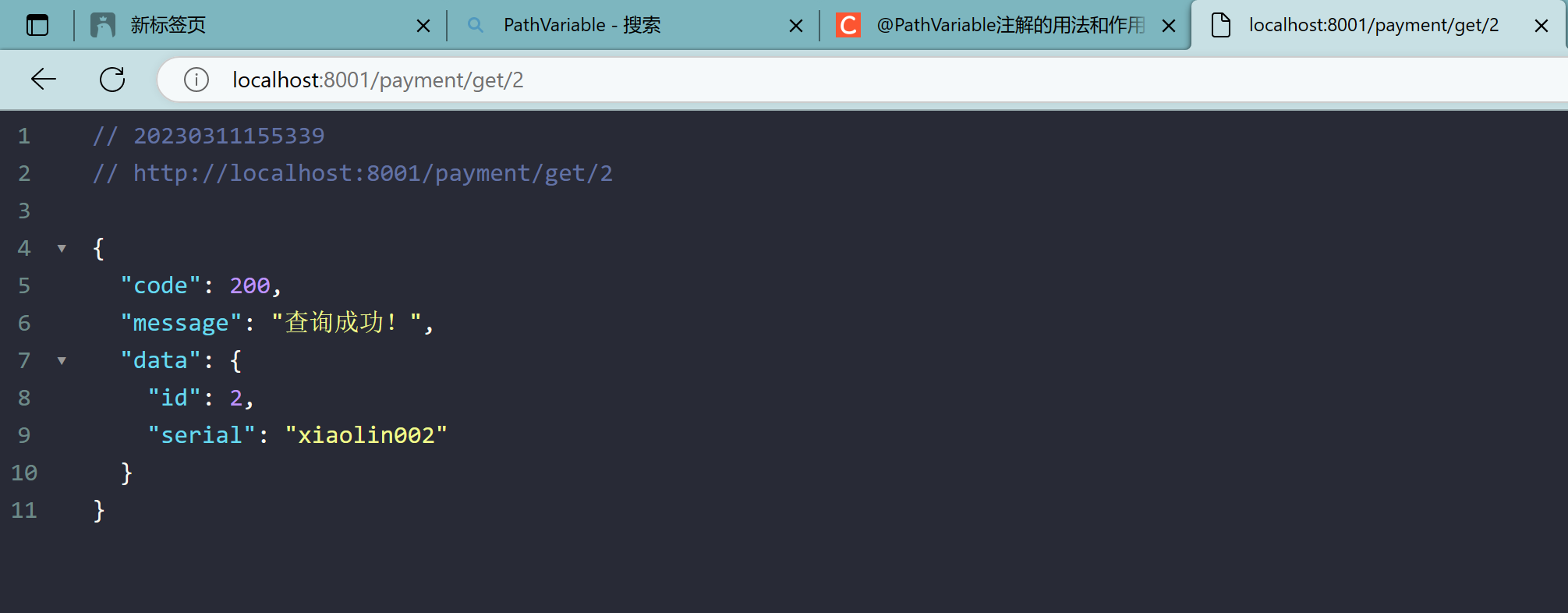
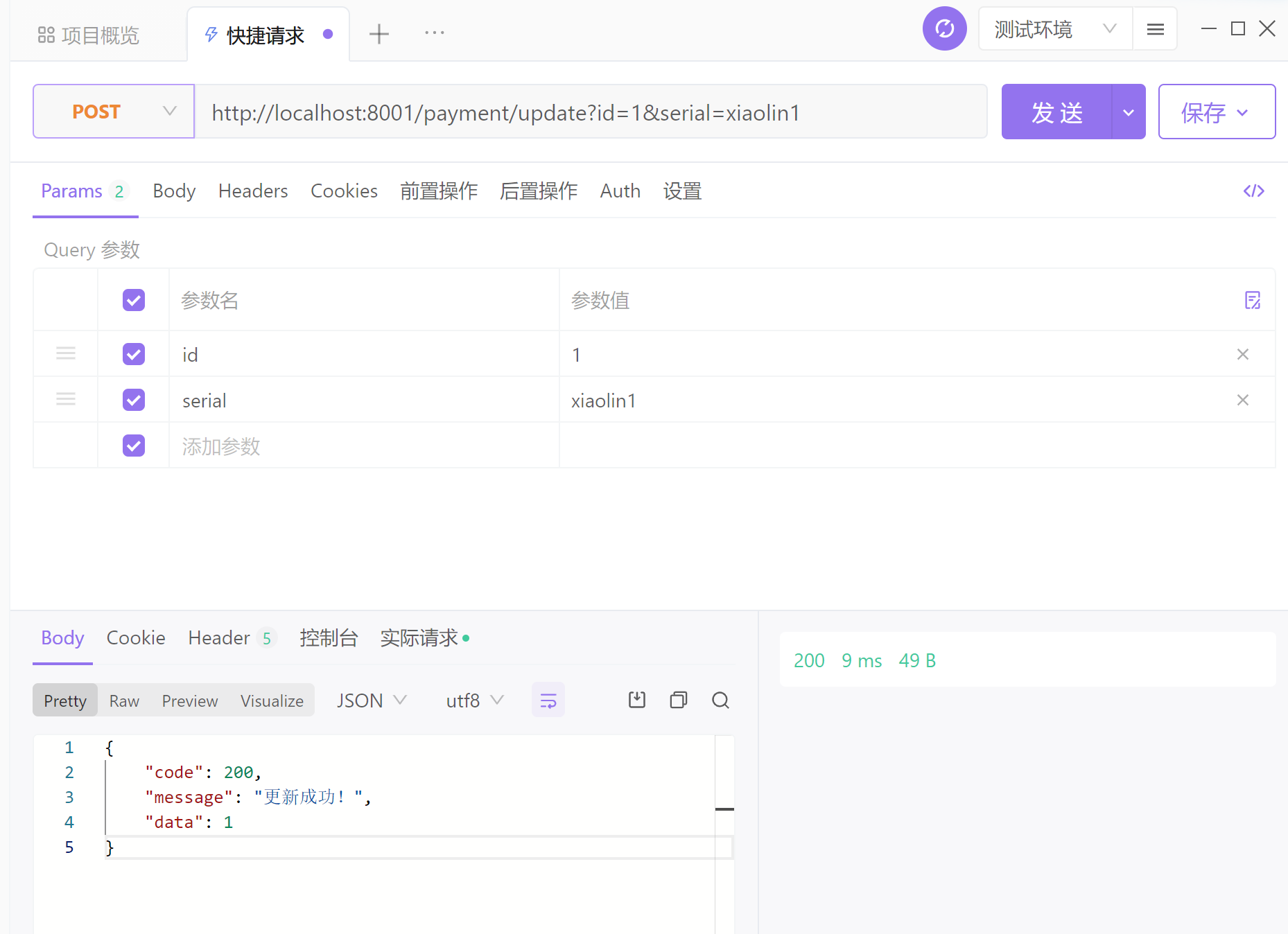
修改:
http://localhost:8001/payment/update/?id=1&serial=xiaolin1
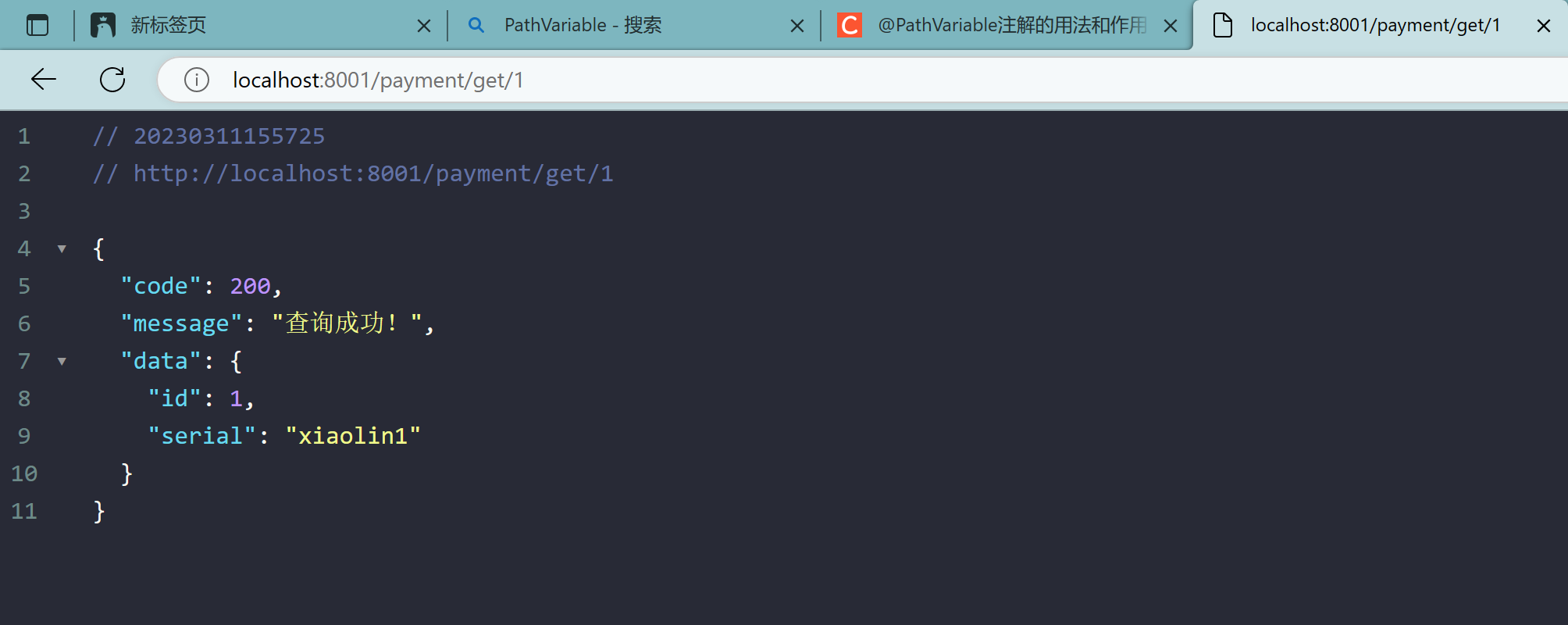
删除:
localhost:8001/payment/delete/5
运行:
现在还只是单个模块,所以只需要运行即可,到项目增多,会有一个Run DashBoard按钮出现统一管理运行
新版是服务按钮
正常情况会自动出现,如果有异常按以下操作:
1 | 你自己路径:D:\devSoft\JetBrains\IdeaProjects\自己project名\.idea |
2.2、热部署功能
1、添加热部署依赖
1 | <!--热部署--> |
2、父工程pom文件加入插件
1 | <build> |
3、开启自动编译
4、修改注册表内容
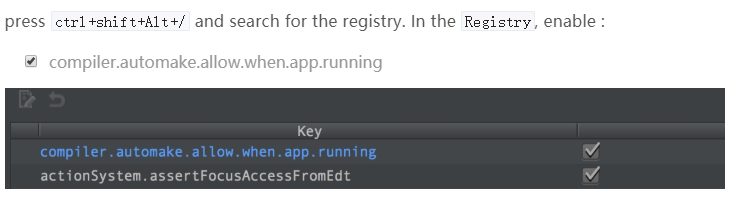
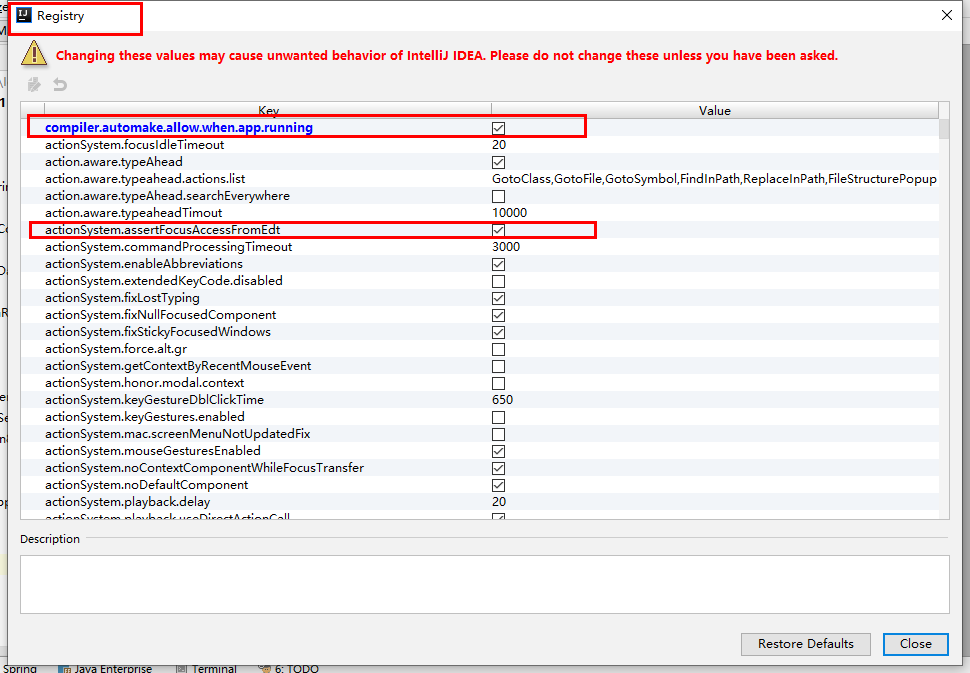
新版idea没有第一项,新的位置如下:
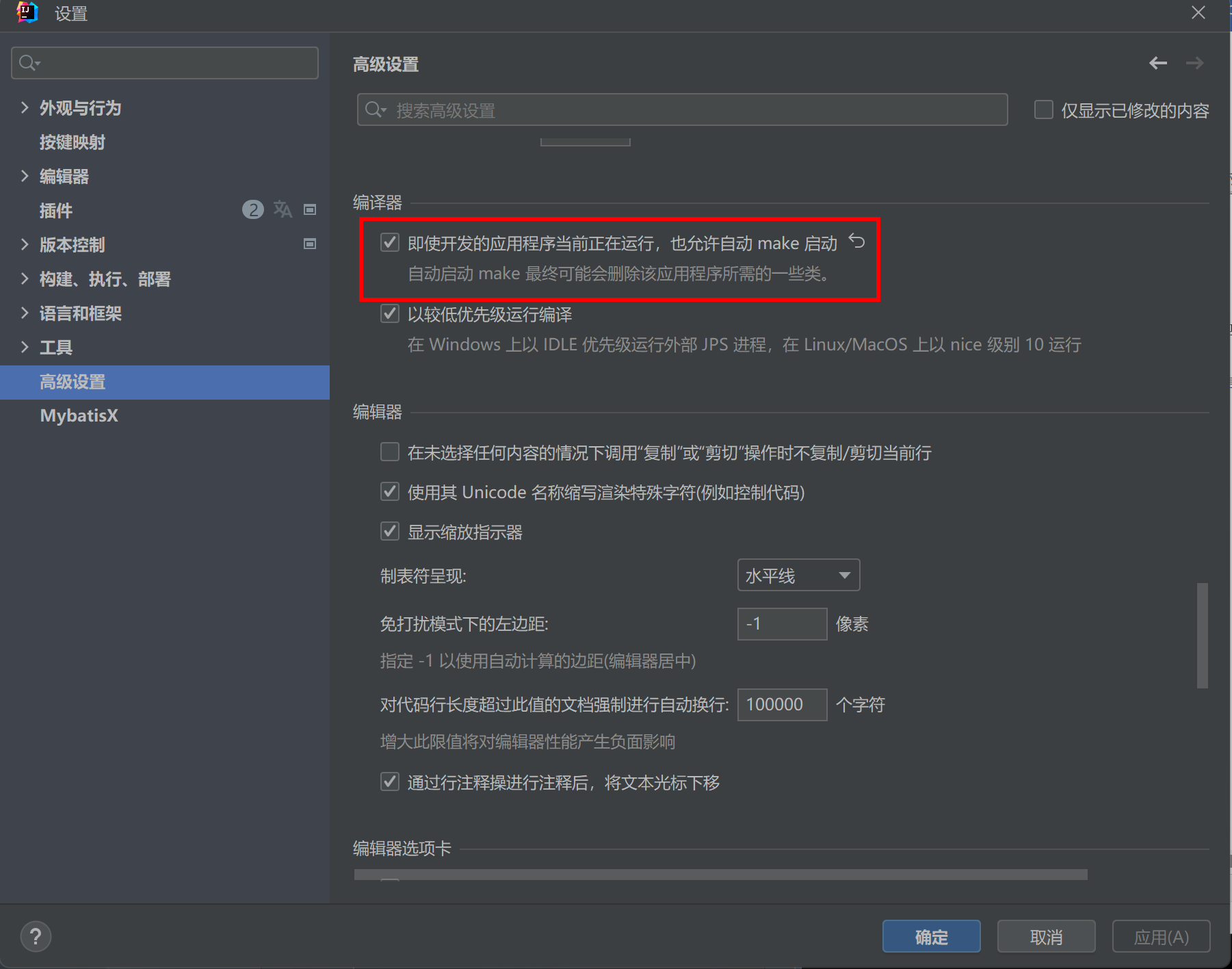
5、重启idea或不重启也可
2.3、cloud-consumer-order80模块
2.3.1、创建maven模块
2.3.2、修改pom文件
1 |
|
2.3.3、编写application.yml
1 | server: |
2.3.4、编写主启动类
1 | package com.lxg.springcloud; |
2.3.5、编写业务类
1、实体类(直接copy)
主体实体类:
1 | package com.lxg.springcloud.entities; |
json封装体
1 | package com.lxg.springcloud.entities; |
什么是RestTemplate?
1 | RestTemplate提供了多种便捷访问远程Http服务的方法, |
config配置类:
1 | package com.lxg.springcloud.config; |
controller类:
1 | package com.lxg.springcloud.controller; |
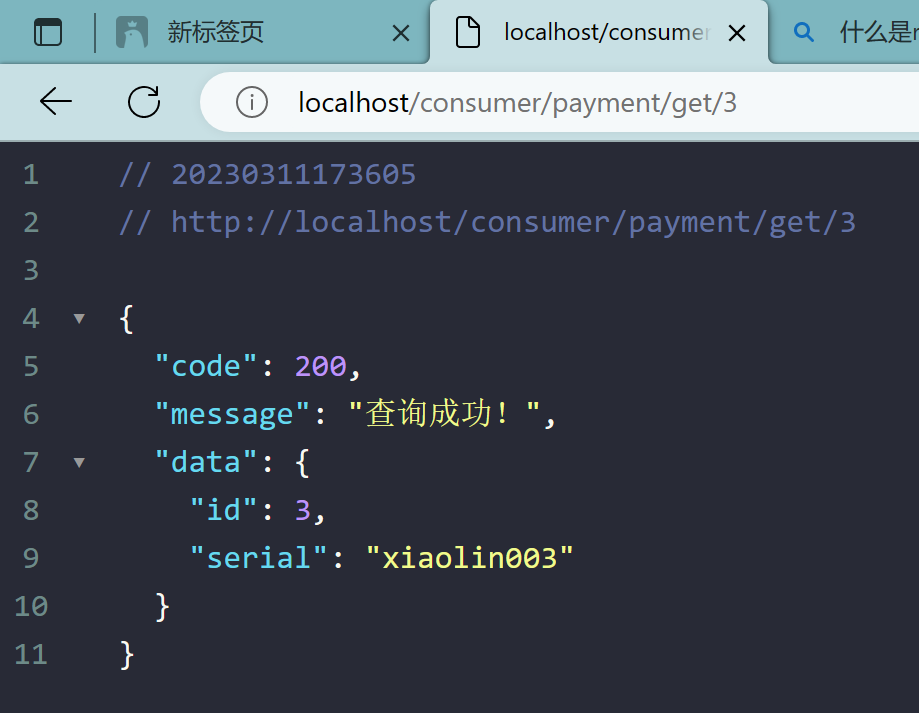
2.3.6、测试
查询:
添加:
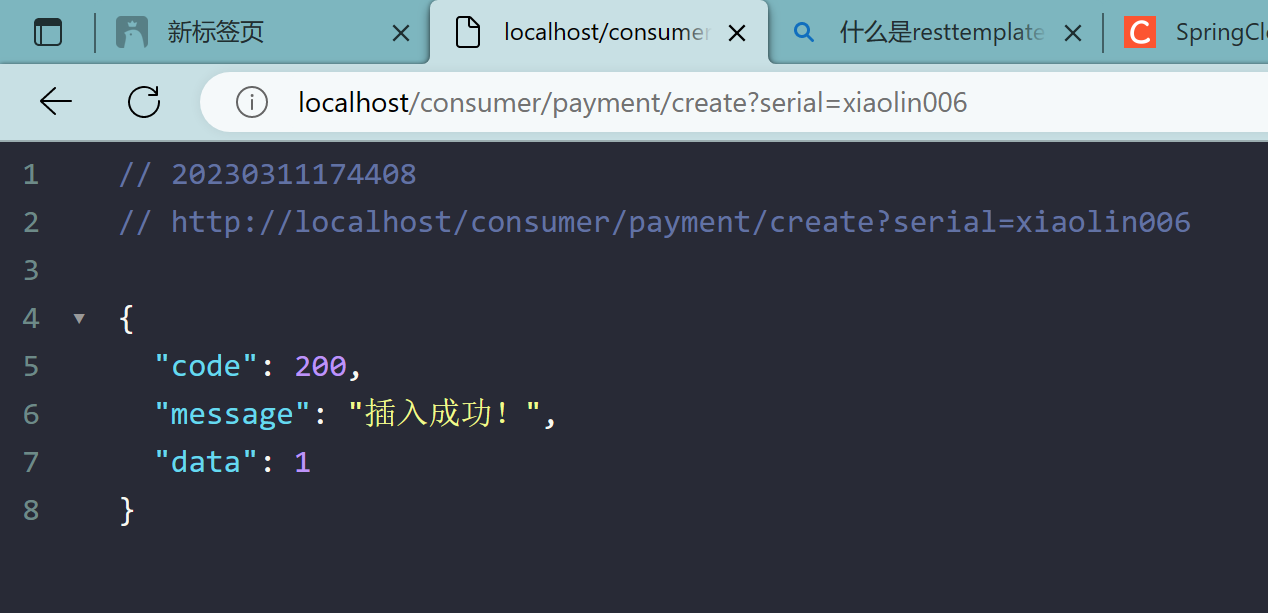
这样添加的serial是null
给之前的PaymentController加上@RequestBody注解
1 |
|
再次尝试:成功!
1 | 后端@RequestBody注解对应的类在将HTTP的输入流(含请求体)装配到目标类(即:@RequestBody后面的类)时,会根据json字符串中的key来匹配对应实体类的属性,如果匹配一致且json中的该key对应的值符合(或可转换为)实体类的对应属性的类型要求时,会调用实体类的setter方法将值赋给该属性。 |

1 | 正常情况下不加@RequestBody,无论是get请求还是post请求都可以自动装配到实体类属性中,但是使用了 |
此时服务端(paymentController)需要传递json格式参数才可以正常插入
修改:
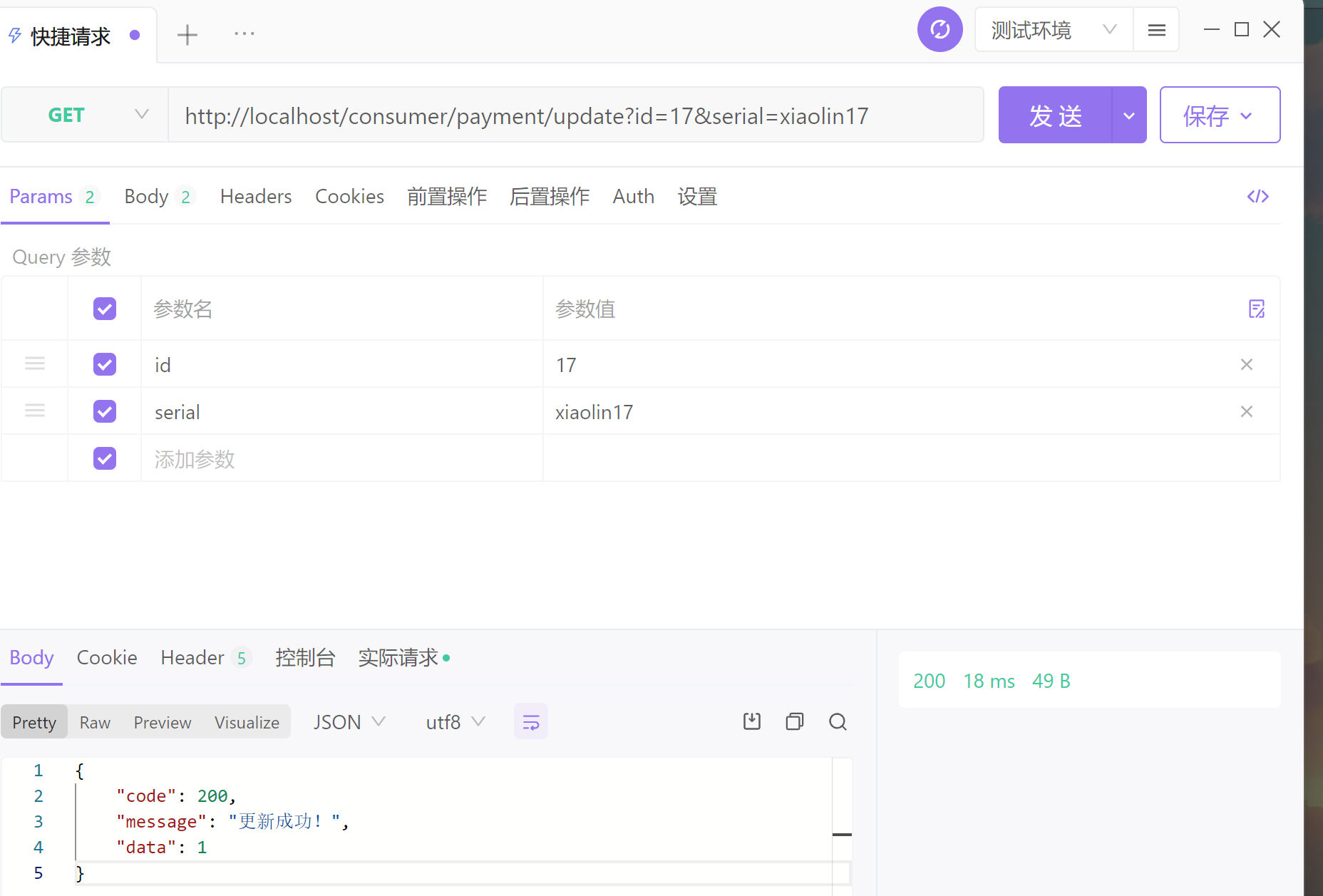
服务端应使用json格式发起请求:
删除:
2.4、工程重构
2.4.1、观察问题
系统中有重复部分,重构
2.4.2、新建cloud-api-commons模块
2.4.3、修改pom文件
1 |
|
2.4.4、把之前两个模块中的实体类复制到该模块中
2.4.5、使用maven命令打包
2.4.6、改造另外两个模块
1、删除原先的实体类
2、在pom文件中新增以下内容
1 | <!-- 引入自己定义的api通用包,可以使用Payment支付Entity --> |
六、Eureka服务注册与发现
1、Eureka基础知识
1.1、什么是服务治理?
1 | 什么是服务治理 |
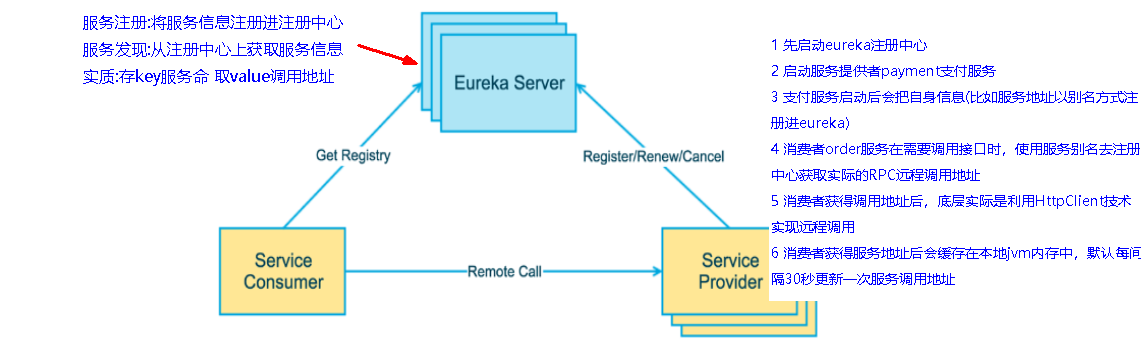
1.2、什么是服务注册?
1 | 什么是服务注册与发现 |
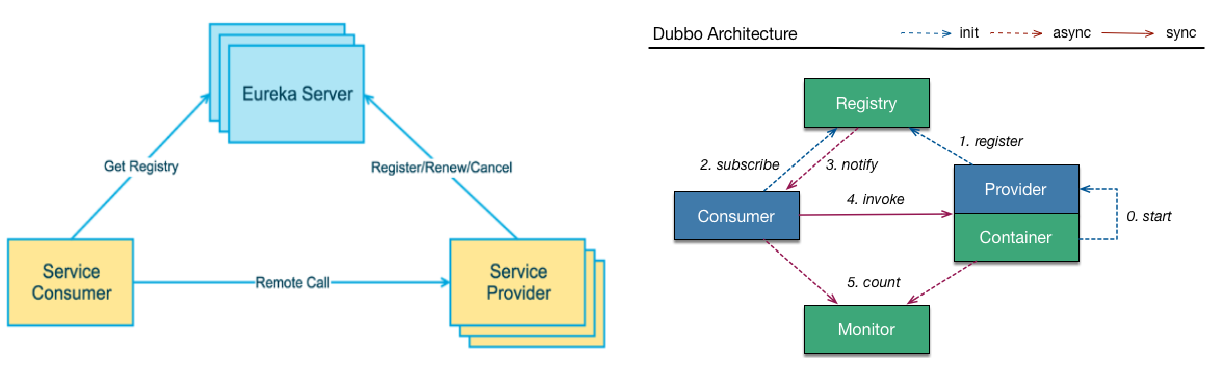
下左图是Eureka系统架构,右图是Dubbo的架构,请对比
1.3、Eureka两个组件
1 | Eureka包含两个组件:Eureka Server和Eureka Client |
2、单机Eureka构建步骤
2.1、IDEA生成eurekaServer端服务注册中心(类似物业公司)
2.1.1、创建新模块 cloud-eureka-server7001
2.1.2、修改pom文件
1 |
|
2.1.3、编写application.yml文件
1 | server: |
2.1.4、编写主启动类
1 | package com.lxg.springcloud; |
2.1.5、测试
此时 No application available 没有服务被发现 O(∩_∩)O
因为没有注册服务进来当然不可能有服务被发现
2.2、EurekaClient端cloud-provider-payment8001
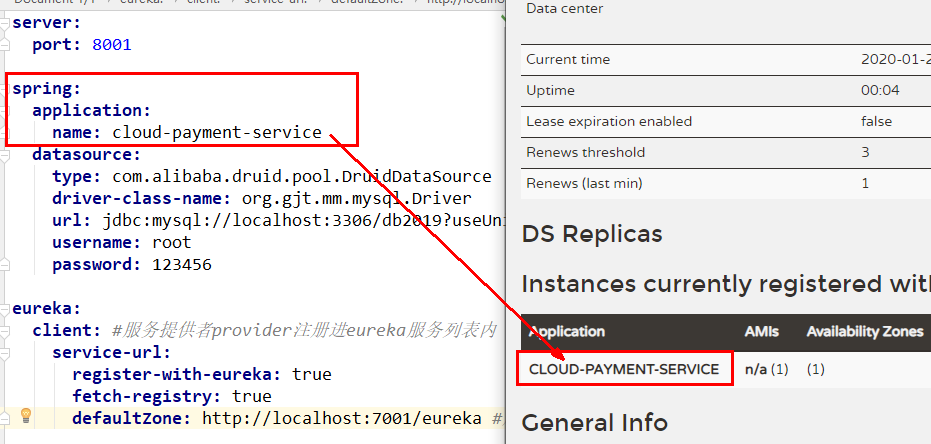
将注册进EurekaServer
成为服务提供者provider,类似尚硅谷学校对外提供授课服务
2.2.1、修改cloud-provider-payment8001模块pom文件
添加依赖
1 | <!--eureka-client--> |
2.2.2、编写yml,新增以下内容
1 | eureka: |
2.2.3、在主启动类上添加@EnableEurekaClient注解
2.2.4、测试
注意要先启动EurekaServer端
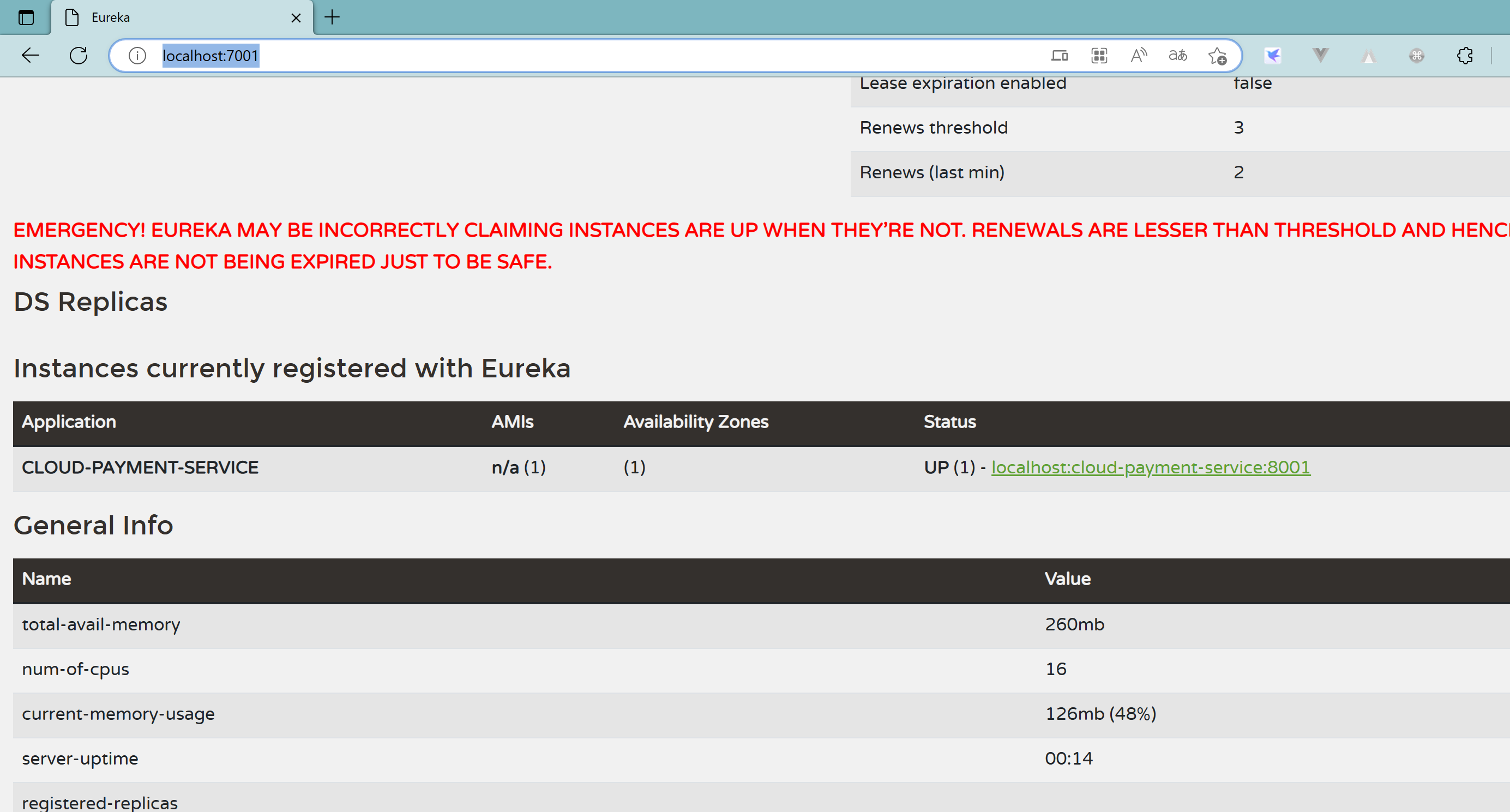
服务名配置:
2.2.5、自我保护机制
2.3、EurekaClient端cloud-consumer-order80将注册进EurekaServer
成为服务消费者consumer,类似来尚硅谷上课消费的各位同学
2.3.1、修改cloud-consumer-order80模块pom文件
添加内容:
1 | <dependency> |
2.3.2、编写yml,新增以下内容
1 | spring: |
2.3.3、在主启动类上添加@EnableEurekaClient注解
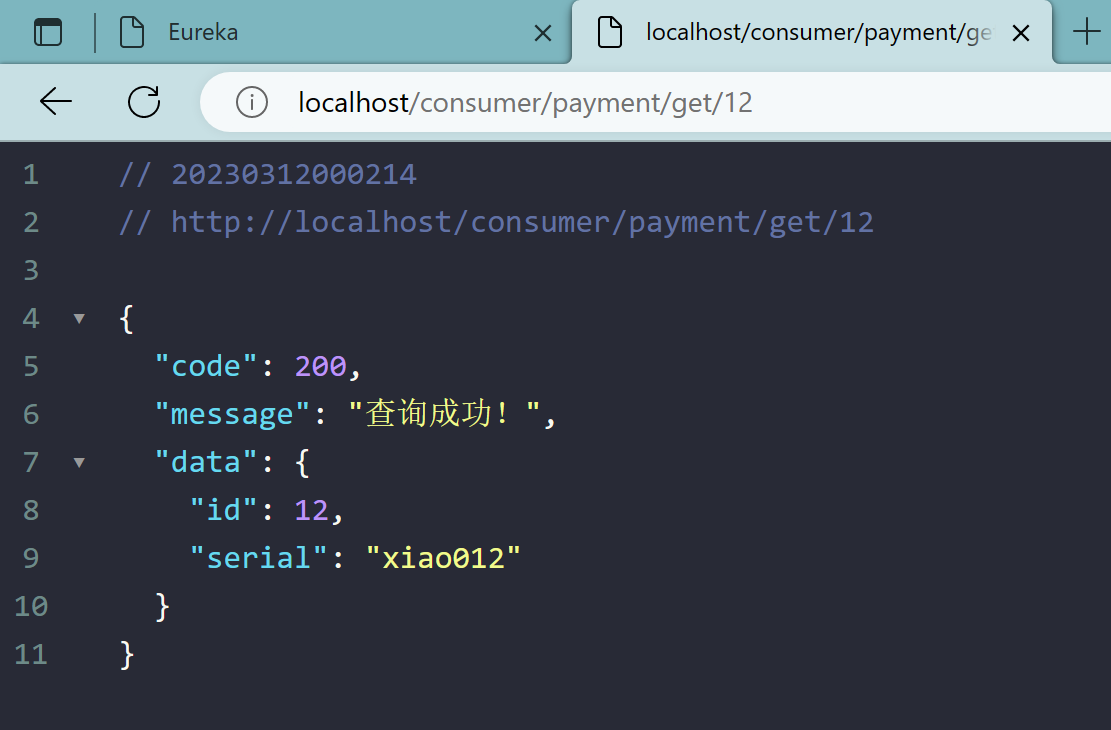
2.3.4、测试
注意:先启动EurekaServer端,再启动其他端
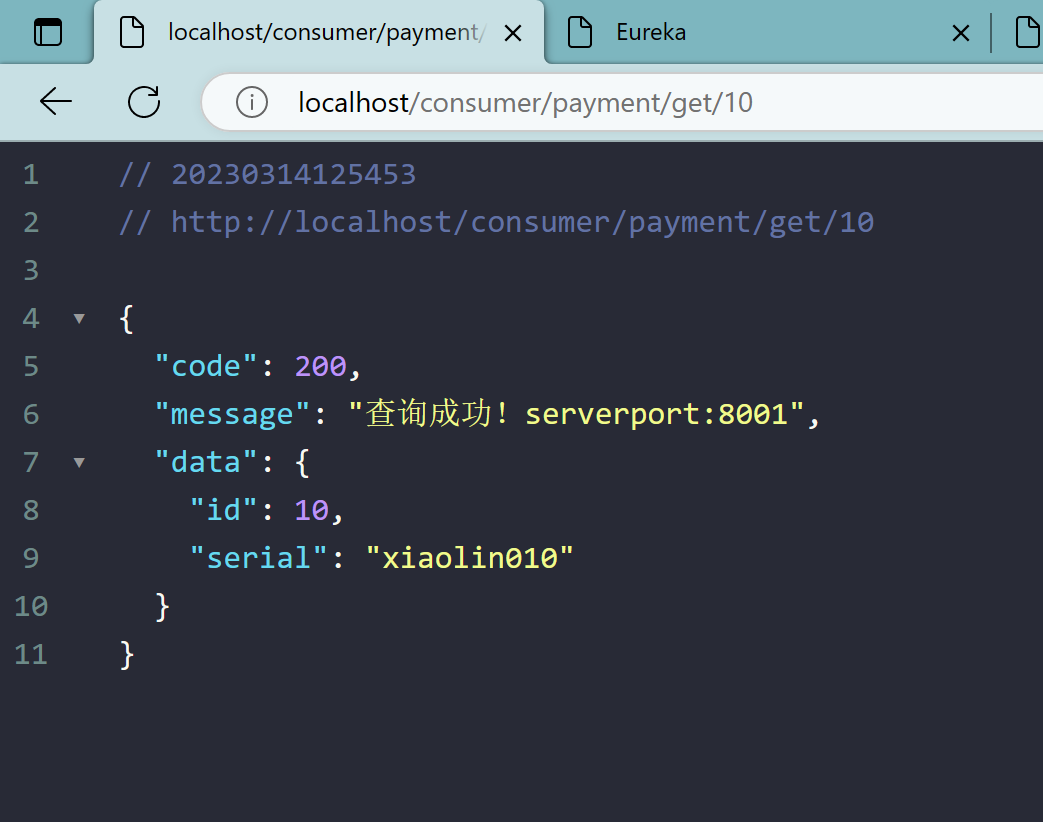
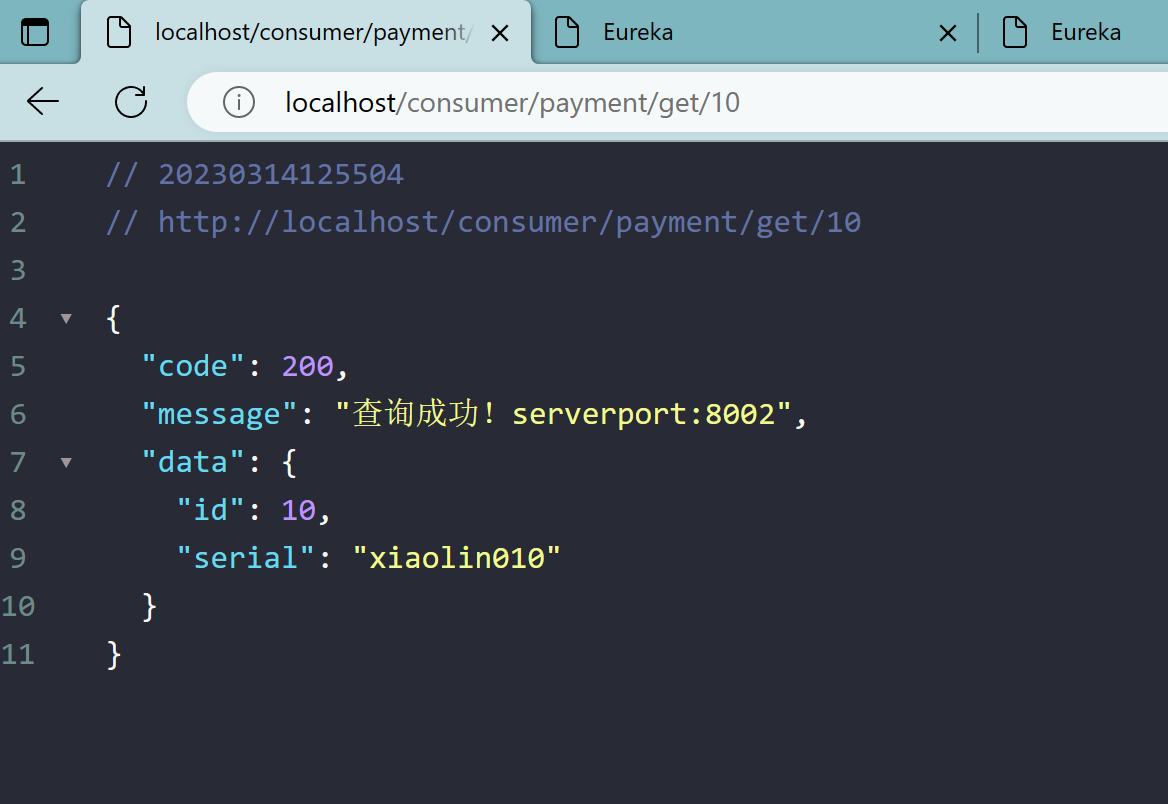
localhost/consumer/payment/get/12
3、集群Eureka构建
3.1、Eureka集群原理说明
1 | 问题:微服务RPC远程服务调用最核心的是什么 |
3.2、集群搭建步骤
3.2.1、参考7001新建7002模块
3.2.2、修改7002的pom文件
1 |
|
3.2.3、修改映射配置
C:\Windows\System32\drivers\etc\hosts
1 | 127.0.0.1 eureka7001.com |
3.2.4、修改7001和7002的yml配置文件
7001:
1 | server: |
7002:
1 | server: |
两者互相注册,相互守望
3.2.5、编写7002启动类
1 | package com.lxg.springcloud; |
3.2.6、测试
3.3、将8001服务发布到2台Eureka集群上
修改yml文件
1 | server: |
3.4、将80服务发布到2台Eureka集群上
修改yml文件
1 | server: |
3.5、测试
先启动7001,7002,2台Eureka集群
再启动提供者8001,再启动消费者80
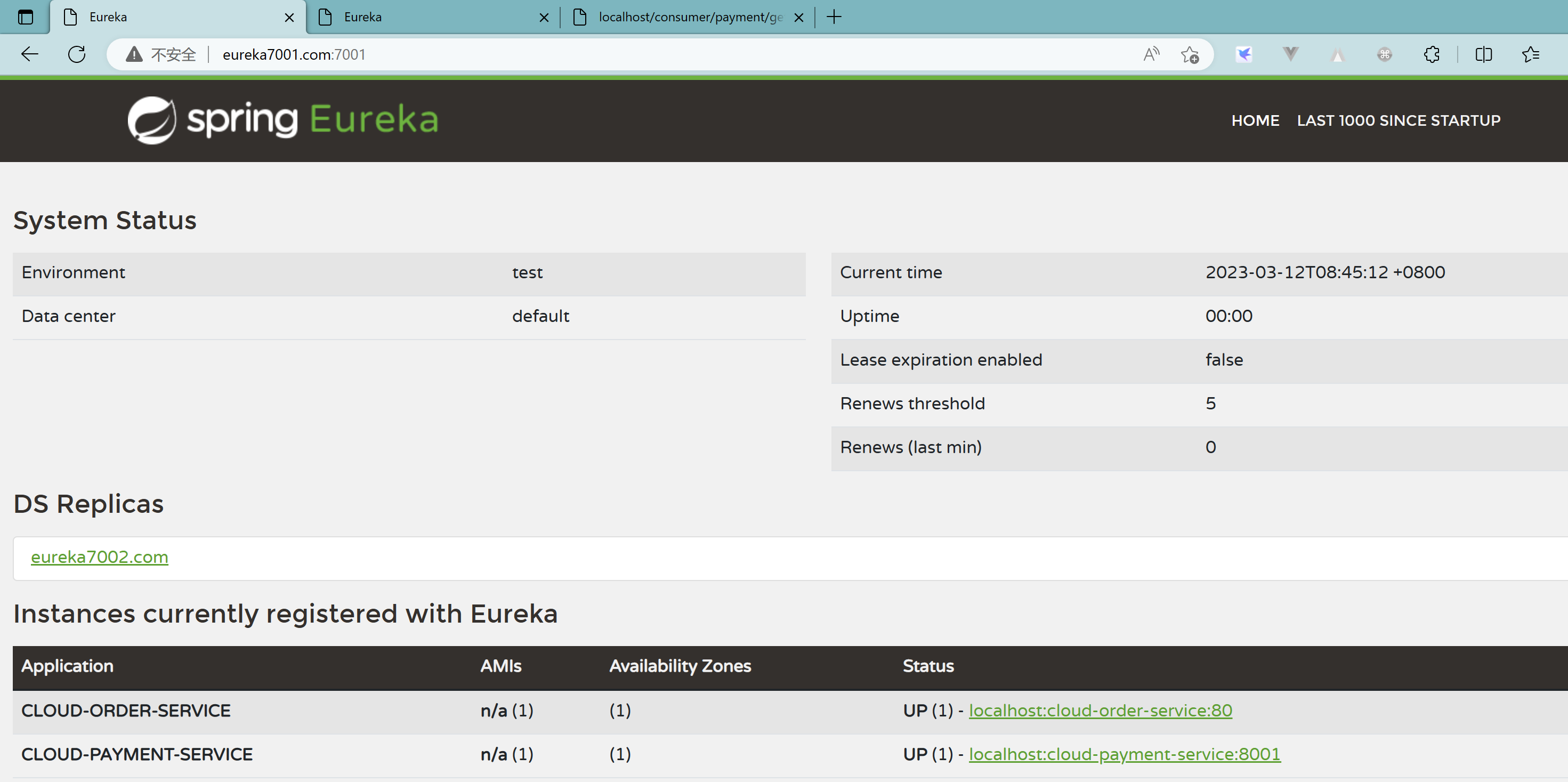
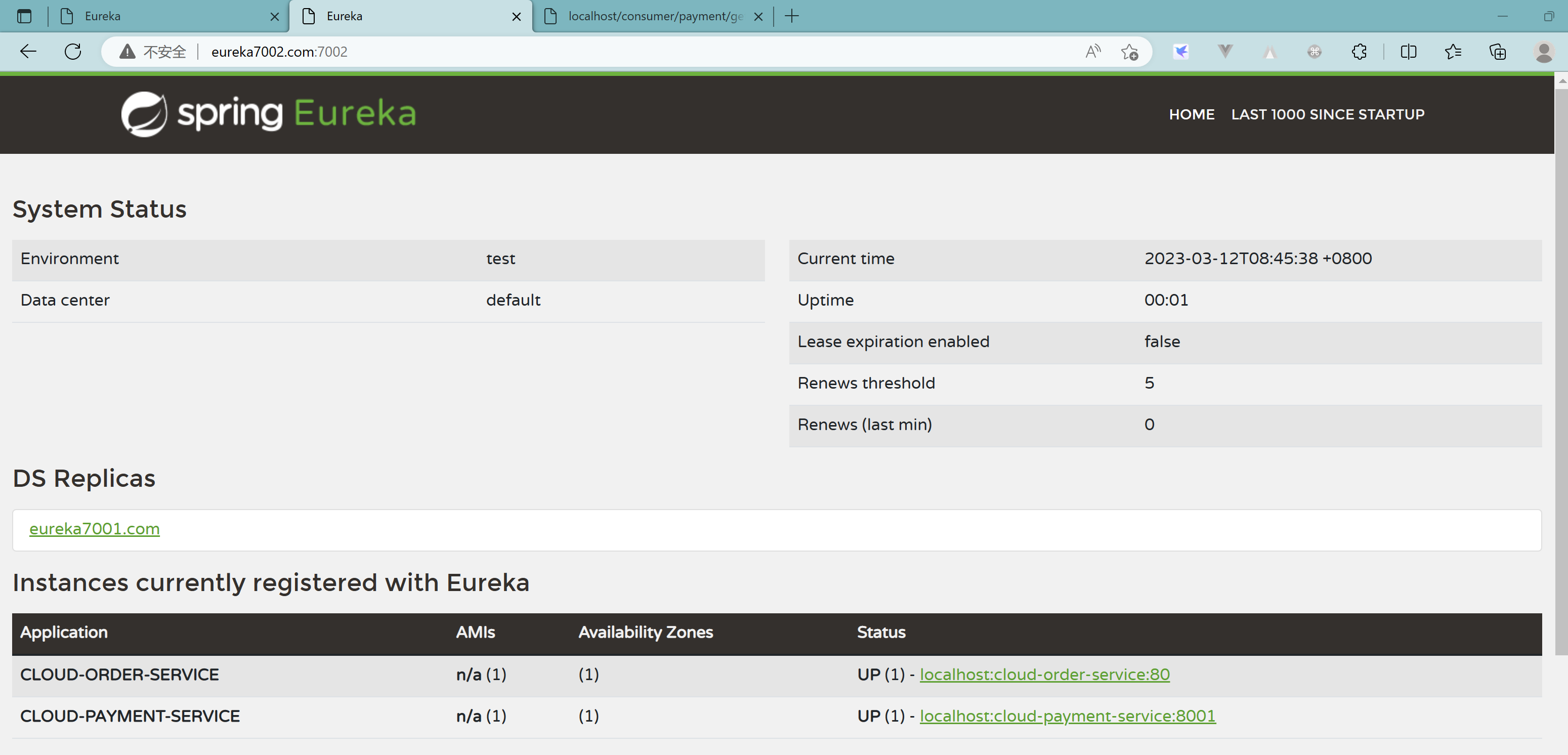
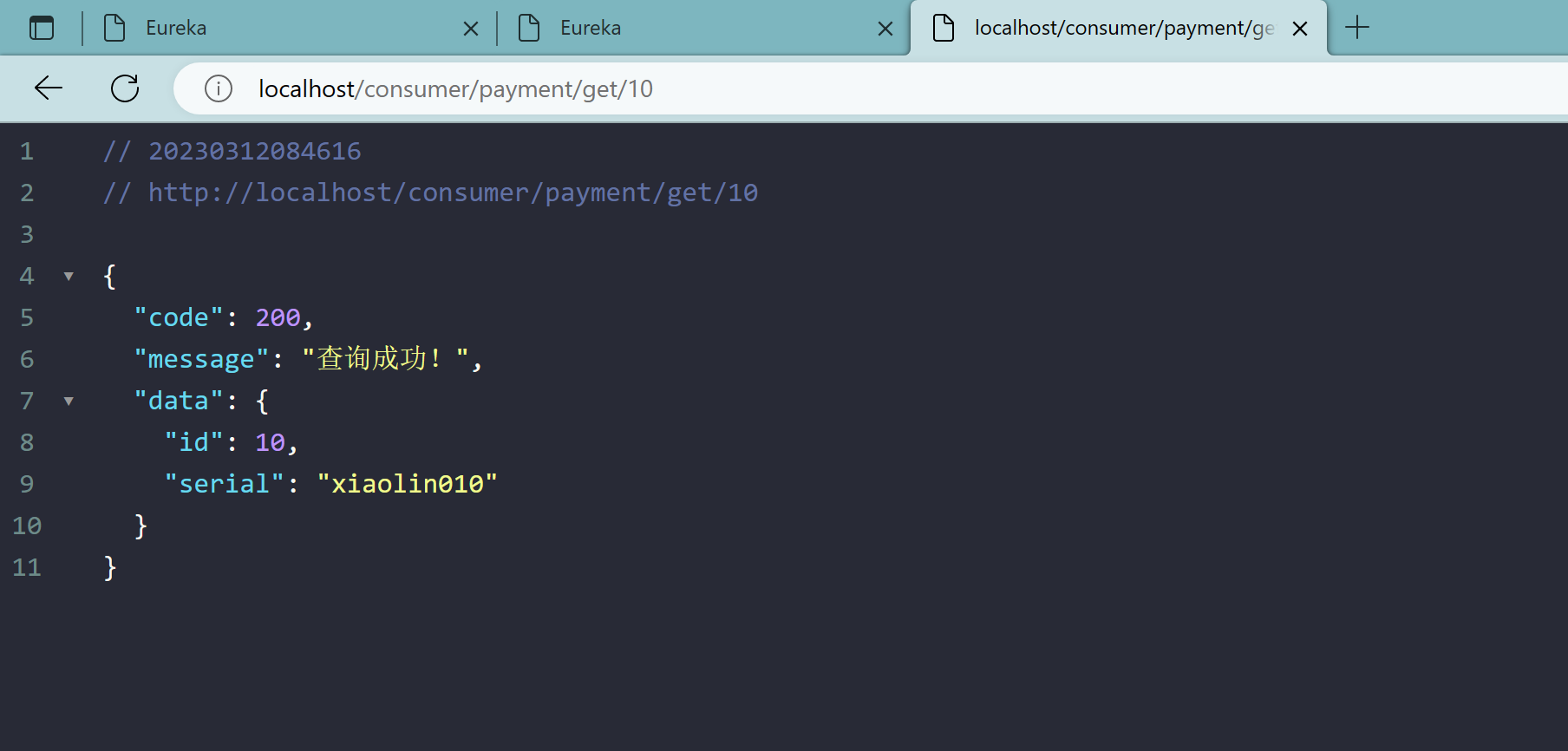
3.6、支付提供者8001集群搭建
3.6.1、新建8002支付提供者模块cloud-provider-payment8002
3.6.2、修改8002pom文件
1 |
|
3.6.3、编写8002yml文件
1 | server: |
3.6.4、编写主启动类
1 | package com.lxg.springcloud; |
3.6.5、业务类直接从8001copy
3.6.6、修改8001和8002的Controller
8001:
1 | package com.lxg.springcloud.controller; |
8002:
1 | package com.lxg.springcloud.controller; |
3.7、负载均衡
3.7.1、bug
1 | 以上配置完,去访问会报错,无法访问到服务,因为它不知道选择8001还是8002 |
修改80模块controller
1 | //public static final String PAYMENT_URL = "http://localhost:8001"; |
3.7.2、使用注解解决bug
@LoadBalanced注解赋予RestTemplate负载均衡的能力
将注解加在80模块的RestTemplate配置类上
依赖于Ribbon的负载均衡功能
3.8、测试2
先启动EurekaServer集群7001/7002
再启动服务提供者集群8001/8002
再启动消费者80
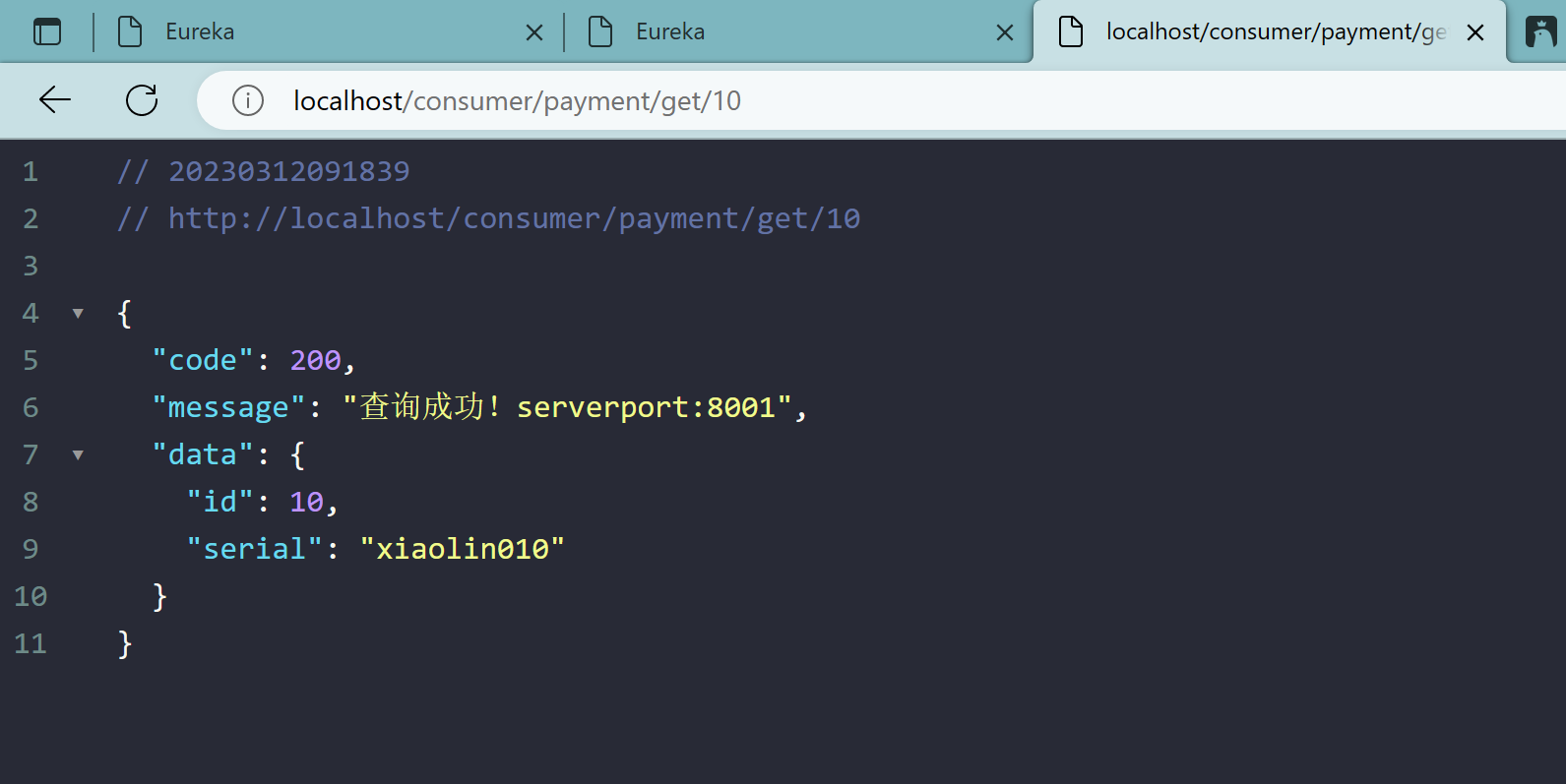
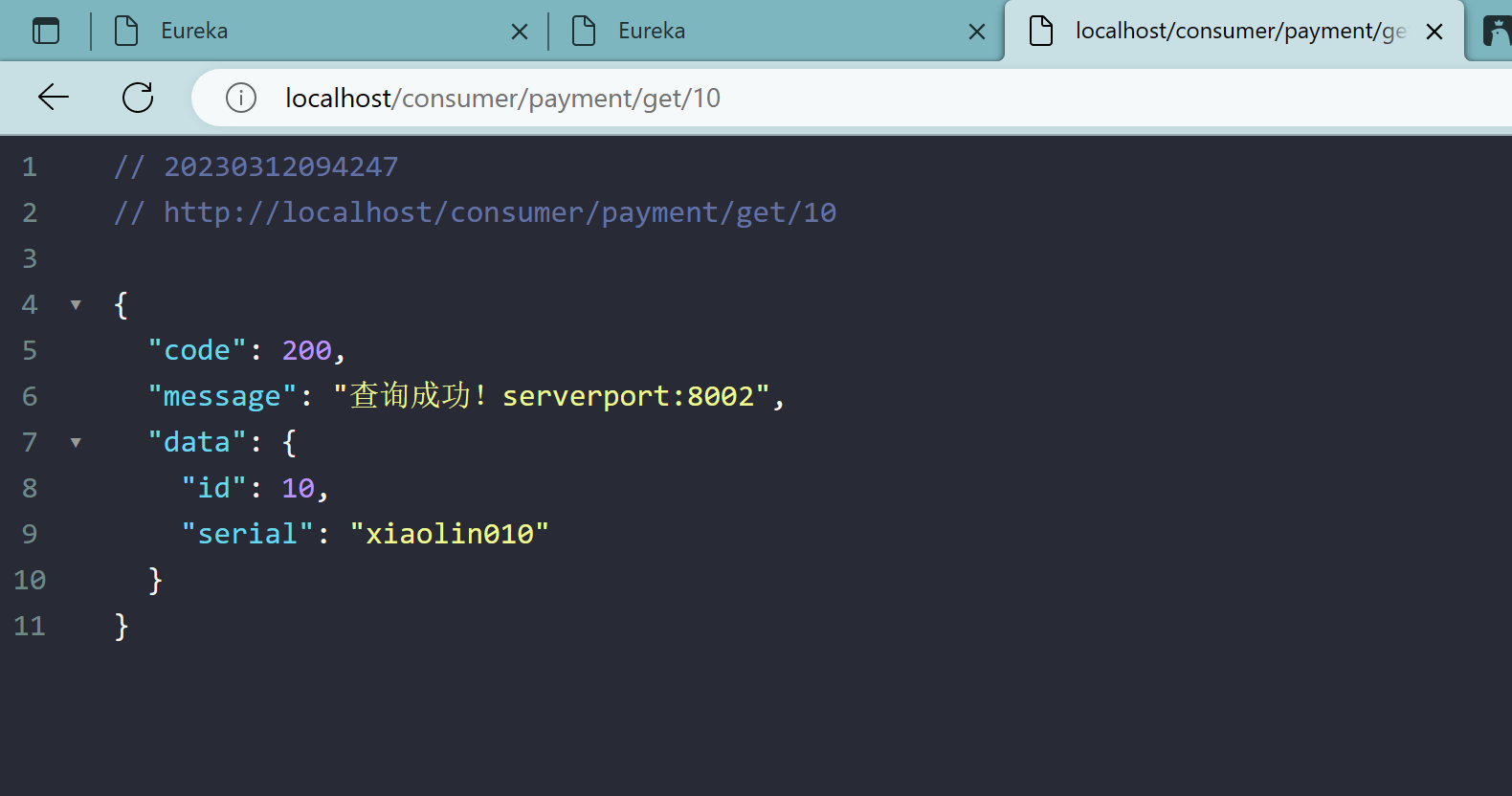
负载均衡效果达到,8001/8002端口交替出现
Ribbon和Eureka整合后Consumer可以直接调用服务而不用再关心地址和端口号,且该服务还有负载功能了。O(∩_∩)O
4、actuator微服务信息完善
4.1、主机名称:服务名称修改
当前问题
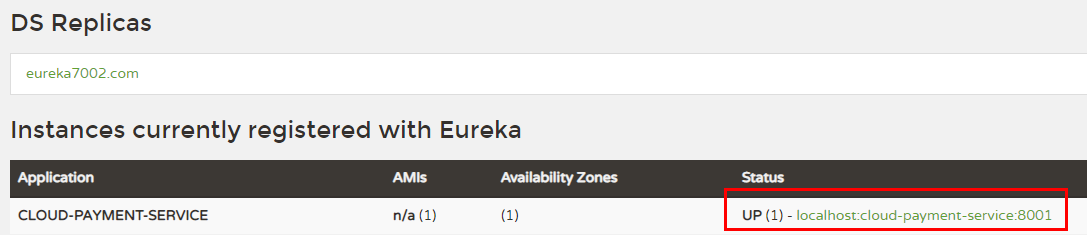
含有主机名称
修改8001、8002的yml文件:
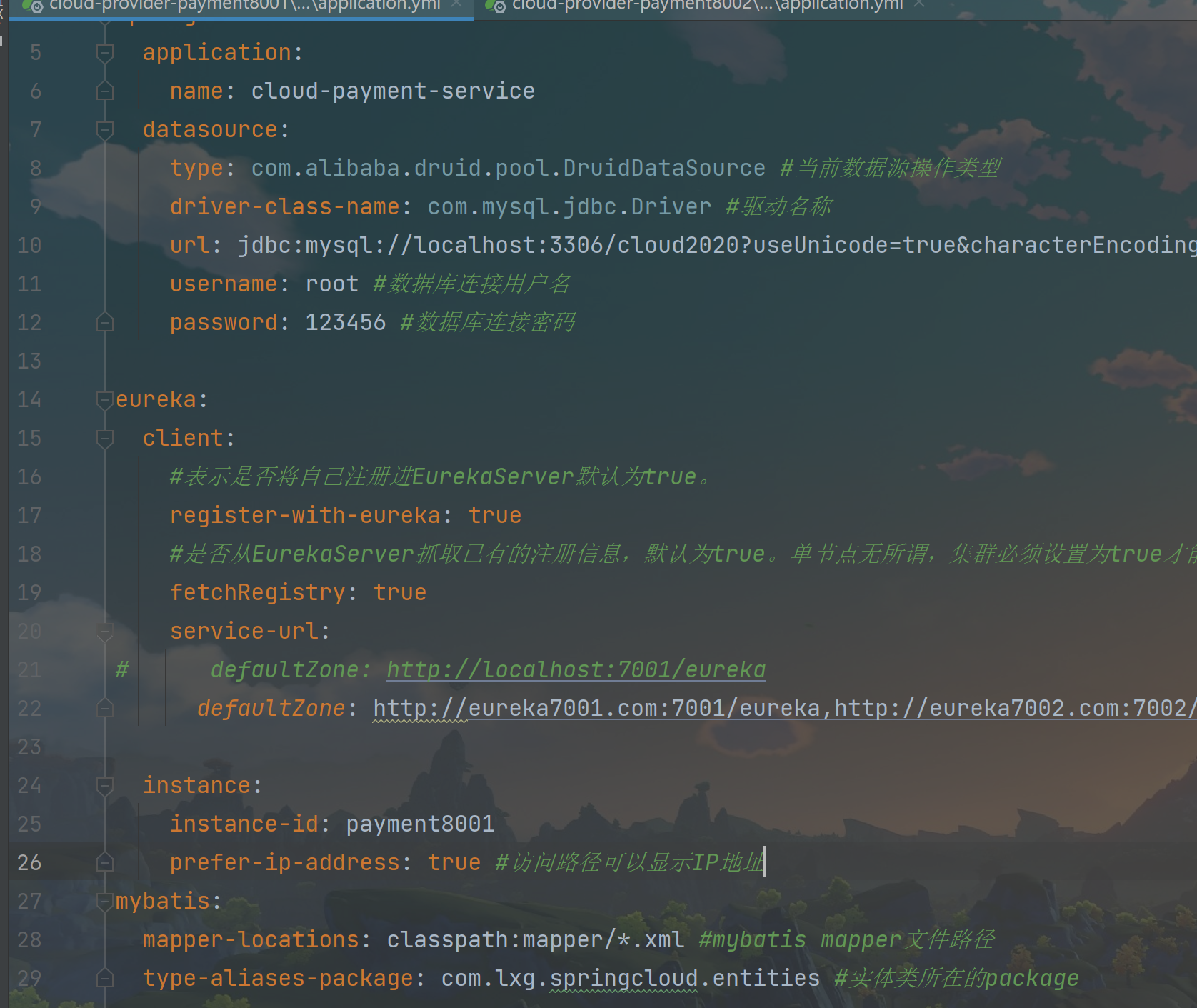
1 | instance: |
1 | instance: |
修改之后:

4.2、访问信息有ip信息显示
当前问题:
没有ip提示
修改8001、8002yml文件:
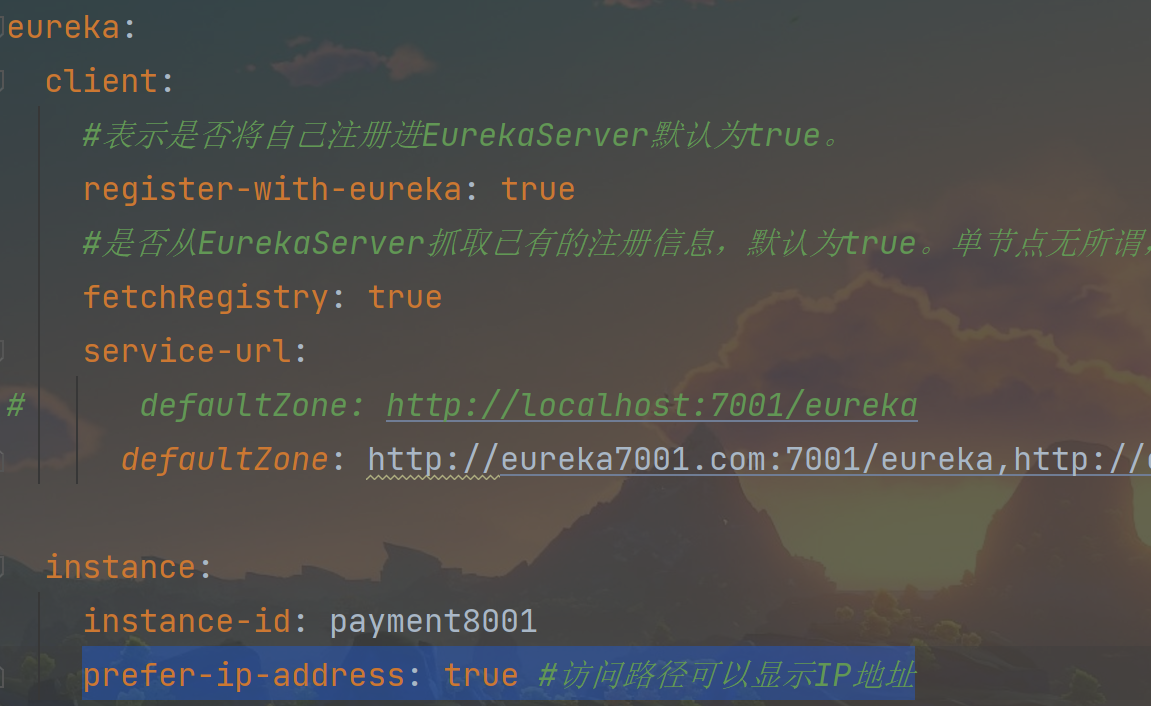
1 | prefer-ip-address: true #访问路径可以显示IP地址 |
修改之后:
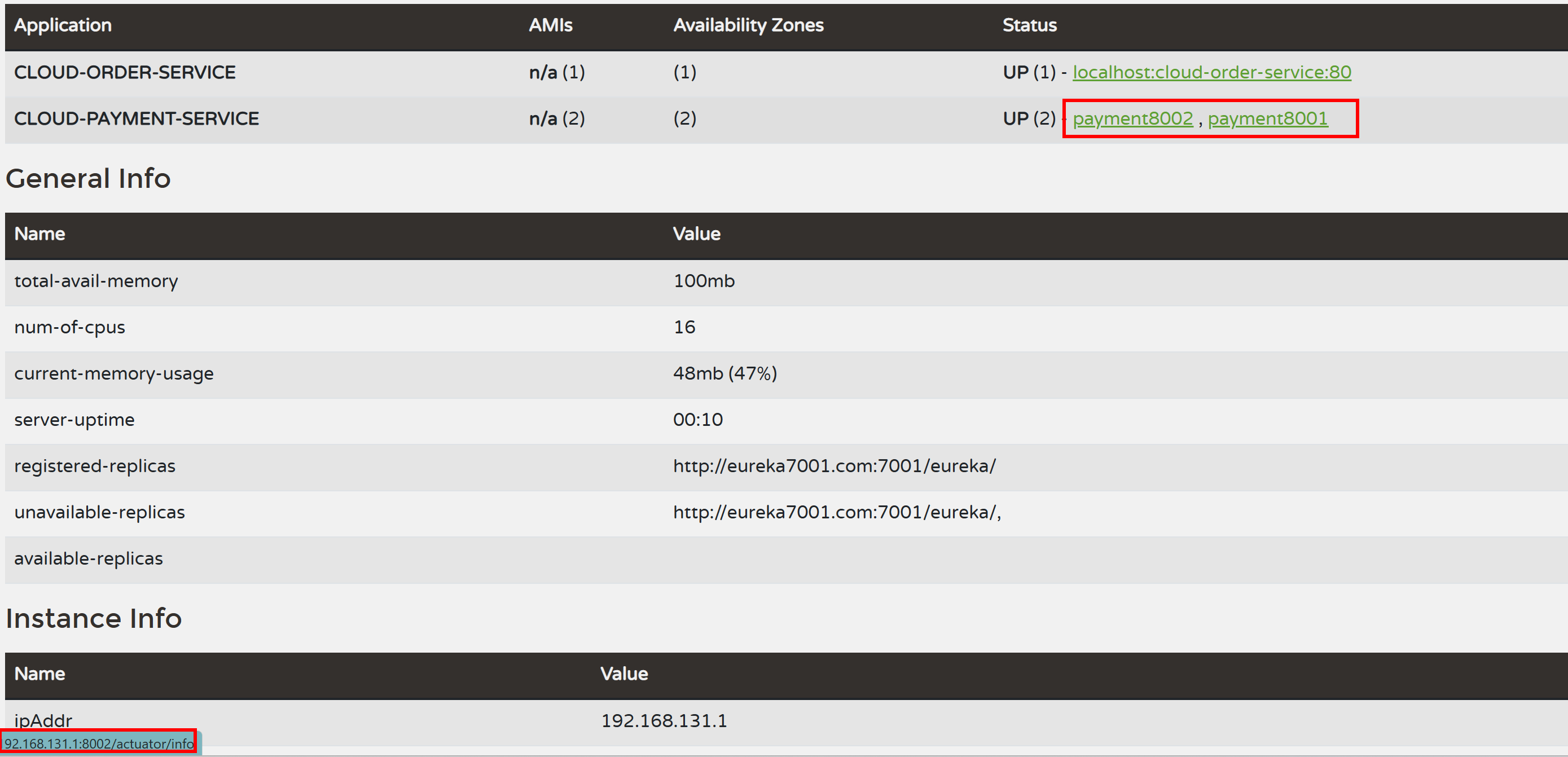
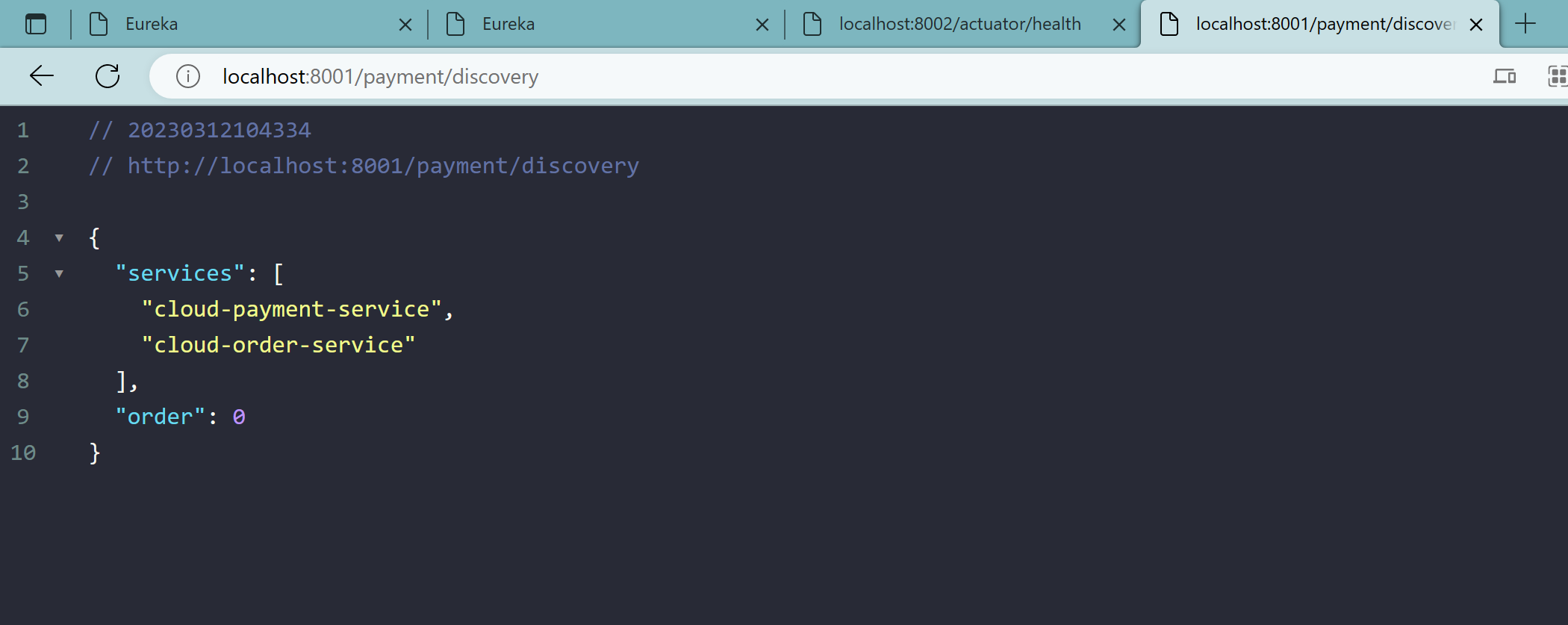
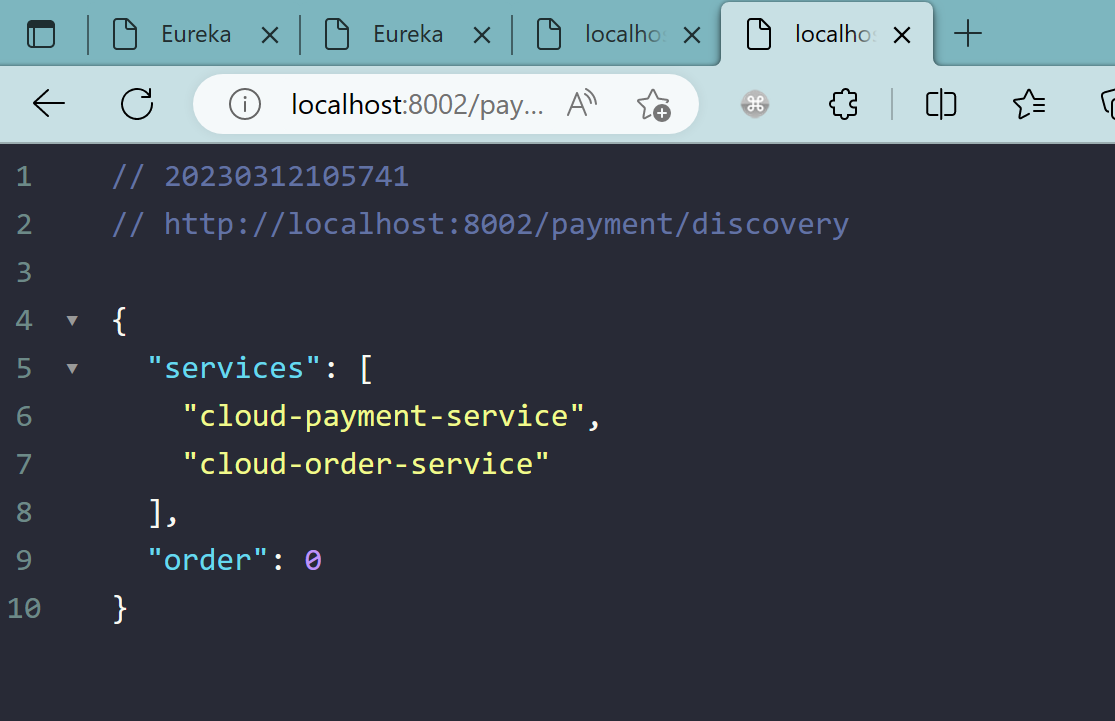
5、服务发现Discovery
5.1、对于注册进eureka里面的微服务,可以通过服务发现来获得该服务的信息
5.2、修改8001、8002的controller
添加以下内容:
1 |
|
5.3、修改8001、8002主启动类
在启动类上添加@EnableDiscoveryClient注解
5.4、自测
注意:
先启动EurekaServer
再启动8001、8002
6、Eureka自我保护
6.1、故障现象
概述
保护模式主要用于一组客户端和Eureka Server之间存在网络分区场景下的保护。一旦进入保护模式,
Eureka Server将会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据,也就是不会注销任何微服务。
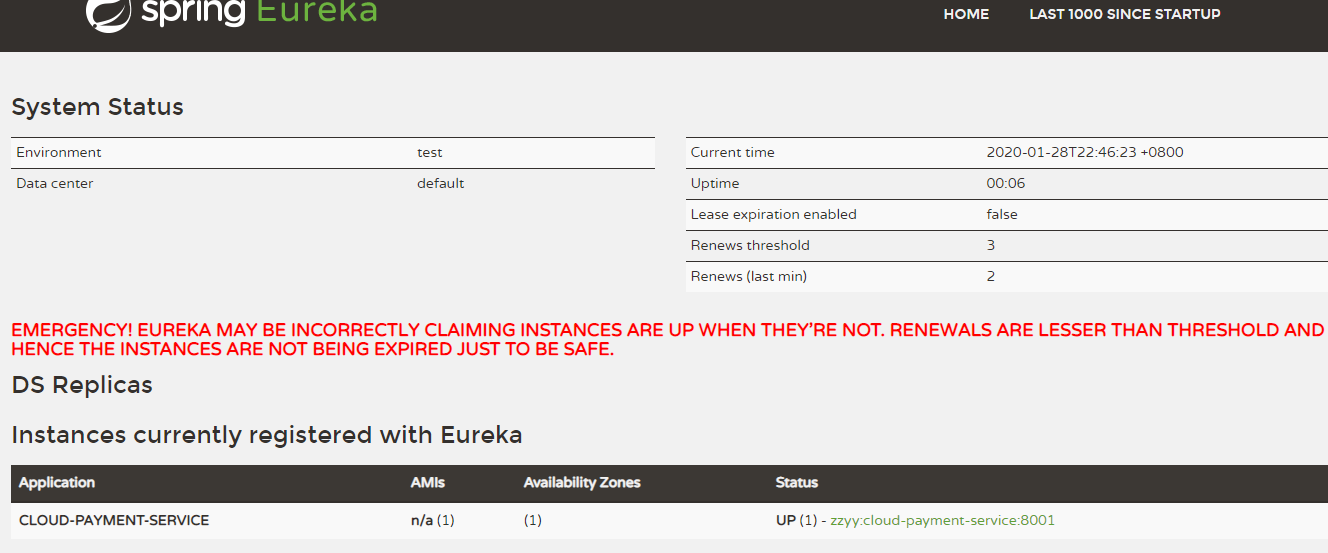
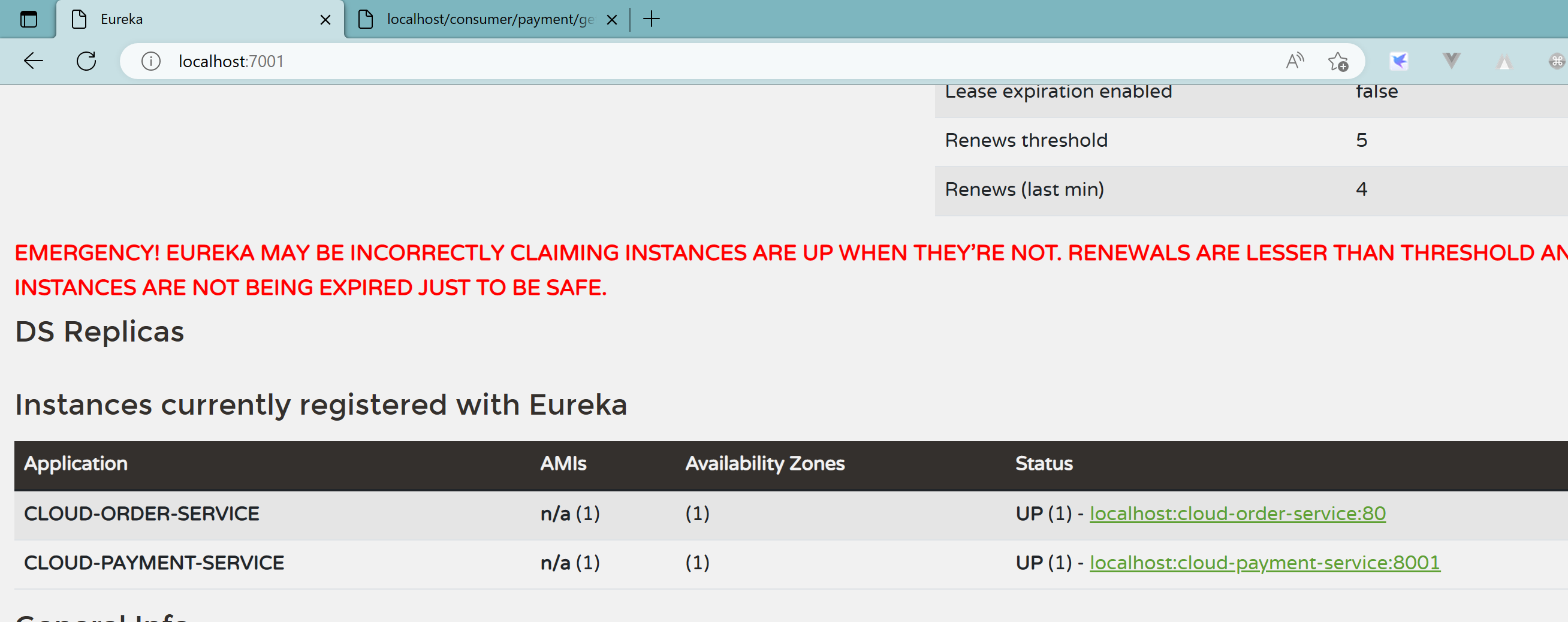
如果在Eureka Server的首页看到以下这段提示,则说明Eureka进入了保护模式:
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE
6.2、原因
1 | 为什么会产生Eureka自我保护机制? |

在自我保护模式中,Eureka Server会保护服务注册表中的信息,不再注销任何服务实例。它的设计哲学就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例。一句话讲解:好死不如赖活着
综上,自我保护模式是一种应对网络异常的安全保护措施。它的架构哲学是宁可同时保留所有微服务(健康的微服务和不健康的微服务都会保留)也不盲目注销任何健康的微服务。使用自我保护模式,可以让Eureka集群更加的健壮、稳定。
一句话:某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存
属于CAP里面的AP分支
6.3、怎么禁止自我保护
6.3.1、注册中心EurekaServer7001、7002配置
1、默认保护模式是开启的
1 | eureka.server.enable-self-preservation=true |
2、使用eureka.server.enable-self-preservation = false 可以禁用自我保护模式
1 | server: |
3、关闭效果

6.3.2、生产者客户端eureakeClient端8001配置
1、默认
1 | eureka.instance.lease-renewal-interval-in-seconds=30 |
2、配置
1 | #心跳检测与续约时间 |
3、测试
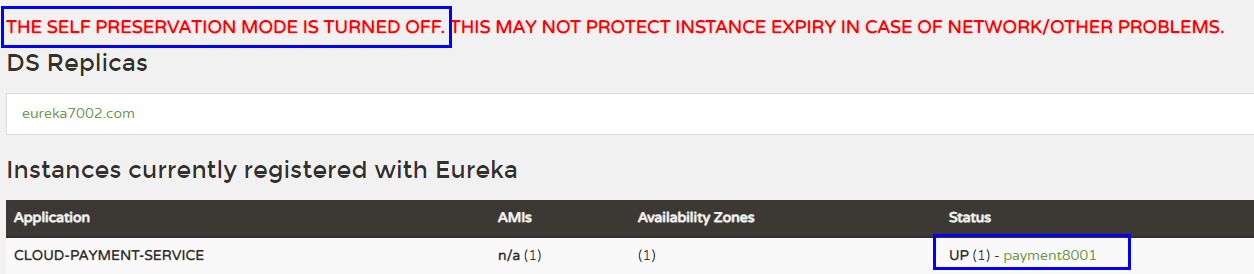
关闭8001/8002,服务立马被剔除
注意如果通过idea直接关闭,无论是否开启都会被剔除
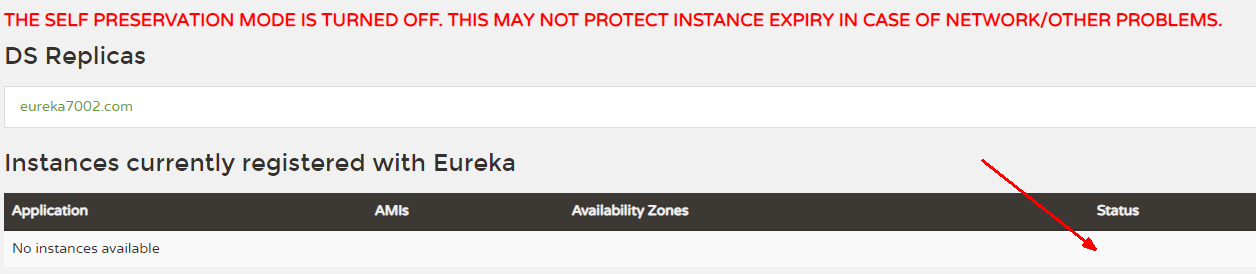
正确测试方法:
用命令查询所有端口:netstat -ano
再用 :taskkill /pid pid号 /f 强行关闭这个端口
七、Zookeeper服务注册与发现
1、Eureka停止更新了你怎么办
https://github.com/Netflix/eureka/wiki
找其他替代
2、SpringCloud整合Zookeeper替代Eureka
2.1、安装注册中心zookeeper
zookeeper是一个分布式协调工具,可以实现注册中心功能
关闭Linux服务器防火墙后启动zookeeper服务器
zookeeper服务器取代Eureka服务器,zk作为服务注册中心
使用版本:3.6.4(3.4.9版本一直报错)
2.2、服务提供者
2.2.1、新建cloud-provider-payment8004模块
同样可以多构建一个8005模块做集群配置
2.2.2、修改pom文件
1 |
|
2.2.3、编写yml文件
1 | #8004表示注册到zookeeper服务器的支付服务提供者端口号 |
需要注册到几台zookeeper中,加,后面继续写即可
2.3.4、编写主启动类
1 | package com.lxg.springcloud; |
2.3.5、编写Controller
1 | package com.lxg.springcloud.controller; |
2.3.6、启动8004进行注册
启动报错:
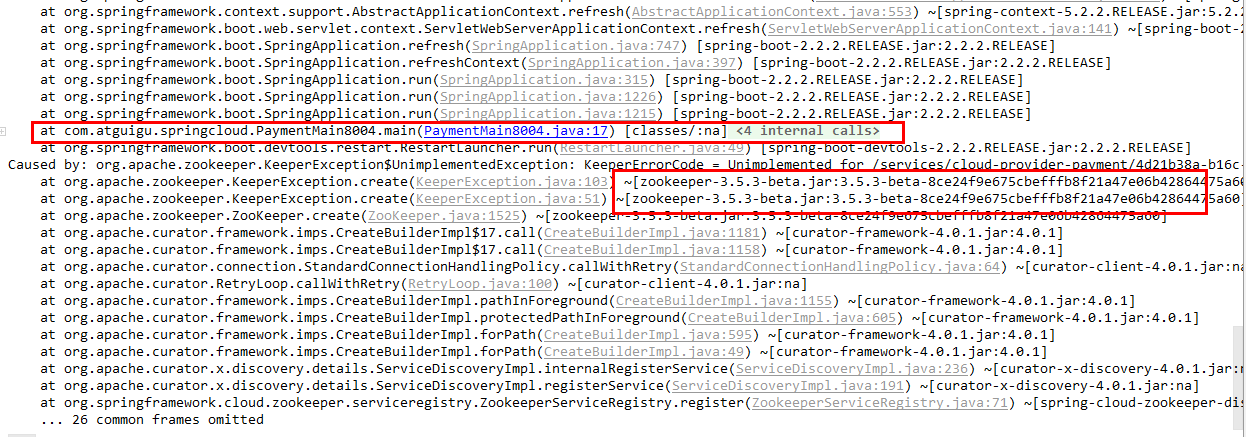
原因:zookeeper版本jar包冲突问题
注意:根据zookeeper版本不同可能还会有其他版本依赖错误问题,自行判断解决
解决:
新版pom文件
1 |
|
2.3.7、测试

2.3.8、测试2

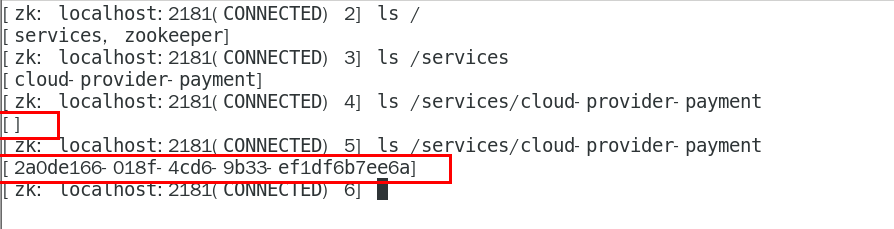
2.3.9、思考
服务节点是临时节点还是持久节点
答案:临时
2.3、服务消费者
2.3.1、新建cloud-consumerzk-order80模块
2.3.2、修改pom文件
1 |
|
2.3.3、编写yml文件
1 | server: |
2.3.4、编写主启动类
1 | package com.lxg.springcloud; |
2.3.5、编写业务类
1、配置Bean(RestTemplate)
1 | package com.lxg.springcloud.config; |
2、编写Controller
1 | package com.lxg.springcloud.controller; |
2.3.6、测试


会在8004、8005之间切换
八、Consul服务注册与发现
1、Consul简介
1.1、是什么?
What is Consul? | Consul | HashiCorp Developer
1 | Consul 是一套开源的分布式服务发现和配置管理系统,由 HashiCorp 公司用 Go 语言开发。 |
1.2、能干嘛
Spring Cloud Consul 具有如下特性:

- 服务发现:提供HTTP和DNS两种发现方式。
- 健康监测:支持多种方式,HTTP、TCP、Docker、Shell脚本定制化监控
- KV存储:Key、Value的存储方式
- 多数据中心:Consul支持多数据中心
- 可视化Web界面
1.3、去哪下载
Install | Consul | HashiCorp Developer
1.4、怎么玩
Spring Cloud Consul 中文文档 参考手册 中文版
2、安装并运行Consul
2.1、官网安装说明:
Install Consul | Consul | HashiCorp Developer
2.2、下载完成后只有一个consul.exe文件
2.3、使用开发模式启动
命令:consul agent -dev
通过以下地址可以访问Consul的首页:http://localhost:8500
3、服务提供者
3.1、新建Module支付服务provider8006:cloud-providerconsul-payment8006
3.2、修改pom文件
1 | <dependencies> |
3.3、编写yml文件
1 | server: |
3.4、编写主启动类
1 | package com.lxg.springcloud; |
3.5、编写业务类controller
1 | package com.lxg.springcloud.controller; |
3.6、测试
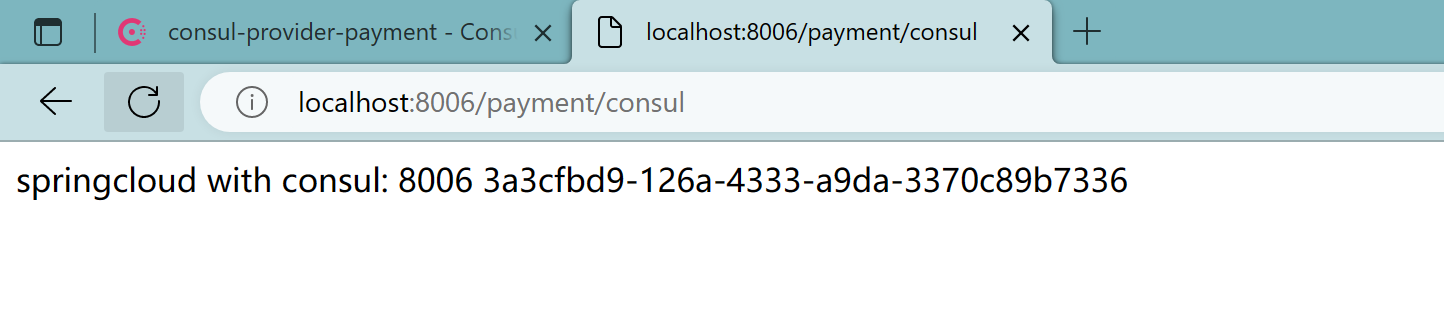
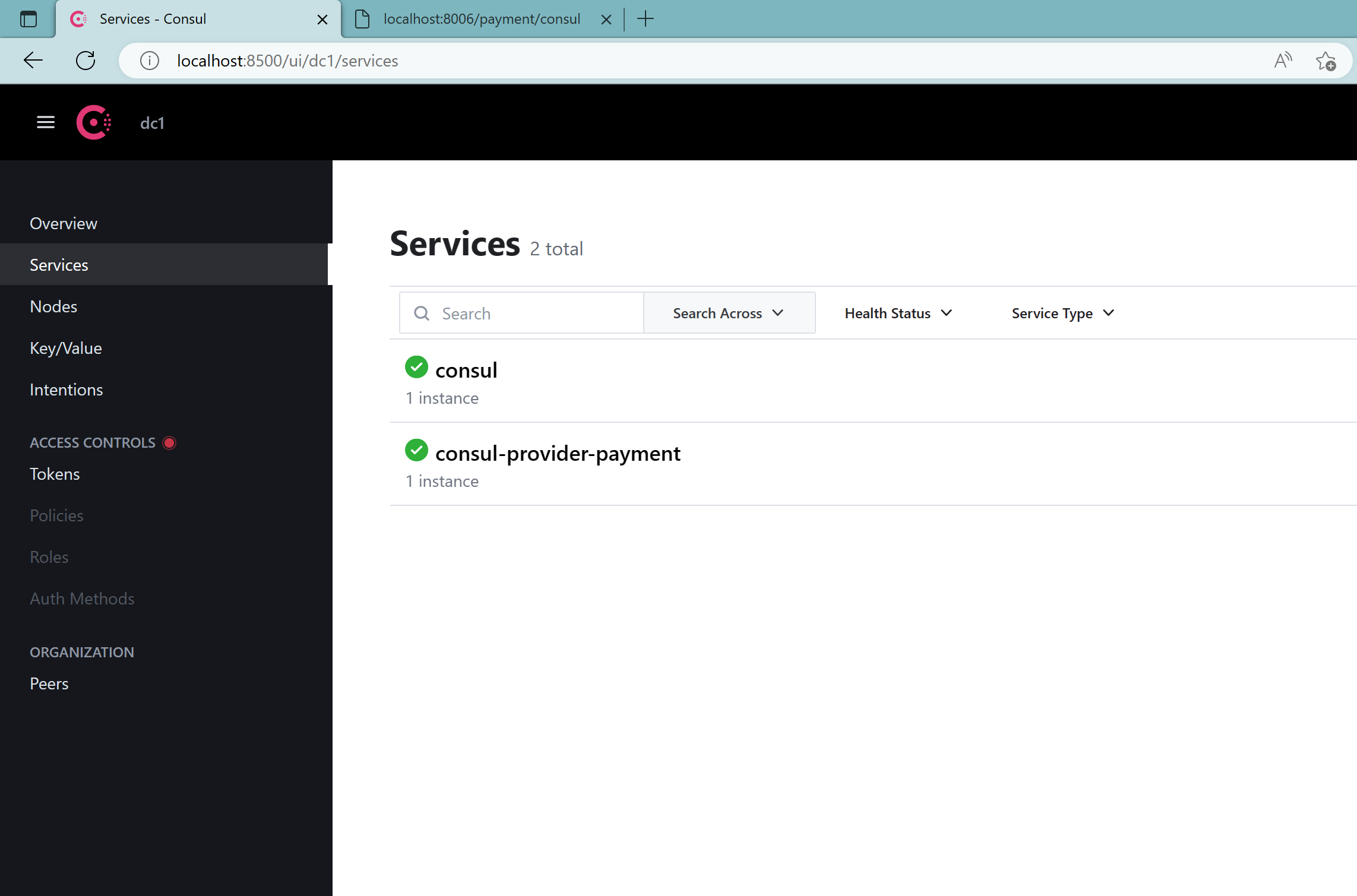
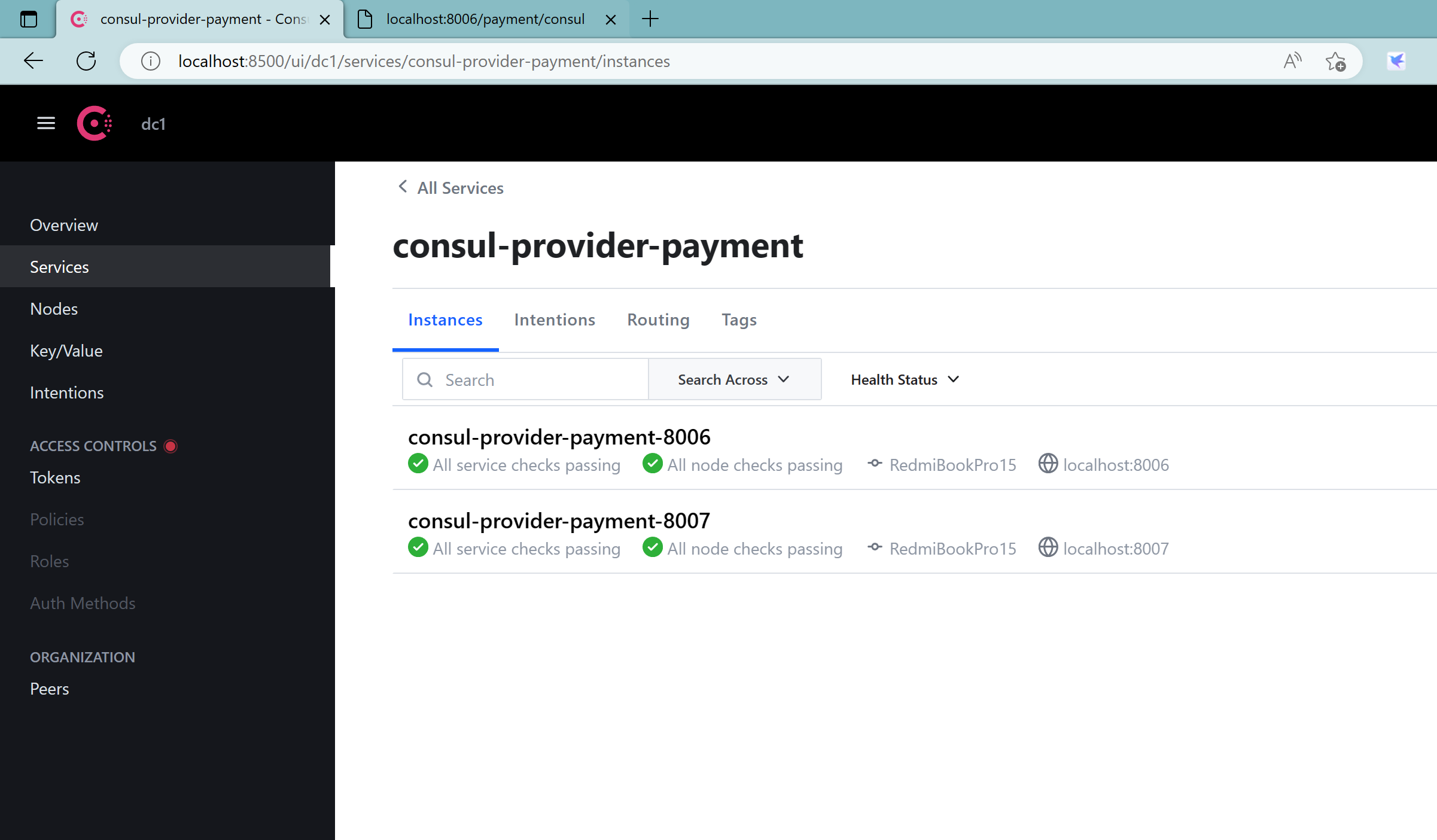
根据以前,同样可以创建多一个8007服务者构成集群
4、服务消费者
4.1、新建cloud-consumerconsul-order80模块
4.2、修改pom文件
1 |
|
4.3、编写yml文件
1 | server: |
4.4、编写主启动类
1 | package com.lxg.springcloud; |
4.5、编写配置bean
1 | package com.lxg.springcloud.config; |
4.6、编写controller
1 | package com.lxg.springcloud.controller; |
4.7、测试
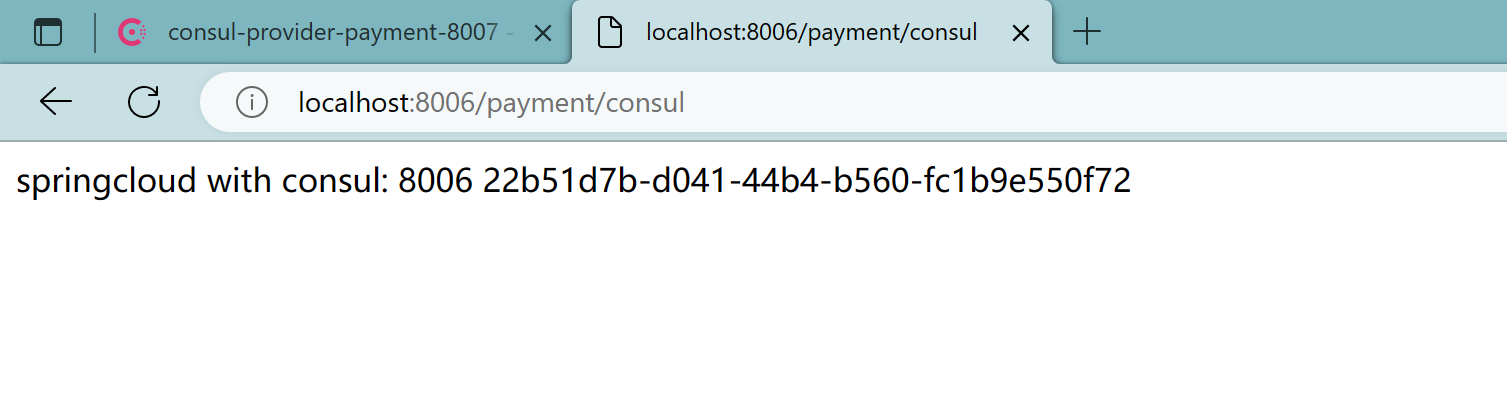
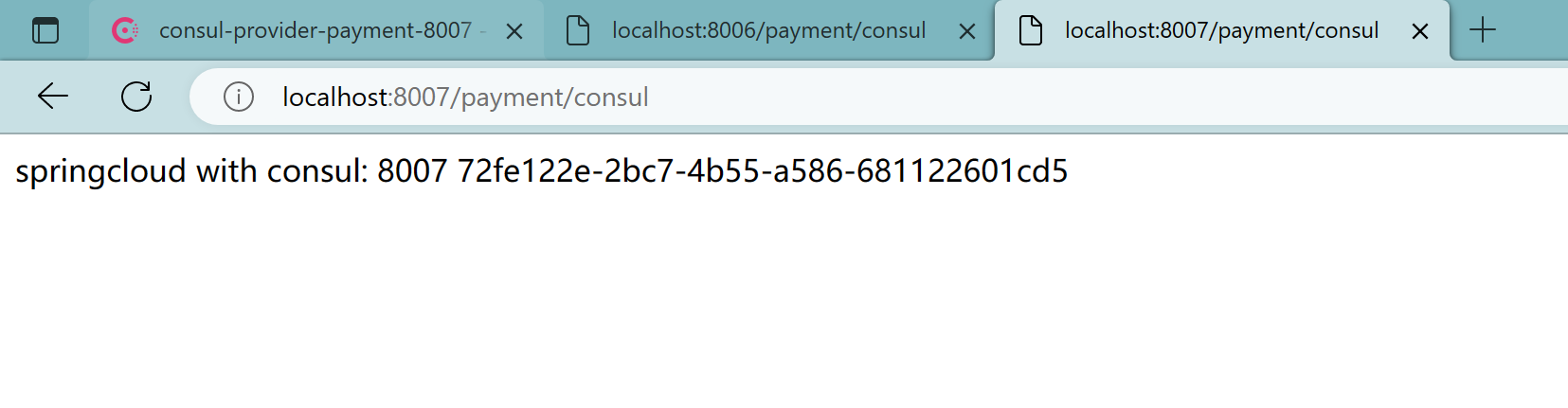


会在8006、8007切换
5、三个注册中心异同点
| 组件名 | 语言 | CAP | 服务健康检查 | 对外暴露接口 | SpringCloud集成 |
|---|---|---|---|---|---|
| Eureka | Java | AP | 可配支持 | HTTP | 已集成 |
| Consul | Go | CP | 支持 | HTTP/DNS | 已集成 |
| Zookeeper | Java | CP | 支持 | 客户端 | 已集成 |
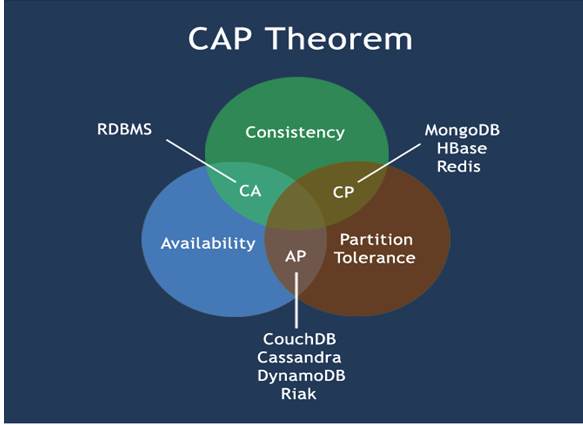
5.1、CAP
1 | C:Consistency(强一致性) |
5.2、经典CAP图
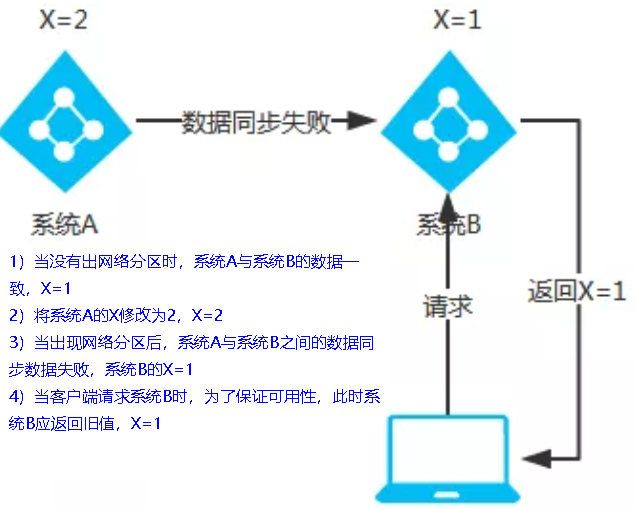
AP架构(Eureka)
当网络分区出现后,为了保证可用性,系统B可以返回旧值,保证系统的可用性。
结论:违背了一致性C的要求,只满足可用性和分区容错,即AP
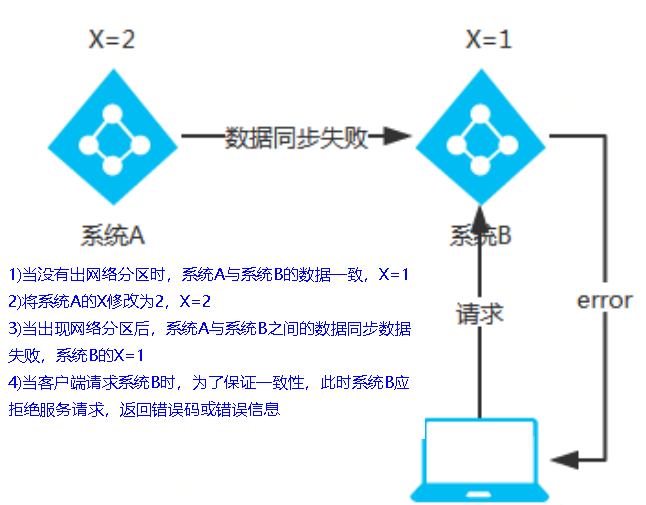
CP架构(consul、zookeeper)
当网络分区出现后,为了保证一致性,就必须拒接请求,否则无法保证一致性
结论:违背了可用性A的要求,只满足一致性和分区容错,即CP
九、Ribbon负载均衡服务调用
1、概述
1.1、是什么?
1 | Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端 负载均衡的工具。 |
1.2、官网资料
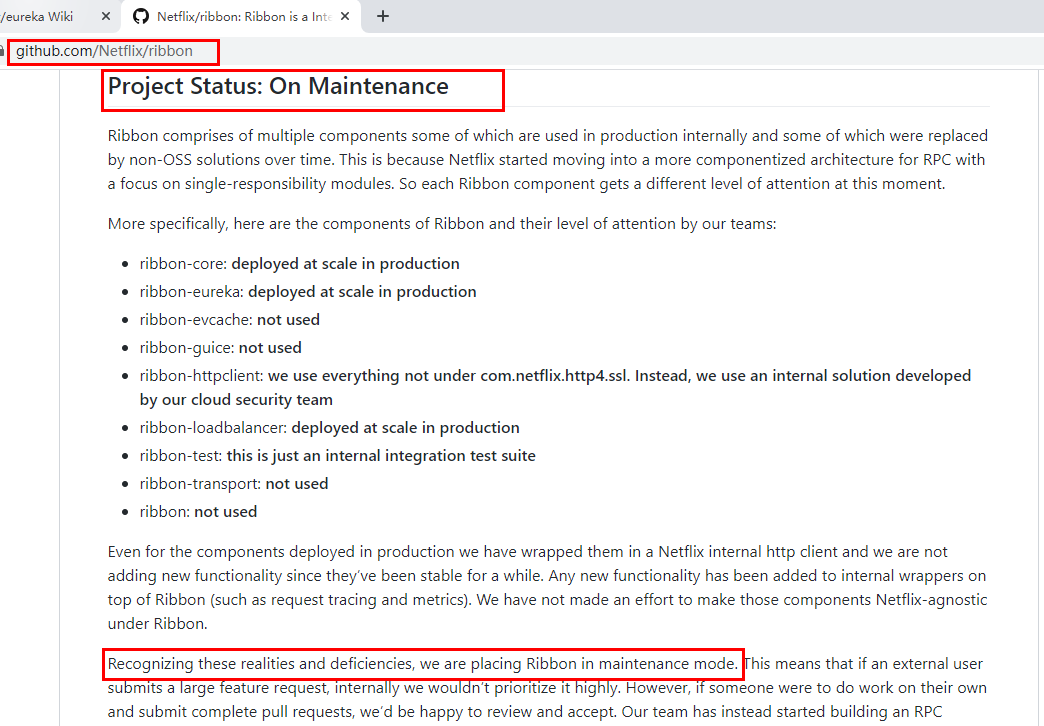
https://github.com/Netflix/ribbon/wiki/Getting-Started
Ribbon目前也进入维护模式
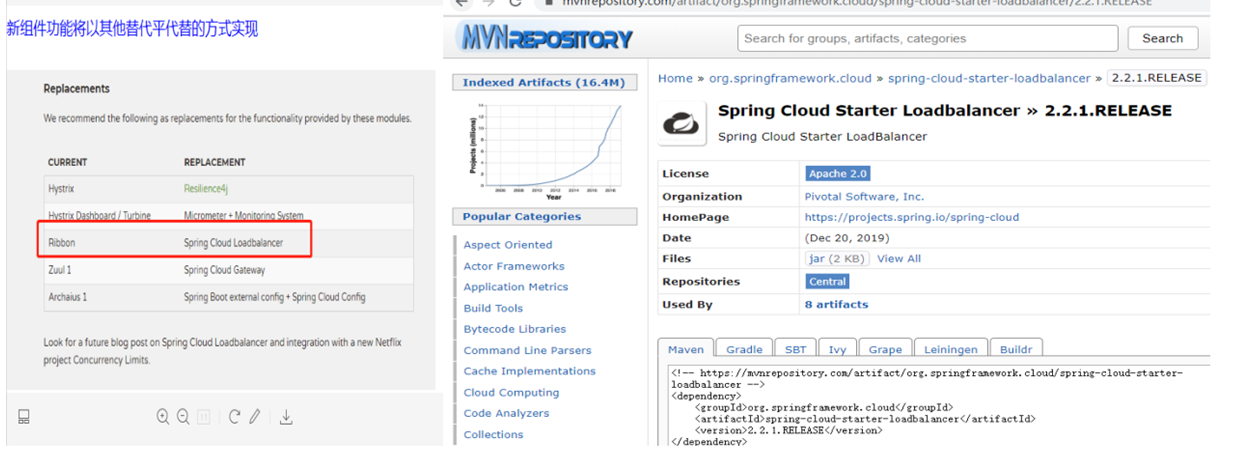
未来替换方案
1.3、能干嘛
1.3.1、LB负载均衡
1 |
|
集中式LB
1 | 集中式LB |
进程内LB
1 | 进程内LB |
1.3.2、前面我们讲解过了80通过轮询负载访问8001/8002
一句话:负载均衡+RestTemplate调用
2、Ribbon负载均衡演示
2.1、架构说明
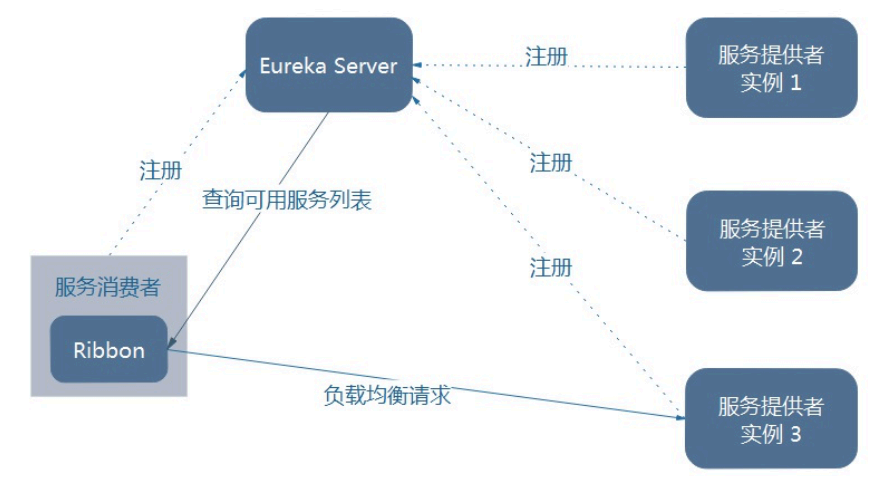
Ribbon在工作时分成两步
第一步先选择 EurekaServer ,它优先选择在同一个区域内负载较少的server.第二步再根据用户指定的策略,在从server取到的服务注册列表中选择一个地址。其中Ribbon提供了多种策略:比如轮询、随机和根据响应时间加权。
总结:Ribbon其实就是一个软负载均衡的客户端组件,他可以和其他所需请求的客户端结合使用,和eureka结合只是其中的一个实例。
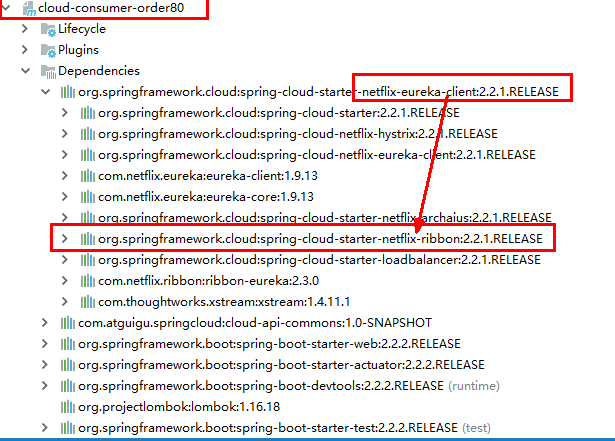
2.2、pom文件
之前写样例时候没有引入spring-cloud-starter-ribbon也可以使用ribbon
1 | <dependency> |
猜测spring-cloud-starter-netflix-eureka-client自带了spring-cloud-starter-ribbon引用,
证明如下: 可以看到spring-cloud-starter-netflix-eureka-client 确实引入了Ribbon:
2.3、RestTemplate的使用
2.3.1、官网
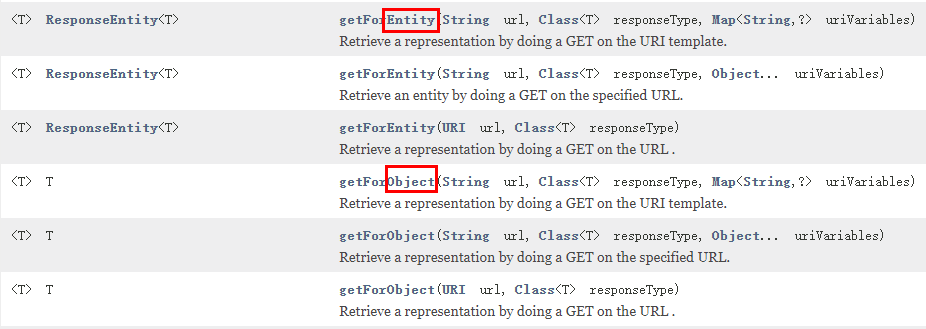
2.3.2、getForObject方法/getForEntity方法
返回对象为响应体中数据转化成的对象,基本上可以理解为Json

返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态码、响应体等

2.3.3、postForObject方法/postForEntity方法

2.3.4、GET请求方法
1 | <T> T getForObject(String url, Class<T> responseType, Object... uriVariables); |
2.3.5、POST请求方法
1 |
|
3、Ribbon核心组件IRule
3.1、IRule:根据特定算法中从服务列表中选取一个要访问的服务
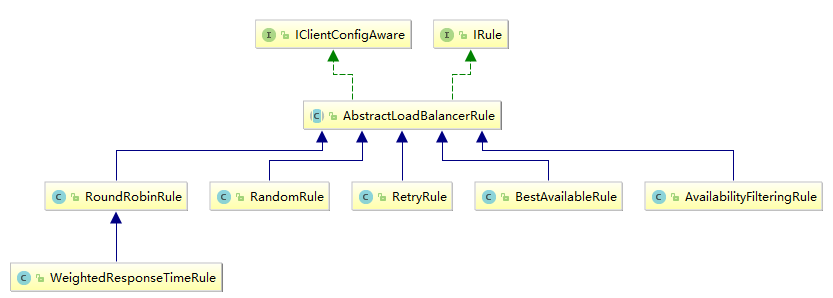
1 | com.netflix.loadbalancer.RoundRobinRule:轮询 |
3.2、如何替换
修改cloud-consumer-order80
3.2.1、配置细节
官方文档明确给出了警告:
这个自定义配置类不能放在@ComponentScan所扫描的当前包下以及子包下,否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,达不到特殊化定制的目的了。
3.2.2、新建package
3.2.3、上面包下新建MySelfRule规则类
1 | package com.lxg.myrule; |
3.2.4、主启动类添加@RibbonClient
1 | package com.lxg.springcloud; |
注意新版的Eureka已经没有ribbon了。使用的是loadbalancer
配置如下:
1、新建配置类,设置如下bean
1 | package com.lxg.springcloud.config; |
2、在RestTemplate配置上加注解
@LoadBalancerClient(name = “CLOUD-PAYMENT-SERVICE”,configuration = LoadBalanceConfig.class)是关键
1 | package com.lxg.springcloud.config; |
也可以在主启动类上添加
1 | //@LoadBalancerClient(name = "CLOUD-PAYMENT-SERVICE",configuration = ApplicationContextConfig.class) |
3.2.5、测试
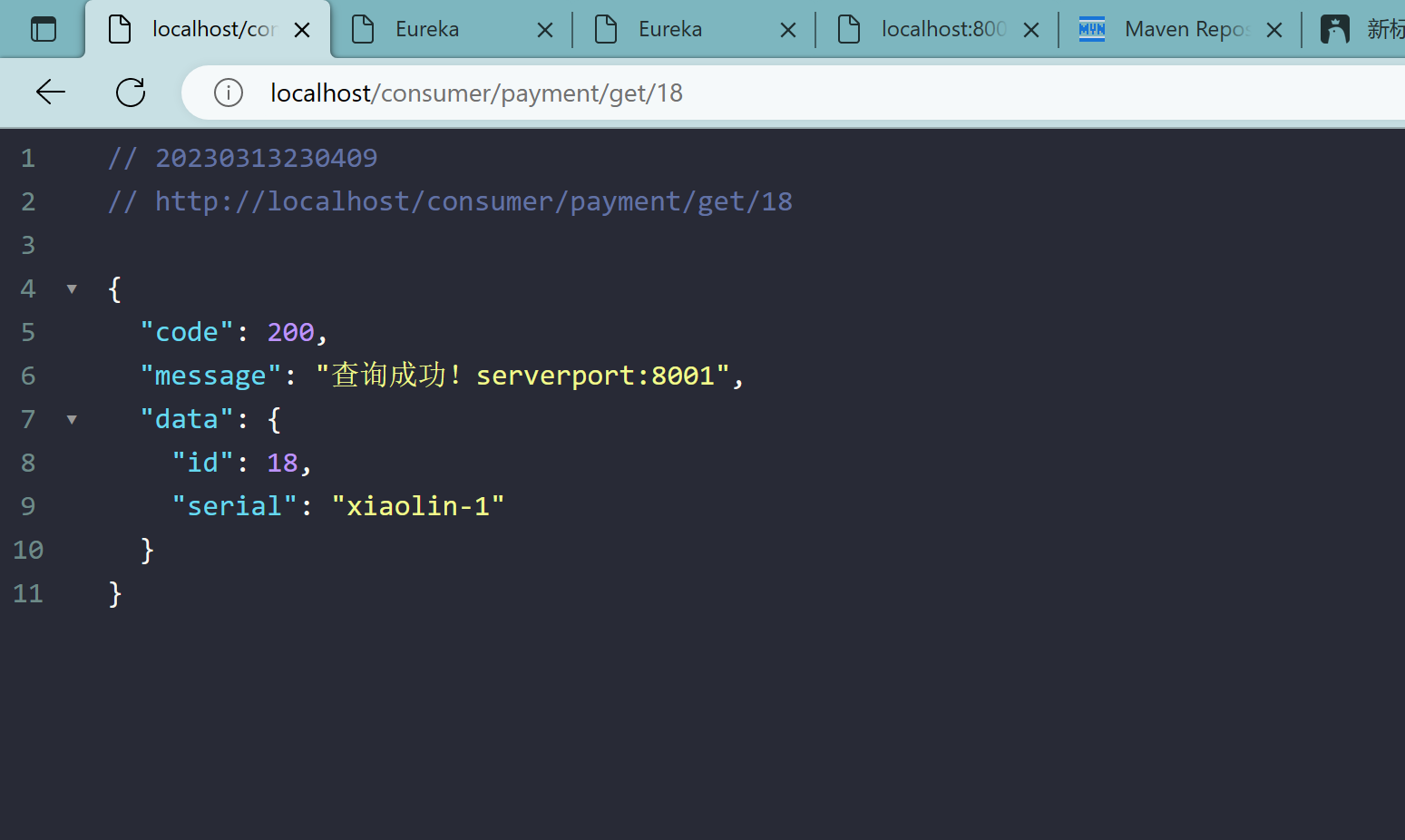
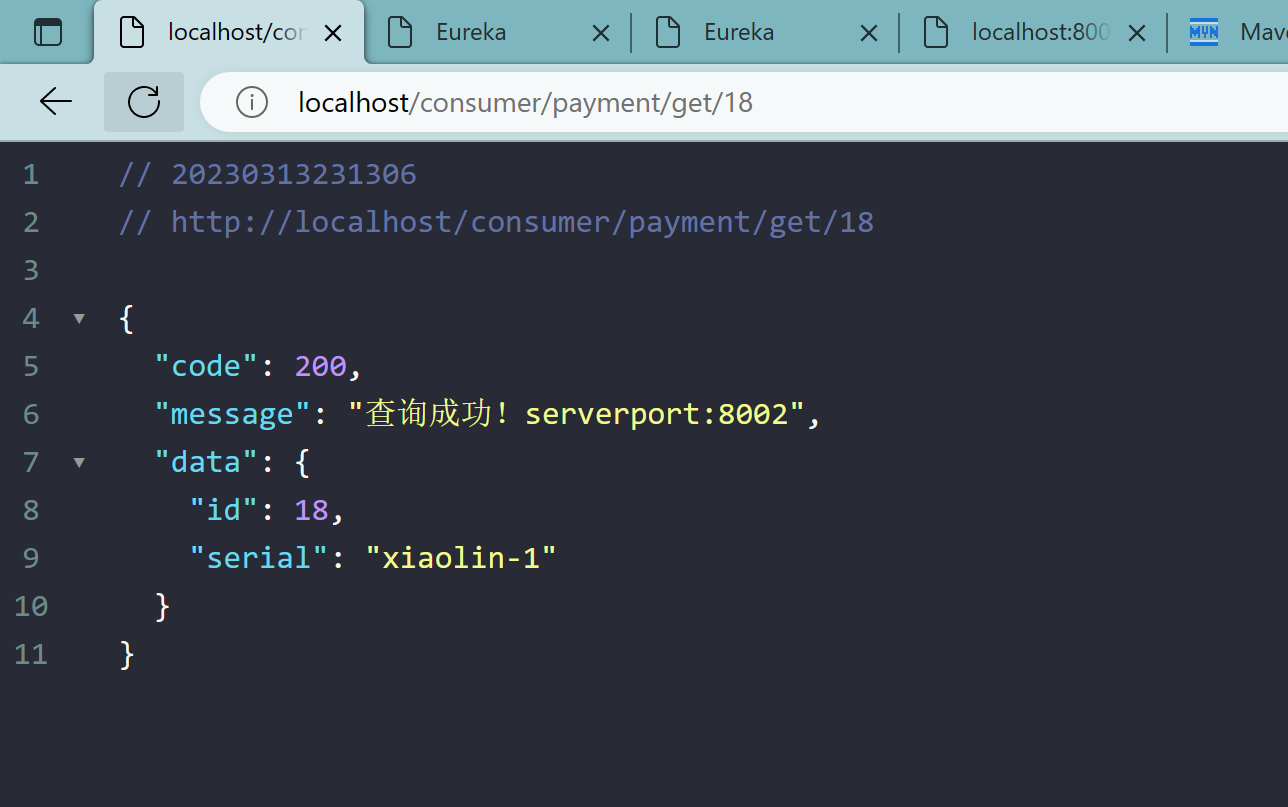
在8001和8002中随机切换
4、Ribbon负载均衡算法
4.1、原理
1 | 负载均衡算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标 ,每次服务重启动后rest接口计数从1开始。 |
4.2、RoundRobinRule源码
4.3、手写算法策略
自己试着写一个本地负载均衡器试试
4.3.1、在8001和8002controller进行修改
添加以下内容:
1 |
|
4.3.2、去掉@LoadBalanced注解
1 | package com.lxg.springcloud.config; |
4.3.3、编写一个LoadBalancer接口
1 | package com.lxg.springcloud.lb; |
4.3.4、编写接口实现类MyLB
1 | package com.lxg.springcloud.lb.impl; |
4.3.5、修改80 OrderController
新增以下内容:
1 |
|
4.3.6、测试
依次启动7001、7002、8001、8002
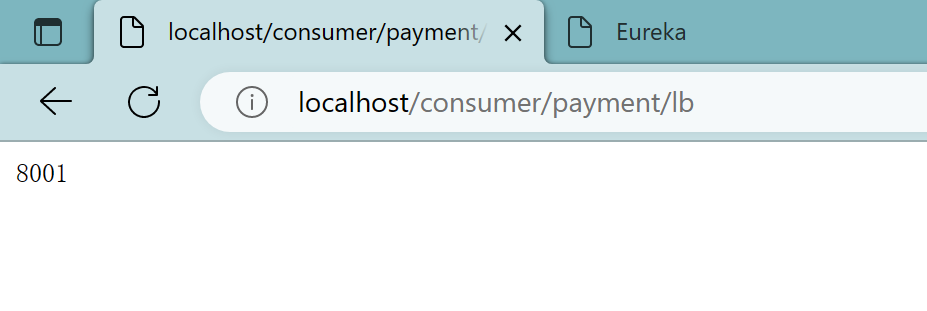
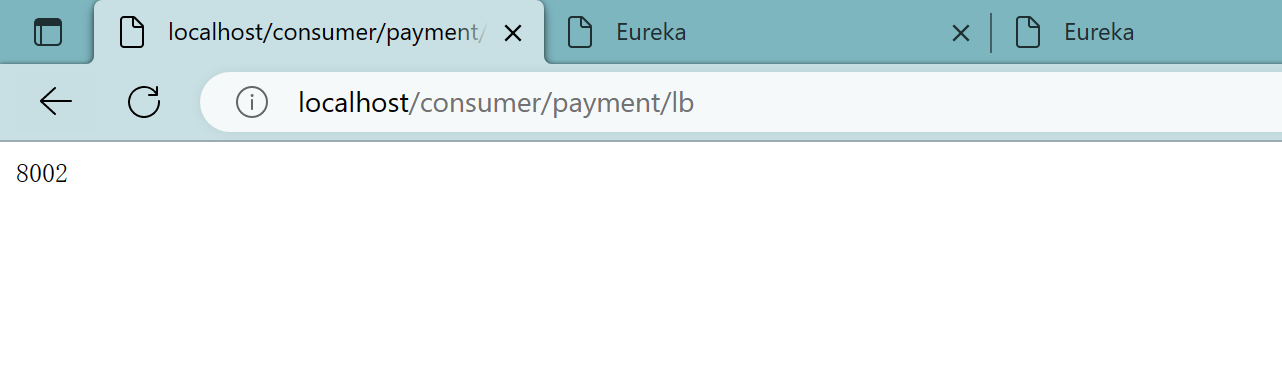
会在8001和8002中交替更换
十、OpenFeign服务接口调用
1、概述
1.1、OpenFeign是什么
1 | Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。 |
总结:
Feign是一个声明式的Web服务客户端,让编写Web服务客户端变得非常容易,只需创建一个接口并在接口上添加注解即可
GitHub:https://github.com/spring-cloud/spring-cloud-openfeign
1.2、能干嘛?
1 | Feign能干什么 |
1.3、Feign和OpenFeign的区别
| Feign | OpenFeign |
|---|---|
| Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端 Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务 |
OpenFeign是Spring Cloud 在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。 |
2、OpenFeign使用步骤
接口+注解
微服务调用接口+@FeignClient
2.1、新建cloud-consumer-feign-order80
Feign在消费端使用

2.2、pom文件
1 |
|
2.3、编写yml文件
1 | server: |
2.4、编写主启动类
1 | package com.lxg.springcloud; |
2.5、编写业务类
2.5.1、业务逻辑接口
加上@FeignClient注解配置调用provider服务
新增PaymentFeignService接口
1 | package com.lxg.springcloud.service; |
2.5.2、编写控制层controller
1 | package com.lxg.springcloud.controller; |
2.6、测试
先启动7001、7002
再启动8001、8002
再启动OrderFeignMain80
Feign自带负载均衡配置项
2.7、小总结
若需要更改负载均衡策略,则按以下步骤进行:
编写一个配置类:
1 | package com.lxg.springcloud.config; |
在启动类上添加注解
1 |
3、OpenFeign超时控制
3.1、故意设置超时
3.1.1、8001、8002写暂停程序
在controller中添加以下内容:
1 |
|
3.1.2、消费方80在接口中新增超时方法
1 |
|
3.1.3、消费方80在controller添加超时方法
1 |
|
3.1.4、测试
http://localhost/consumer/payment/feign/timeout
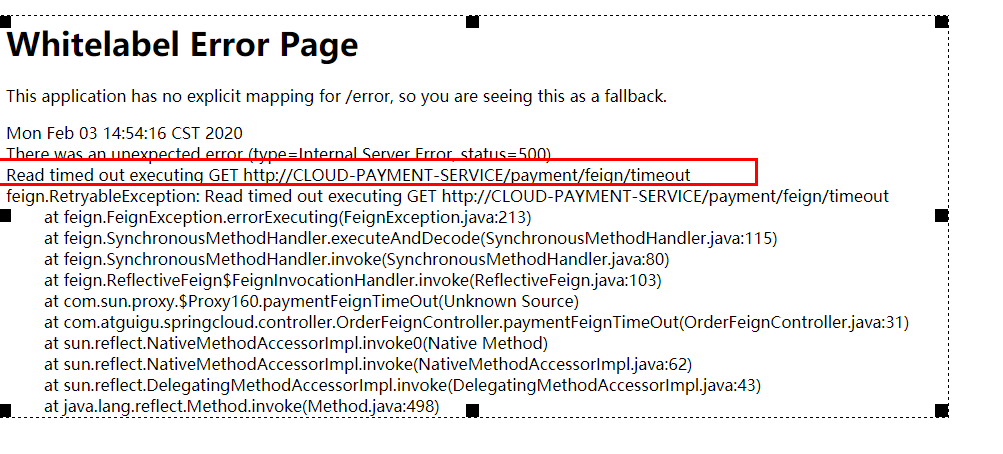
OpenFeign默认等待5秒钟,超过后报错
3.2、超时配置
默认Feign客户端只等待5秒钟,但是服务端处理需要超过5秒钟,导致Feign客户端不想等待了,直接返回报错。(老版本1秒)
为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制。
yml文件中开启配置
1 | #老版 |
4、OpenFeign日志打印功能
4.1、是什么
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别,从而了解 Feign 中 Http 请求的细节。
说白了就是对Feign接口的调用情况进行监控和输出
4.2、日志级别
NONE:默认的,不显示任何日志;
BASIC:仅记录请求方法、URL、响应状态码及执行时间;
HEADERS:除了 BASIC 中定义的信息之外,还有请求和响应的头信息;
FULL:除了 HEADERS 中定义的信息之外,还有请求和响应的正文及元数据。
4.3、配置日志级别
配置类方式:
1 | package com.lxg.springcloud.config; |
yml文件配置方式:
1 | feign: |
4.4、开启日志
1 | logging: |
4.5、查看日志
十一、Hystrix断路器
1、概述
1.1、分布式系统面临的问题
分布式系统面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。

服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
所以,通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
1.2、是什么?
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
1.3、能干嘛
- 服务降级
- 服务熔断
- 接近实时的监控
- ……
1.4、官网资料
How To Use · Netflix/Hystrix Wiki · GitHub
1.5、目前状态:停更
https://github.com/Netflix/Hystrix
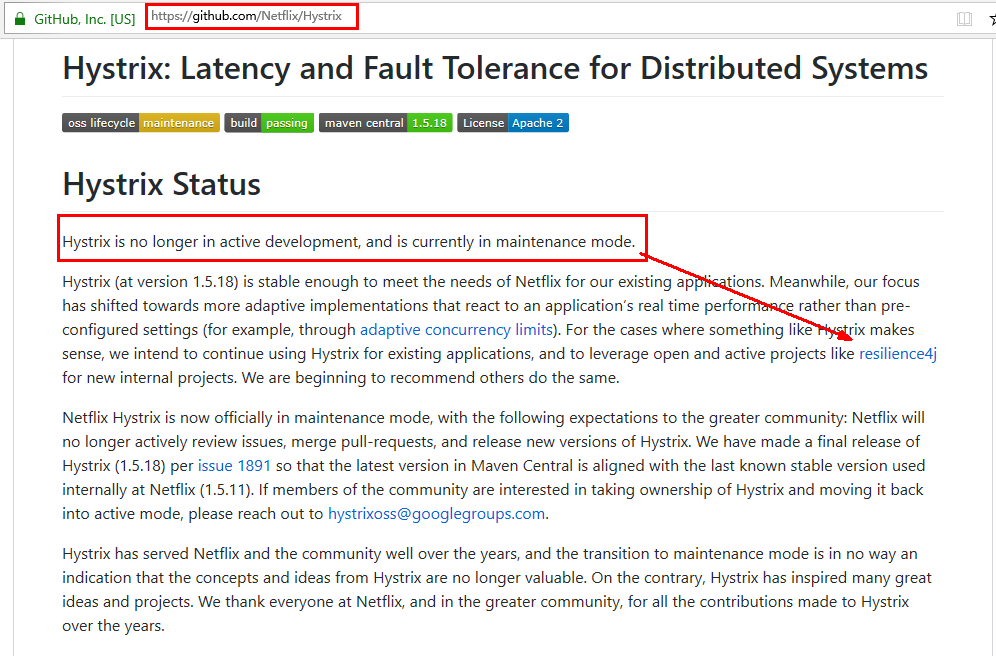
被动修复bugs
不再接受合并请求
不再发布新版本
2、Hystrix重要概念
2.1、服务降级
服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback
什么情况会出现触发服务降级?
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
仍然可以发起请求,但是当请求出现以上情况时就会触发服务降级fallback
2.2、服务熔断
类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示
就是保险丝:服务的降级->进而熔断->恢复调用链路
不能继续发起请求,直接拒绝访问,并返回
2.3、服务限流
秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行
3、hystrix案例
3.1、构建
3.1.1、新建cloud-provider-hystrix-payment8001
3.1.2、修改pom文件
1 |
|
特别注意,hystrix在新版中需要指明版本号
3.1.3、编写yml文件
1 | server: |
3.1.4、编写主启动类
1 | package com.lxg.springcloud; |
3.1.5、编写业务类
接口service:
1 | package com.lxg.springcloud.service; |
接口实现类:
1 | package com.lxg.springcloud.service.Impl; |
controller:
1 | package com.lxg.springcloud.controller; |
3.1.6、正常测试
启动7001
启动cloud-provider-hystrix-payment8001
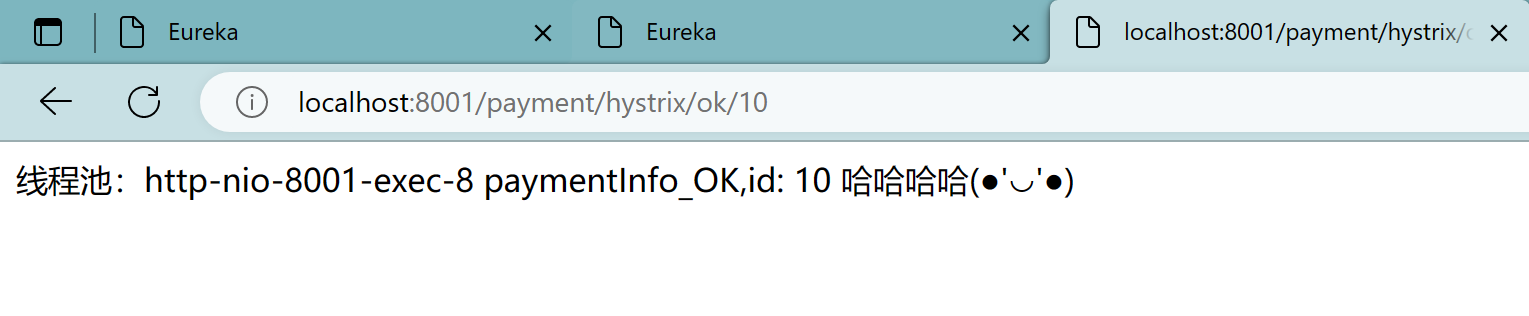
访问:
ok的方法:localhost:8001/payment/hystrix/ok/10
timeout的方法:localhost:8001/payment/hystrix/timeout/10

上述module均OK
以上述为根基平台,从正确->错误->降级熔断->恢复
3.2、高并发测试
上述在非高并发情形下,还能勉强满足
3.2.1、Jmeter压测测试
开启Jmeter,来20000个并发压死8001,20000个请求都去访问paymentInfo_TimeOut服务
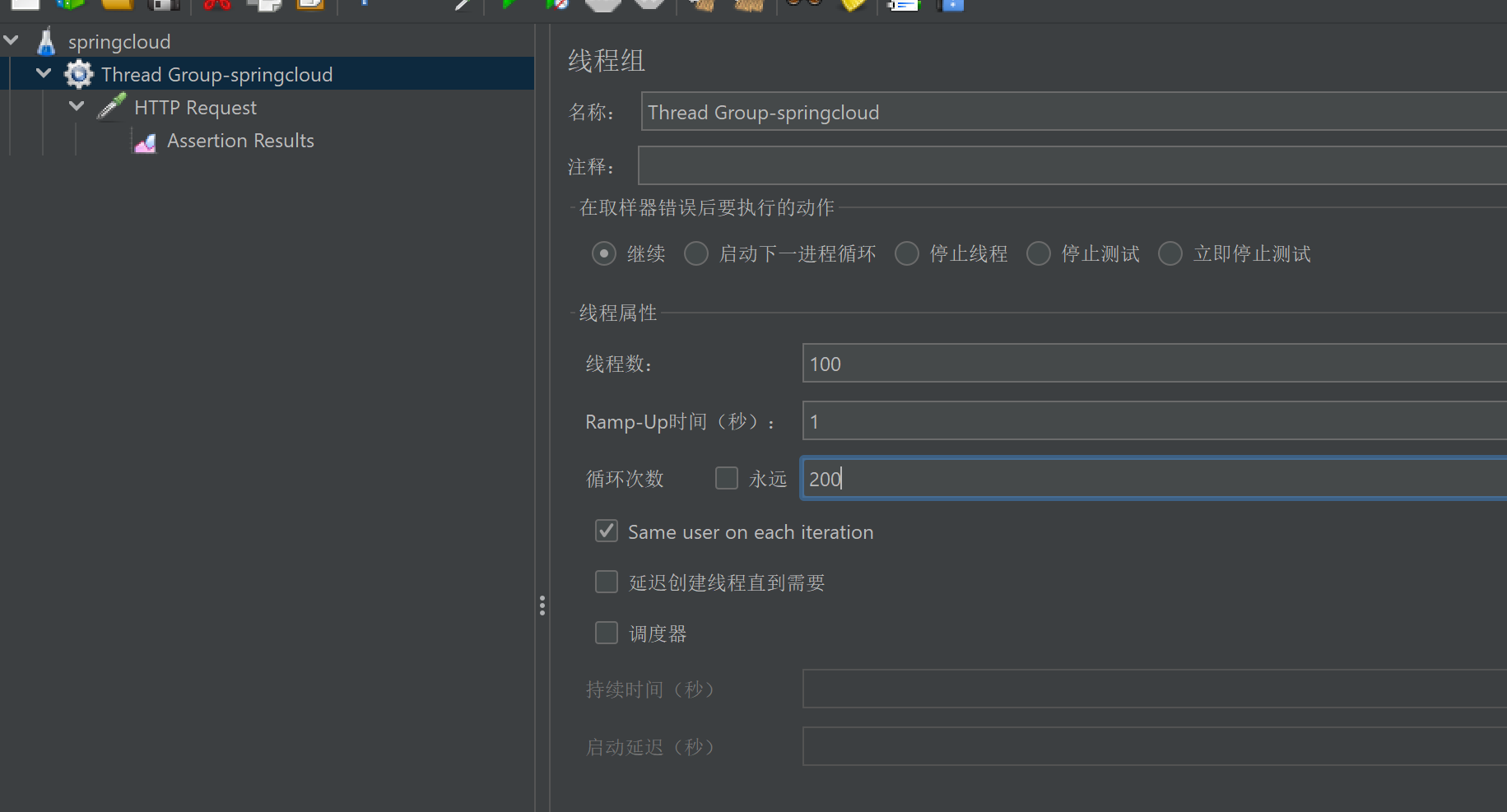
此时再去访问:
localhost:8001/payment/hystrix/ok/10
会发现无论是ok还是timeout都被卡死
为什么:
tomcat的默认的工作线程数被打满 了,没有多余的线程来分解压力和处理。
3.2.2、Jmeter压测结论
上面还是服务提供者8001自己测试,假如此时外部的消费者80也来访问,那消费者只能干等,最终导致消费端80不满意,服务端8001直接被拖死
3.2.3、加入80消费者
1、新建cloud-consumer-feign-hystrix-order80
2、改pom文件
1 |
|
3、编写yml
1 | server: |
4、编写主启动类
1 | package com.lxg.springcloud; |
5、编写业务类
PaymentHystrixService:
1 | package com.lxg.springcloud.service; |
OrderHystrixController:
1 | package com.lxg.springcloud.controller; |
6、正常测试
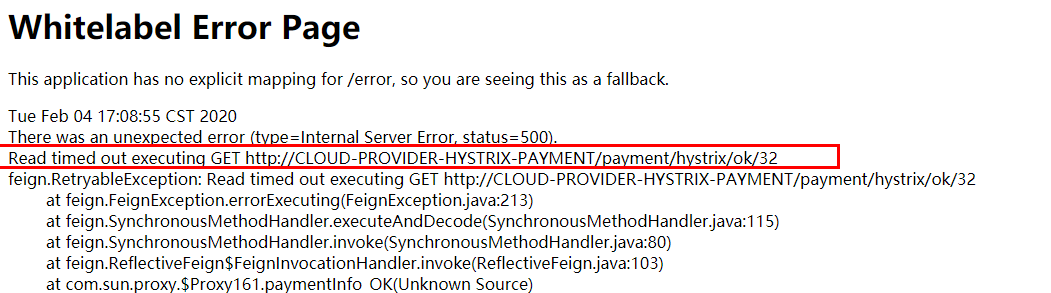
7、高并发测试
2W个线程压8001
消费端80微服务再去访问正常的Ok微服务8001地址
http://localhost/consumer/payment/hystrix/ok/32
消费者80,o(╥﹏╥)o:
要么转圈圈等待
要么消费端报超时错误
3.3、故障现象和原因
8001同一层次的其它接口服务被困死,因为tomcat线程池里面的工作线程已经被挤占完毕
80此时调用8001,客户端访问响应缓慢,转圈圈
3.4、上述结论
正因为有上述故障或不佳表现
才有我们的降级/容错/限流等技术诞生
3.5、如何解决?解决的要求
超时导致服务器变慢(转圈):超时不再等待
出错(宕机或程序运行出错):出错要有兜底
解决:
- 对方服务(8001)超时了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)down机了,调用者(80)不能一直卡死等待,必须有服务降级
- 对方服务(8001)OK,调用者(80)自己出故障或有自我要求(自己的等待时间小于服务提供者),自己处理降级
3.6、服务降级
降级一般是客户端处理,熔断是在服务端处理的
3.6.1、降级配置
@HystrixCommand
3.6.2、8001问题所在
设置自身调用超时时间的峰值,峰值内可以正常运行,超过了需要有兜底的方法处理,作服务降级fallback
3.6.3、8001配置如下
1、业务类启用@HystrixCommand报异常后如何处理
1 | package com.lxg.springcloud.service.Impl; |
一旦调用服务方法失败并抛出了错误信息后,
会自动调用@HystrixCommand标注好的
fallbackMethod调用类中的指定方法
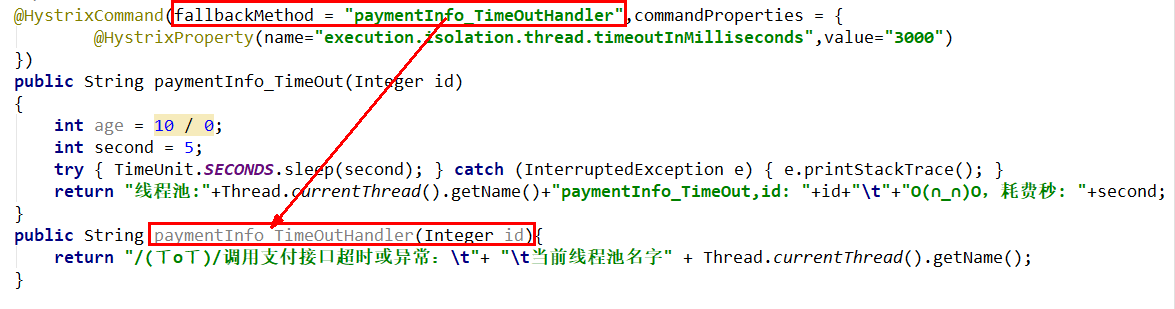
上图故意制造两个异常:
1 int age = 10/0; 计算异常
2 我们能接受3秒钟,它运行5秒钟,超时异常。当前服务不可用了,做服务降级,兜底的方案都是paymentInfo_TimeOutHandler
2、主启动类激活
添加新注解@EnableCircuitBreaker

3.6.4、80配置如下
80订单微服务,也可以更好的保护自己,自己也依样画葫芦进行客户端降级保护
注意:
我们自己配置过的热部署方式对java代码的改动明显,
但对@HystrixCommand内属性的修改建议重启微服务
1、修改yml文件:
1 | server: |
注意:此处必须设置hystrix的超时时间,否则默认为1秒
2、修改主启动类
1 | package com.lxg.springcloud; |
3、修改业务类
1 | package com.lxg.springcloud.controller; |
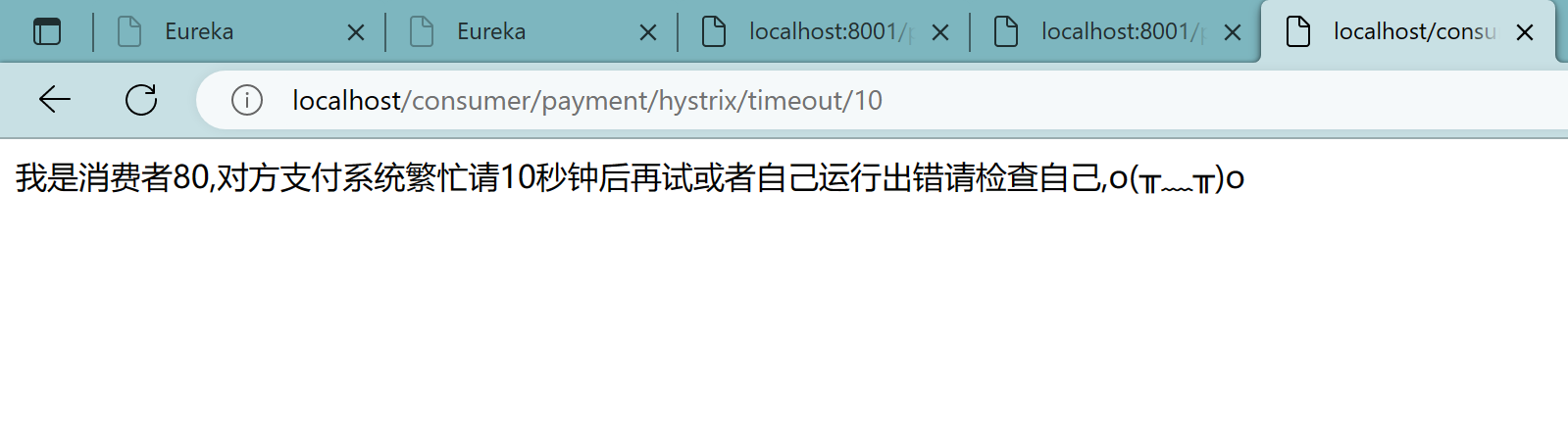
3.6.5、当前问题
每个业务方法对应一个兜底的方法,代码膨胀
最好能把统一和自定义的东西分开
3.6.6、解决问题
1、全局fallback(解决膨胀问题)
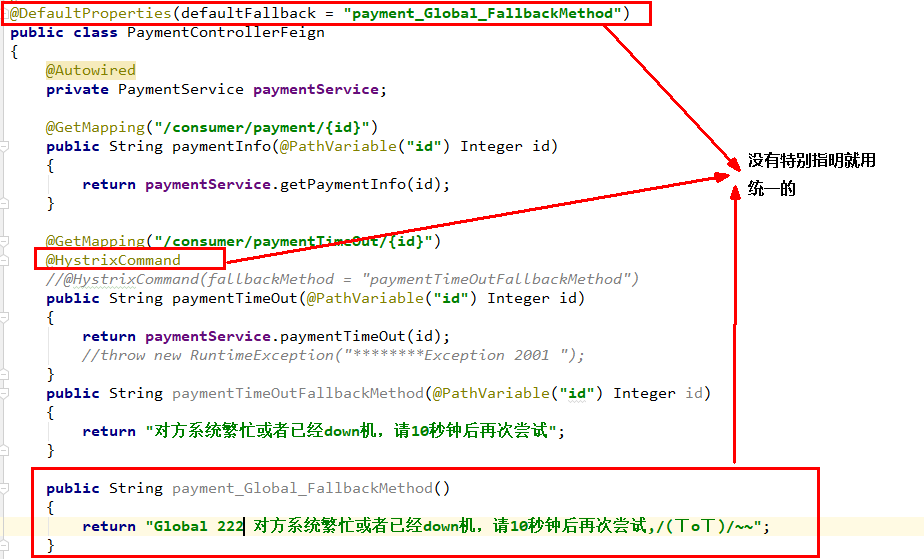
@DefaultProperties(defaultFallback = “”)
1:1 每个方法配置一个服务降级方法,技术上可以,实际上傻X
1:N 除了个别重要核心业务有专属,其它普通的可以通过@DefaultProperties(defaultFallback = “”) 统一跳转到统一处理结果页面
通用的和独享的各自分开,避免了代码膨胀,合理减少了代码量,O(∩_∩)O哈哈~
controller配置:
1 | package com.lxg.springcloud.controller; |
2、FeignClient (解决业务逻辑混乱)
另外:feign常用俩种降级方式Fallback和FallbackFactory。
功能:服务降级,客户端去调用服务端,碰上服务端宕机或关闭
- fallbackFactory 推荐:可以捕获异常信息并返回默认降级结果。可以打印堆栈信息。
- fallback 不推荐:不能捕获异常打印堆栈信息,不利于问题排查。
本次案例服务降级处理是在客户端80实现完成的,与服务端8001没有关系
只需要为Feign客户端定义的接口添加一个服务降级处理的实现类即可实现解耦
fallback:
①yml配置添加:
1 | server: |
②在需要被处理的类上添加以下配置
fallback指定进行处理的类
1 |
如:
1 | package com.lxg.springcloud.service; |
③创建FallbackTest去实现上述添加注解的类:
1 | package com.lxg.springcloud.service; |
fallbackfactory:
同理在被处理类上添加:
1 |
新建FallbackFactoryTest类:
1 | package com.lxg.springcloud.service; |
fallback和fallbackfactory本质没区别,fallbackfactory多了一些错误信息可以方便打印
注意这两种方式只能处理提供方出现错误或超时等情况,自身出现错误,无法处理
3.6.7、总结
- 使用OpenFeign的客户端在使用hystrix进行服务降级时,要注意在yml文件设置超时时间,feign默认的为连接10s和读60秒,hystrix默认为1s,在触发服务降级时会判断哪个超时时间最短,就会用最短的那个。
- 如果yml中设置了hystrix超时时间,而@HystrixProperty没设置,以yml的为准,如果yml没设置,默认1s,此时@HystrixProperty只有设置更低才生效,也就是这两个配置谁时间短谁生效
- feignclient属性的fallback和fallbackfactory只能处理服务提供方发生的错误,无法处理自身错误
3.7、服务熔断
3.7.1、断路器
一句话就是家里的保险丝
3.7.2、熔断是什么
熔断机制概述
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,
当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
大神论文:https://martinfowler.com/bliki/CircuitBreaker.html
3.7.3、实操
1、修改PaymentService和PaymentServiceImpl(8001)
新增:
PaymentService:
1 | public String paymentCircuitBreaker( Integer id); |
PaymentServiceImpl:
1 | //====服务熔断 |

可以上官网查看配置属性,也可以查看HystrixCommandProperties类
2、修改PaymentController
1 | //==服务熔断 |
3、测试
localhost:8001/payment/circuit/9

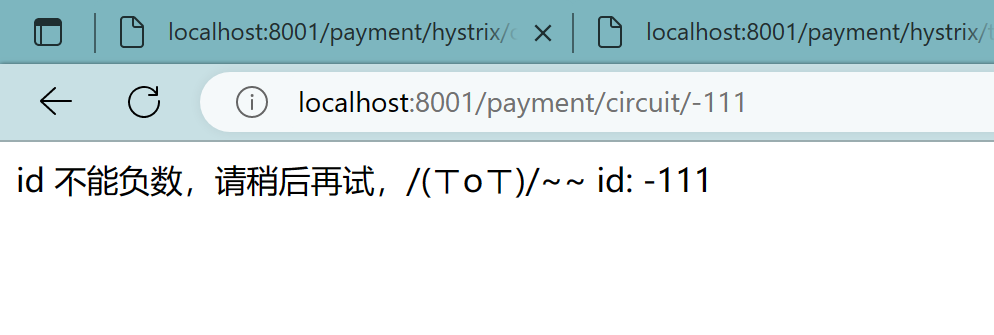
多次错误,然后慢慢正确,发现刚开始不满足条件,就算是正确的访问地址也不能进行
3.7.4、原理(小总结)
大神结论:
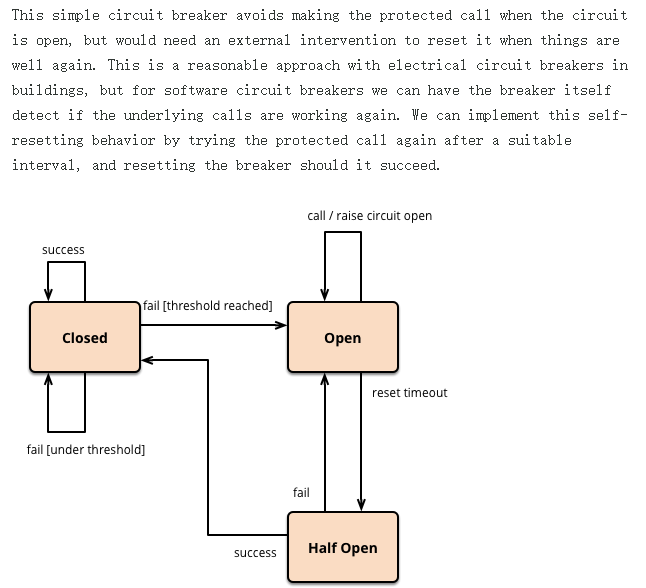
熔断类型:
- 熔断打开:请求不再进行调用当前服务,内部设置时钟一般为MTTR(平均故障处理时间),当打开时长达到所设时钟则进入半熔断状态
- 熔断关闭:熔断关闭不会对服务进行熔断
- 熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断
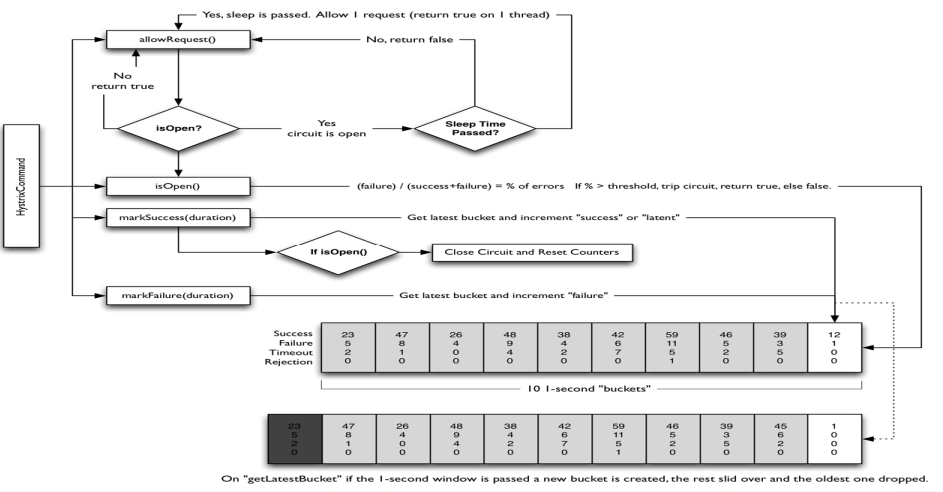
官网断路器流程图:
官网步骤

1 | 电路开合的准确发生方式如下: |
断路器在什么情况下开始起作用:

涉及到断路器的三个重要参数:快照时间窗、请求总数阀值、错误百分比阀值。
1:快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
2:请求总数阀值:在快照时间窗内,必须满足请求总数阀值才有资格熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
3:错误百分比阀值:当请求总数在快照时间窗内超过了阀值,比如发生了30次调用,如果在这30次调用中,有15次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%阀值情况下,这时候就会将断路器打开。
断路器开启或者关闭的条件:
1 | 当满足一定的阀值的时候(默认10秒内超过20个请求次数) |
断路器打开之后:
1:再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
2:原来的主逻辑要如何恢复呢?
对于这一问题,hystrix也为我们实现了自动恢复功能。
当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
All配置:
1 | //========================All |
3.8、服务限流
后面高级篇讲解alibaba的Sentinel说明
4、hystrix工作流程
4.1官网翻译阅读
https://github.com/Netflix/Hystrix/wiki/How-it-Works
4.2、官网图例:
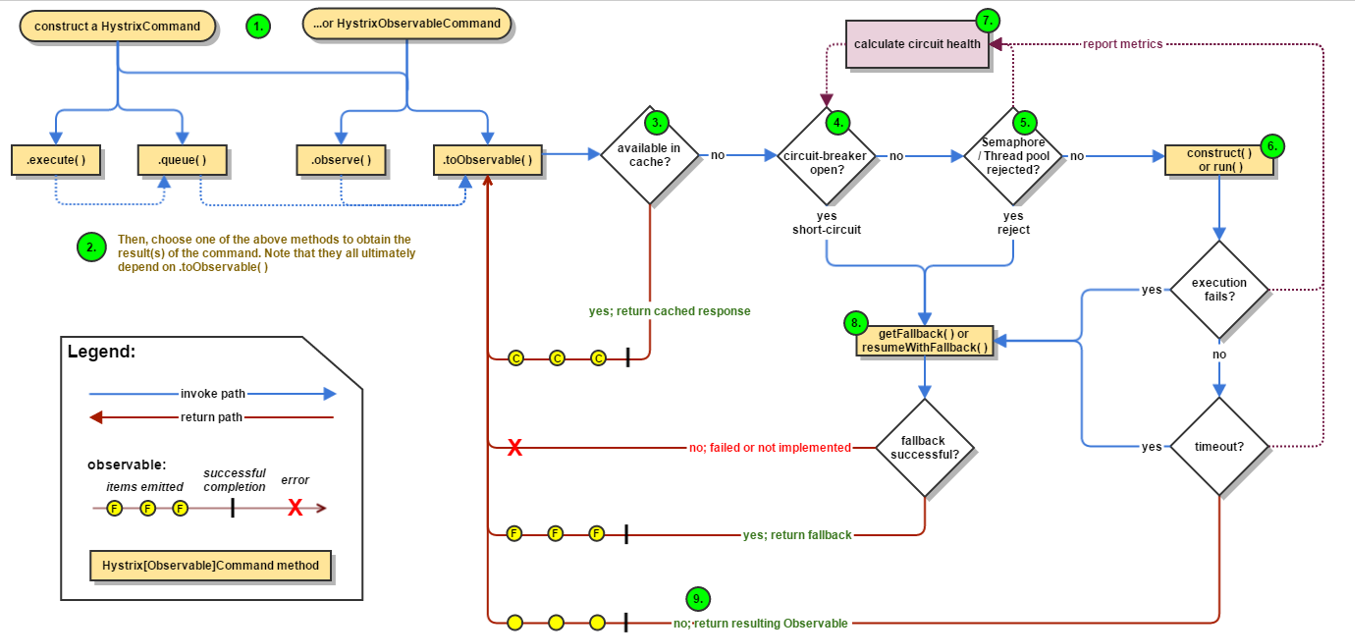
4.3、步骤说明:
| 1 | 创建 HystrixCommand(用在依赖的服务返回单个操作结果的时候) 或 HystrixObserableCommand(用在依赖的服务返回多个操作结果的时候) 对象。 |
|---|---|
| 2 | 命令执行。其中 HystrixComand 实现了下面前两种执行方式;而 HystrixObservableCommand 实现了后两种执行方式:execute():同步执行,从依赖的服务返回一个单一的结果对象, 或是在发生错误的时候抛出异常。queue():异步执行, 直接返回 一个Future对象, 其中包含了服务执行结束时要返回的单一结果对象。observe():返回 Observable 对象,它代表了操作的多个结果,它是一个 Hot Obserable(不论 “事件源” 是否有 “订阅者”,都会在创建后对事件进行发布,所以对于 Hot Observable 的每一个 “订阅者” 都有可能是从 “事件源” 的中途开始的,并可能只是看到了整个操作的局部过程)。toObservable(): 同样会返回 Observable 对象,也代表了操作的多个结果,但它返回的是一个Cold Observable(没有 “订阅者” 的时候并不会发布事件,而是进行等待,直到有 “订阅者” 之后才发布事件,所以对于 Cold Observable 的订阅者,它可以保证从一开始看到整个操作的全部过程)。 |
| 3 | 若当前命令的请求缓存功能是被启用的, 并且该命令缓存命中, 那么缓存的结果会立即以 Observable 对象的形式 返回。 |
| 4 | 检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到 fallback 处理逻辑(第 8 步);如果断路器是关闭的,检查是否有可用资源来执行命令(第 5 步)。 |
| 5 | 线程池/请求队列/信号量是否占满。如果命令依赖服务的专有线程池和请求队列,或者信号量(不使用线程池的时候)已经被占满, 那么 Hystrix 也不会执行命令, 而是转接到 fallback 处理逻辑(第8步)。 |
| 6 | Hystrix 会根据我们编写的方法来决定采取什么样的方式去请求依赖服务。HystrixCommand.run() :返回一个单一的结果,或者抛出异常。HystrixObservableCommand.construct(): 返回一个Observable 对象来发射多个结果,或通过 onError 发送错误通知。 |
| 7 | Hystrix会将 “成功”、”失败”、”拒绝”、”超时” 等信息报告给断路器, 而断路器会维护一组计数器来统计这些数据。断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行 “熔断/短路”。 |
| 8 | 当命令执行失败的时候, Hystrix 会进入 fallback 尝试回退处理, 我们通常也称该操作为 “服务降级”。而能够引起服务降级处理的情况有下面几种:第4步: 当前命令处于”熔断/短路”状态,断路器是打开的时候。第5步: 当前命令的线程池、 请求队列或 者信号量被占满的时候。第6步:HystrixObservableCommand.construct() 或 HystrixCommand.run() 抛出异常的时候。 |
| 9 | 当Hystrix命令执行成功之后, 它会将处理结果直接返回或是以Observable 的形式返回。 |
| tips | 如果我们没有为命令实现降级逻辑或者在降级处理逻辑中抛出了异常, Hystrix 依然会返回一个 Observable 对象, 但是它不会发射任何结果数据, 而是通过 onError 方法通知命令立即中断请求,并通过onError()方法将引起命令失败的异常发送给调用者。 |
5、服务监控HystrixDashboard
5.1、概述
除了隔离依赖服务的调用以外,Hystrix还提供了准实时的调用监控(Hystrix Dashboard),Hystrix会持续地记录所有通过Hystrix发起的请求的执行信息,并以统计报表和图形的形式展示给用户,包括每秒执行多少请求多少成功,多少失败等。Netflix通过hystrix-metrics-event-stream项目实现了对以上指标的监控。Spring Cloud也提供了Hystrix Dashboard的整合,对监控内容转化成可视化界面。
5.2、仪表盘9001
5.2.1、新建cloud-consumer-hystrix-dashboard9001
5.2.2、修改pom文件
1 |
|
5.2.3、修改yml文件
1 | #端口号,自己定义的 |
5.3.4、在9001的主启动类上添加注解
@EnableHystrixDashboard
5.3.5、在所有provider微服务提供者8001、8002上都需要添加监控依赖配置
1 | <!-- actuator监控信息完善 --> |
5.3.6、启动9001查看效果
5.3、断路器演示(服务监控HystrixDashboard)
5.3.1、修改8001
注意:新版本Hystrix需要在主启动类MainAppHystrix8001中指定监控路径
1 | /** |
不然会报错404或Unable to connect to Command Metric Stream.
5.3.2、监控测试
1、启动eureka集群
2、观察监控窗口
在9001监控页面添加监控地址:
http://localhost:8001/hystrix.stream
先访问正常:localhost:8001/payment/circuit/9
再访问错误:localhost:8001/payment/circuit/-99
以上访问无误!
打开监控面板:
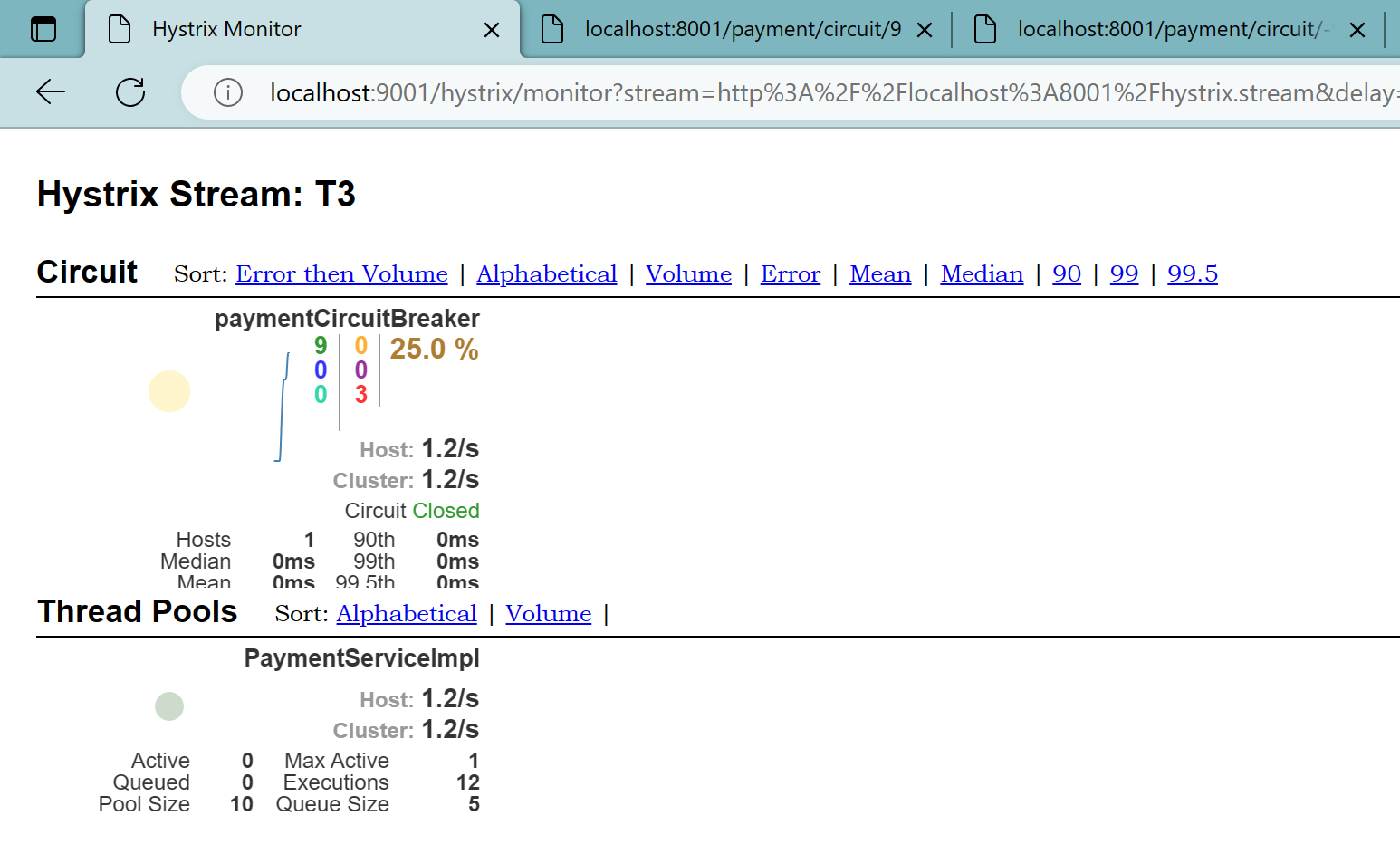
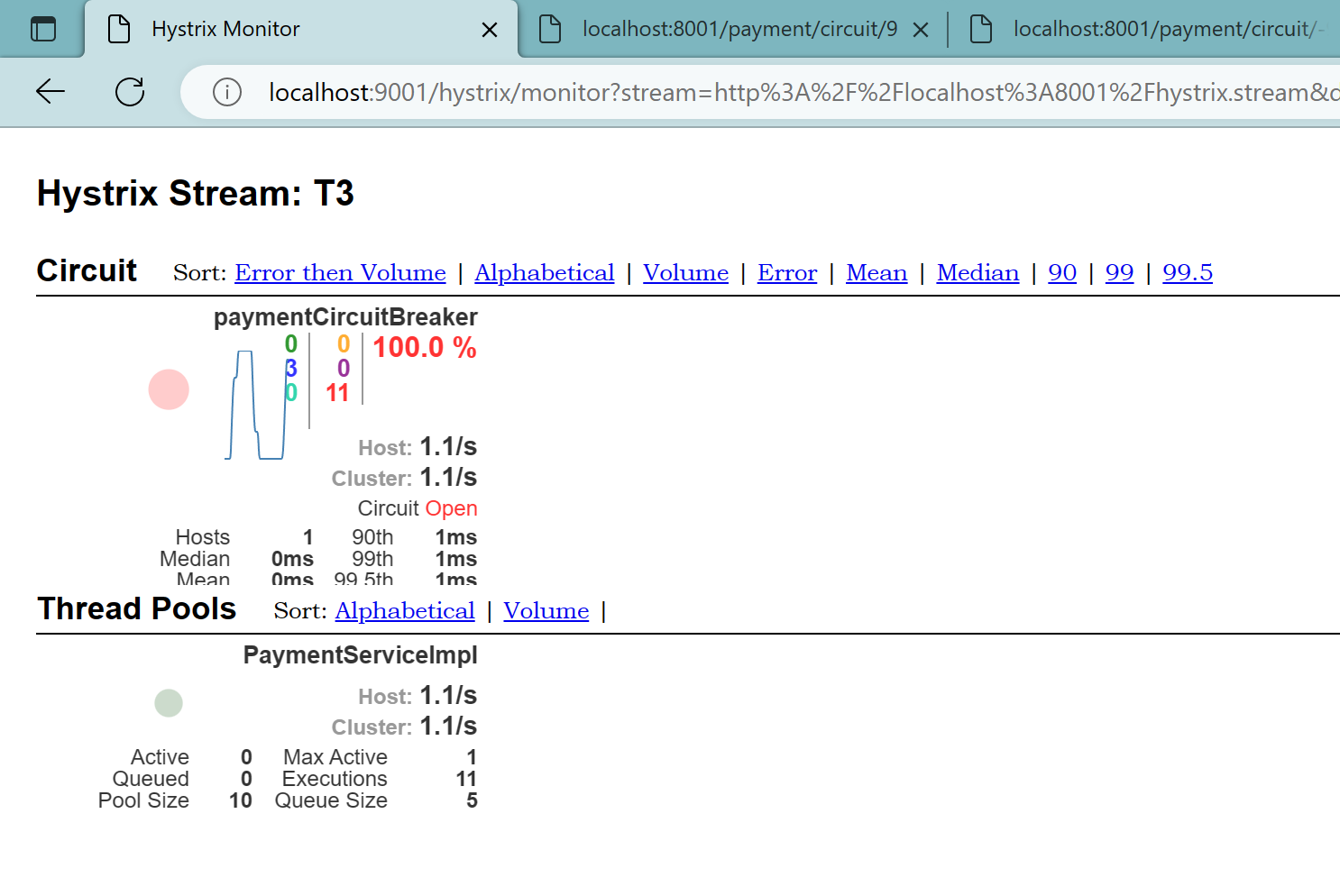
面板如何看?
7色:
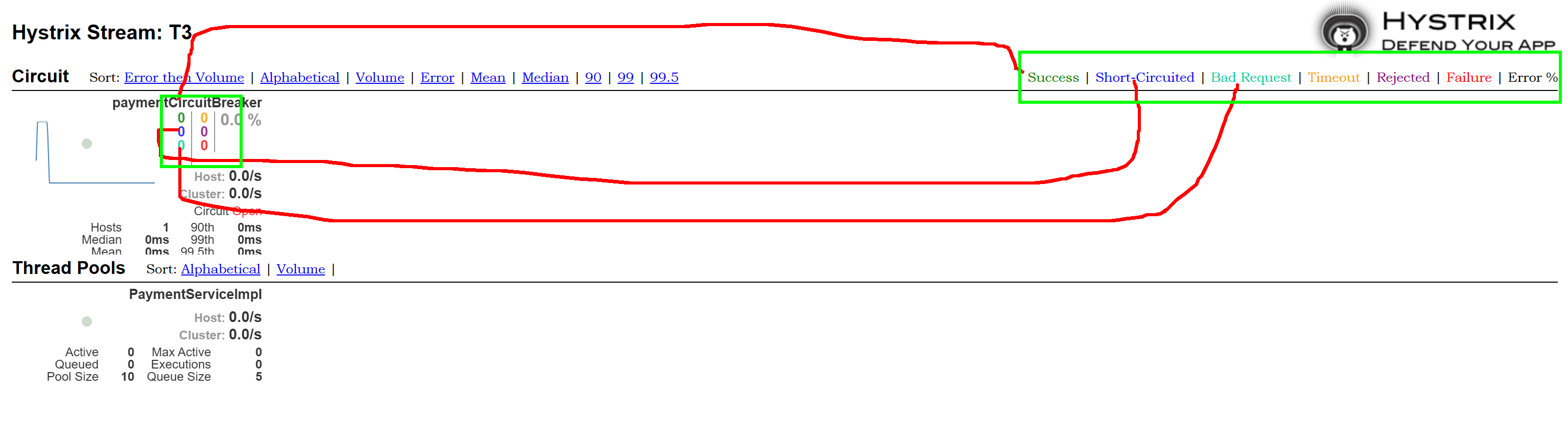
1圈:
实心圆:共有两种含义。它通过颜色的变化代表了实例的健康程度,它的健康度从绿色<黄色<橙色<红色递减。
该实心圆除了颜色的变化之外,它的大小也会根据实例的请求流量发生变化,流量越大该实心圆就越大。所以通过该实心圆的展示,就可以在大量的实例中快速的发现故障实例和高压力实例。
1线:
曲线:用来记录2分钟内流量的相对变化,可以通过它来观察到流量的上升和下降趋势。
整体说明:
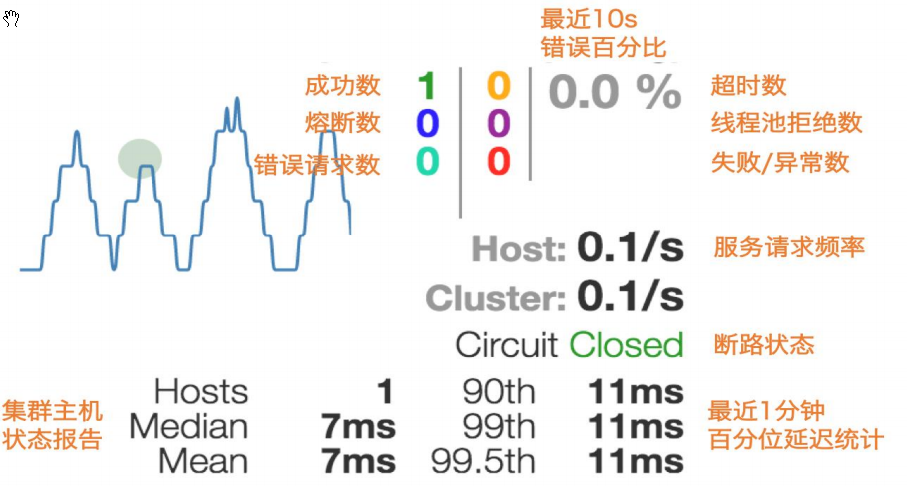
看懂一个再看复杂的:
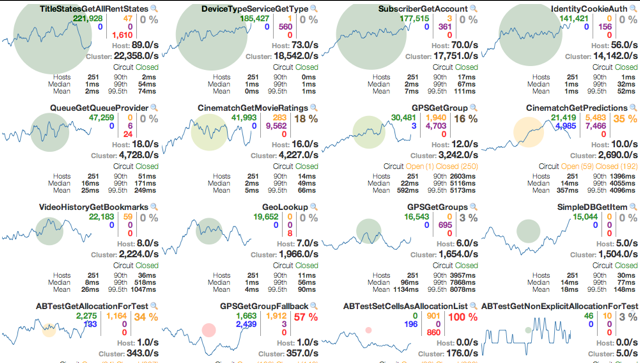
resilience4j在国内不常用,可以简单自己去了解
十二、zuul路由网关
阅读脑图自行实践
十三、GateWay新一代网关
1、概述简介
1.1、官网
上一代zuul 1.x:https://github.com/Netflix/zuul/wiki
当前gateway:Spring Cloud Gateway
1.2、是什么
Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关;
但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关替代Zuul,
那就是SpringCloud Gateway一句话:gateway是原zuul1.x版的替代
1.2.1、概述
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring 5,Spring Boot 2和 Project Reactor等技术。
Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能, 例如:熔断、限流、重试等

1 | 这个项目提供了一个建立在Spring生态系统之上的API网关,包括:Spring 5、Spring Boot 2和project Reactor 等技术。Spring Cloud Gateway旨在提供一种简单而有效的方式来路由到api,并提供横切关注点到它们,包括:安全性、监视/度量和弹性。 |
一句话:SpringCloud Gateway 使用的Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯框架。
1.2.2、能干嘛
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
- …….
1.2.3、微服务架构中网关所在位置
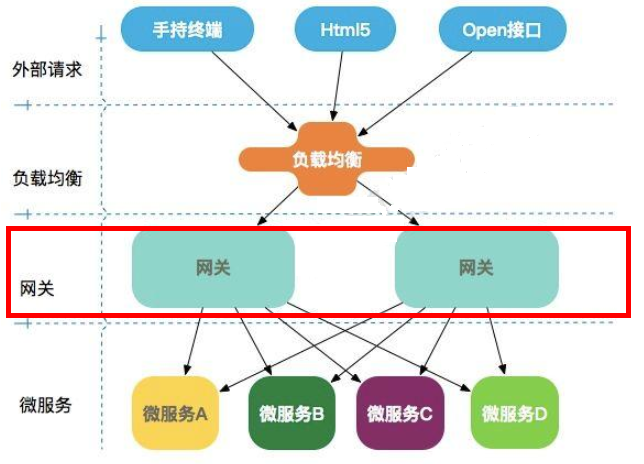
1.2.4、有zuul了怎么还要出gateway
原因:
neflix不太靠谱,zuul2.0一直跳票,迟迟不发布
1
2
3
4
5
6
7一方面因为Zuul1.0已经进入了维护阶段,而且Gateway是SpringCloud团队研发的,是亲儿子产品,值得信赖。
而且很多功能Zuul都没有用起来也非常的简单便捷。
Gateway是基于异步非阻塞模型上进行开发的,性能方面不需要担心。虽然Netflix早就发布了最新的 Zuul 2.x,
但 Spring Cloud 貌似没有整合计划。而且Netflix相关组件都宣布进入维护期;不知前景如何?
多方面综合考虑Gateway是很理想的网关选择。SpringCloud Gateway具有如下特性
1
2
3
4
5
6
7
8基于Spring Framework 5, Project Reactor 和 Spring Boot 2.0 进行构建;
动态路由:能够匹配任何请求属性;
可以对路由指定 Predicate(断言)和 Filter(过滤器);
集成Hystrix的断路器功能;
集成 Spring Cloud 服务发现功能;
易于编写的 Predicate(断言)和 Filter(过滤器);
请求限流功能;
支持路径重写。SpringCloud Gateway 与 Zuul的区别
1
2
3
4
5
6
7
8
9
10
11在SpringCloud Finchley 正式版之前,Spring Cloud 推荐的网关是 Netflix 提供的Zuul:
1、Zuul 1.x,是一个基于阻塞 I/ O 的 API Gateway
2、Zuul 1.x 基于Servlet 2. 5使用阻塞架构它不支持任何长连接(如 WebSocket) Zuul 的设计模式和Nginx较像,每次 I/ O 操作都是从工作线程中选择一个执行,请求线程被阻塞到工作线程完成,但是差别是Nginx 用C++ 实现,Zuul 用 Java 实现,而 JVM 本身会有第一次加载较慢的情况,使得Zuul 的性能相对较差。
3、Zuul 2.x理念更先进,想基于Netty非阻塞和支持长连接,但SpringCloud目前还没有整合。 Zuul 2.x的性能较 Zuul 1.x 有较大提升。在性能方面,根据官方提供的基准测试, Spring Cloud Gateway 的 RPS(每秒请求数)是Zuul 的 1. 6 倍。
4、Spring Cloud Gateway 建立 在 Spring Framework 5、 Project Reactor 和 Spring Boot 2 之上, 使用非阻塞 API。
5、Spring Cloud Gateway 还 支持 WebSocket, 并且与Spring紧密集成拥有更好的开发体验
zull1.x模型:
1 | Springcloud中所集成的Zuul版本,采用的是Tomcat容器,使用的是传统的Servlet IO处理模型。 |
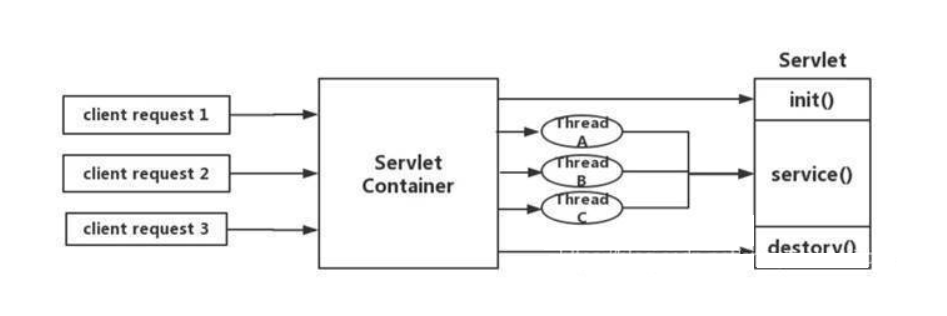
上述模式的缺点:
1 | servlet是一个简单的网络IO模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,在并发不高的场景下这种模型是适用的。但是一旦高并发(比如抽风用jemeter压),线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势 |
GateWay模型:
1、WebFlux是什么


说明:
1 | 传统的Web框架,比如说:struts2,springmvc等都是基于Servlet API与Servlet容器基础之上运行的。 |
2、三大核心概念
2.1、Route(路由)
路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
2.2、Predicate(断言)
参考的是Java8的java.util.function.Predicate
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由
2.3、Filter(过滤)
指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
2.4、总体
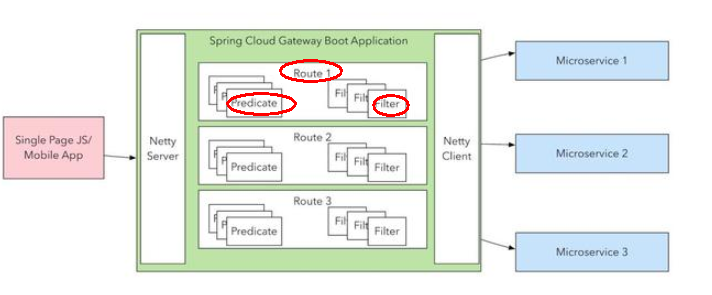
web请求,通过一些匹配条件,定位到真正的服务节点。并在这个转发过程的前后,进行一些精细化控制。
predicate就是我们的匹配条件;
而filter,就可以理解为一个无所不能的拦截器。有了这两个元素,再加上目标uri,就可以实现一个具体的路由了
3、GateWay工作流程
3.1、官网总结
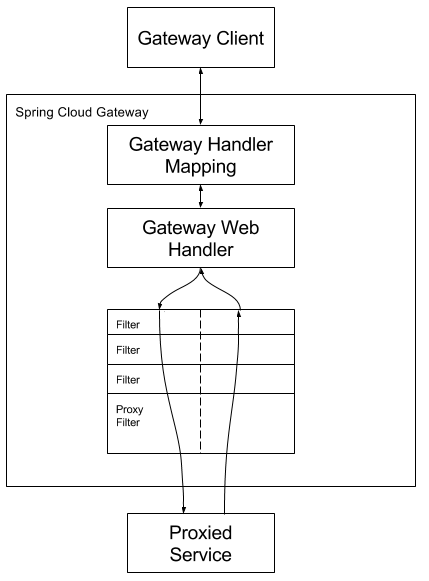
1 | 客户端向 Spring Cloud Gateway 发出请求。然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。 |
3.2、核心逻辑
路由转发+执行过滤器链
4、入门配置
4.1、新建cloud-gateway-gateway9527模块
4.2、修改pom文件
1 |
|
4.3、配置yml文件
1 |
|
4.4、编写主启动类
1 | package com.lxg.springcloud; |
4.5、如何才能做到路由映射呢?
cloud-provider-payment8001看看controller的访问地址:get和lb
我们目前不想暴露8001端口,希望在8001外面套一层9527
4.6、yml新增网关配置
1 |
|
4.7、测试
启动7001、8001(cloud-provider-payment8001)
启动9527
访问:
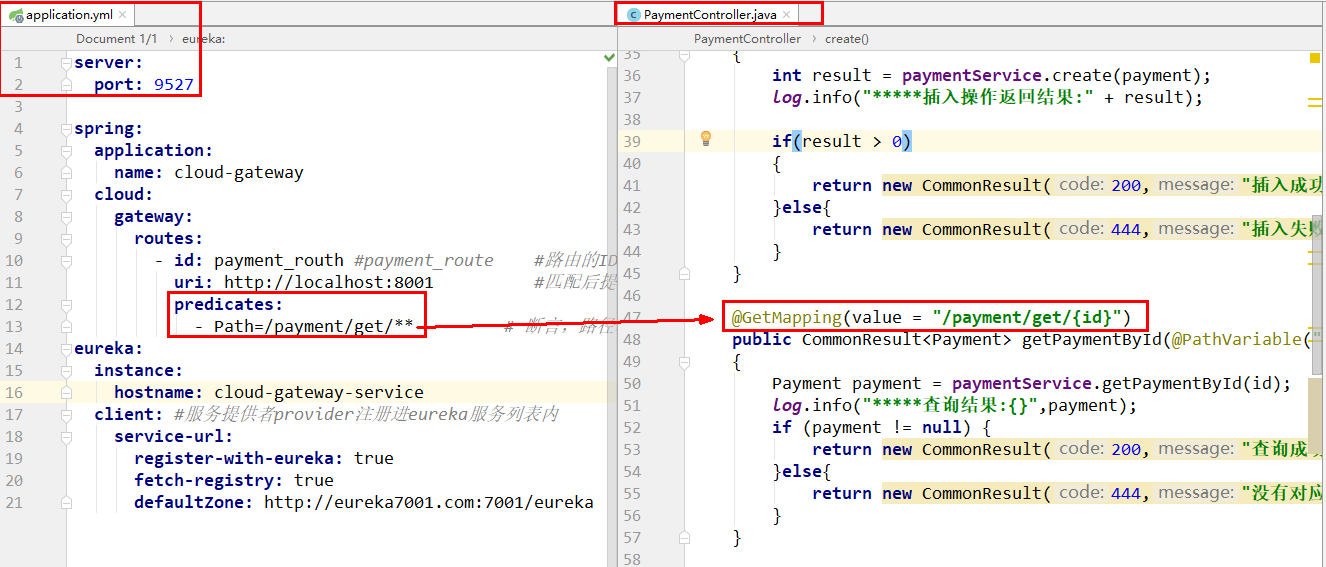
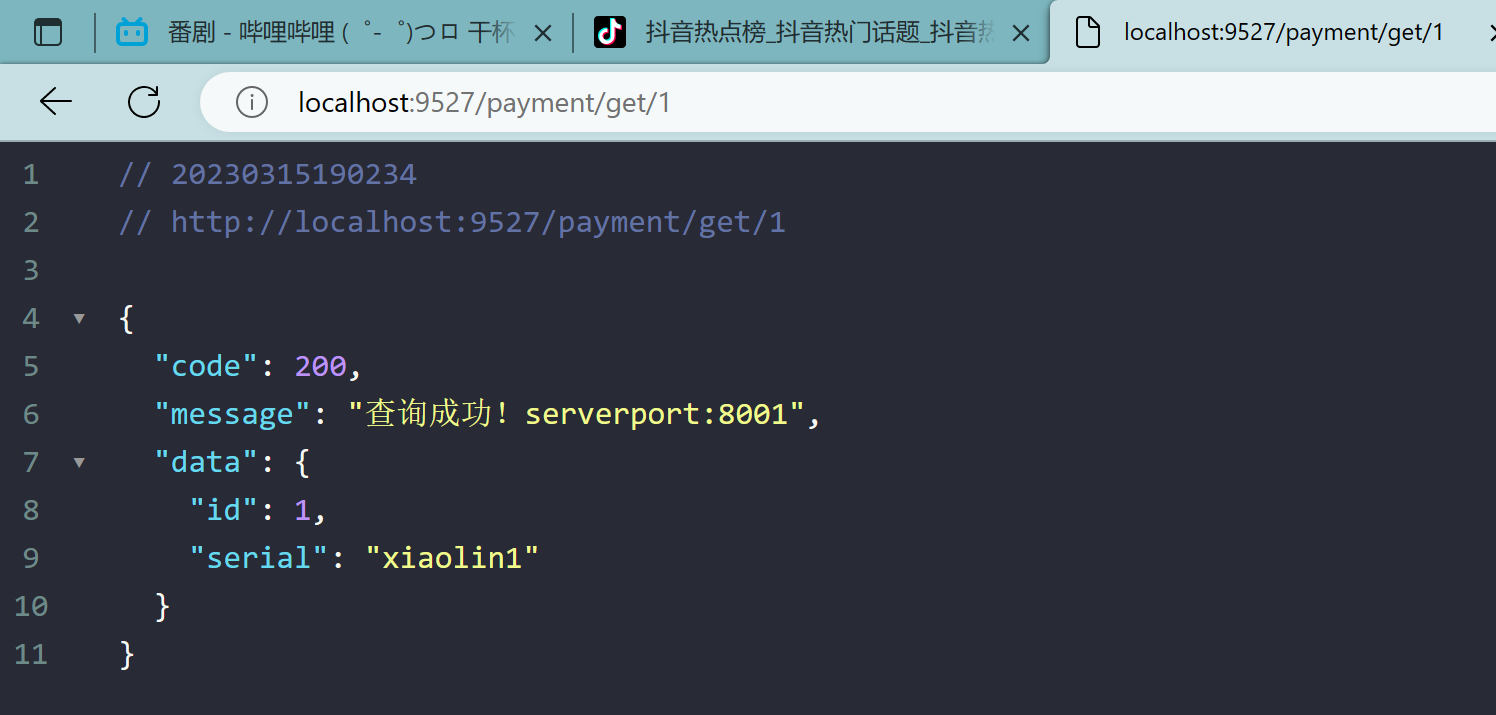

4.8、配置说明
Gateway网关路由有两种配置方式:
在yml配置文件中配置(以上以演示过)
编写配置类进行注入Bean
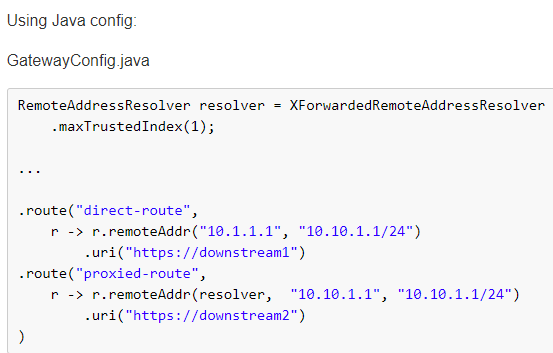
官网案例:
自己写一个:
映射到bilibili热门页面
编码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33package com.lxg.springcloud.config;
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @auther xiaolin
* @creatr 2023/3/15 17:44
*/
public class GateWayConfig {
/**
* 配置了一个id为path_route_xiaolin的路由规则
* 当访问http://localhost:9527/anime时会转发到地址:https://www.bilibili.com/anime/
* @param routeLocatorBuilder
* @return
*/
public RouteLocator customRouteLocator(RouteLocatorBuilder routeLocatorBuilder){
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
//https://www.bilibili.com/anime/
routes.route("path_route_xiaolin",
r -> r.path("/anime")
.uri("https://www.bilibili.com/anime/"))
.build();
return routes.build();
}
}
5、通过服务名实现动态路由
默认情况下Gateway会根据注册中心注册的服务列表,以注册中心上微服务名为路径创建动态路由进行转发,从而实现动态路由的功能
5.1、pom文件
pom文件必须要有以下依赖:可以将9527注册进去
1 |
|
5.2、yml文件
需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。
lb://serviceName是spring cloud gateway在微服务中自动为我们创建的负载均衡uri
1 |
|
5.3、测试
会在8001和8002中进行轮询
5.4、如何更换负载均衡策略?
xxx
5.5、网关、nginx、ribbon(loadbalancer)三个负载均衡的关系
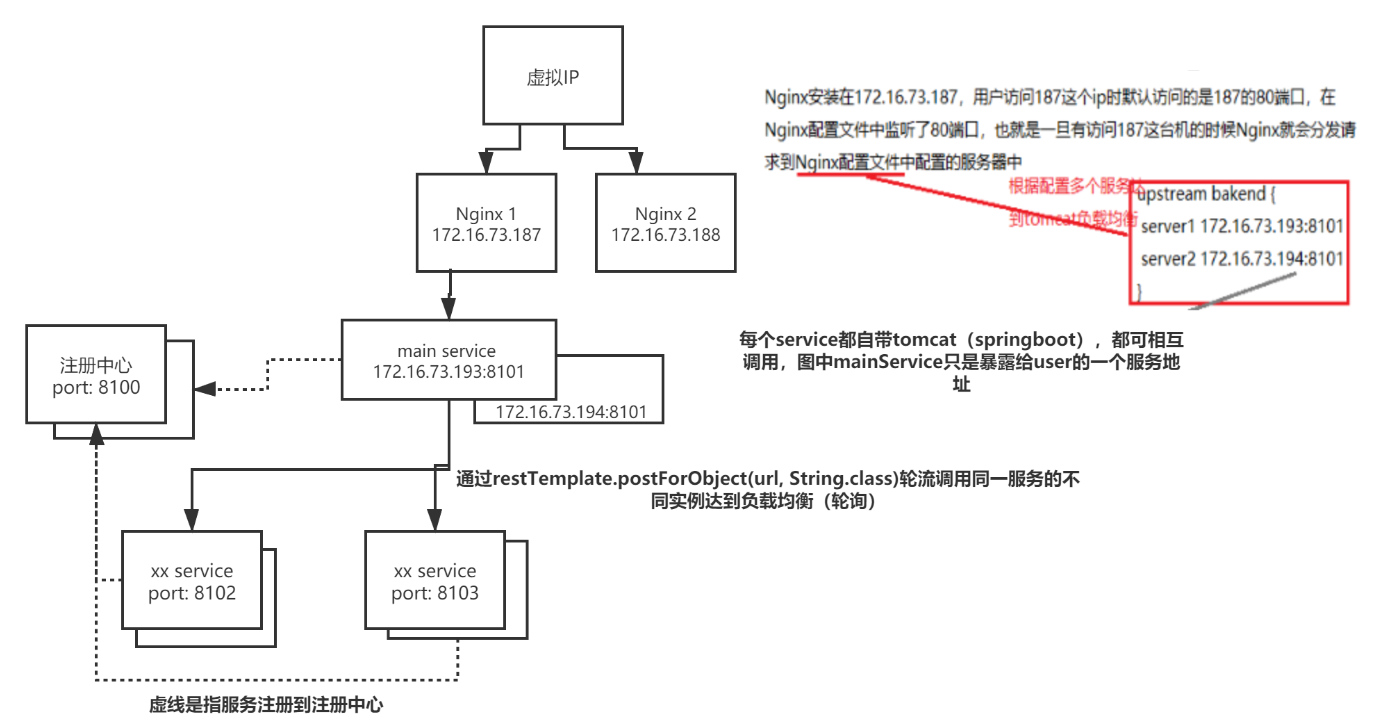
1 | 请求打到nginx 进行负载均衡 选择 网关服务器 然后 网关也会进行负载均衡 去注册中心找服务, 然会使用ribbon进行负载均衡 选择调用一个接口 |

gateway和nginx网关的区别
网关可以看做系统与外界联通的入口,我们可以在网关进行处理一些非业务逻辑的逻辑,比如权限验证,监控,缓存,请求路由等等。
gateway 是前端工程 到 后台服务器之间的一个 对内网关
nginx是用户到 前端工程 的网关,对外网关
Nginx在其中扮演的角色是什么?
- 反向代理
- 负载均衡
SpringGateway在其中扮演的角色是什么?
- 统一鉴权
6、Predicate的使用
6.1、是什么
启动9527查看日志:
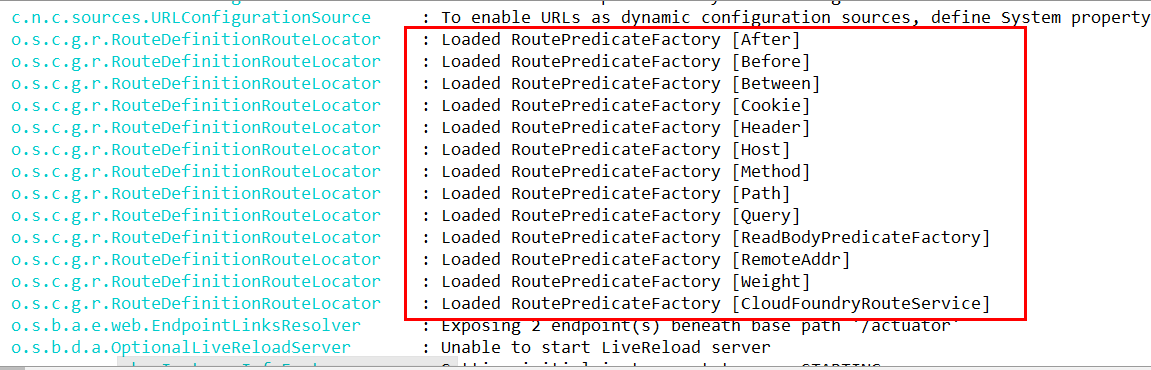
Route Predicate Factories这个是什么东东?
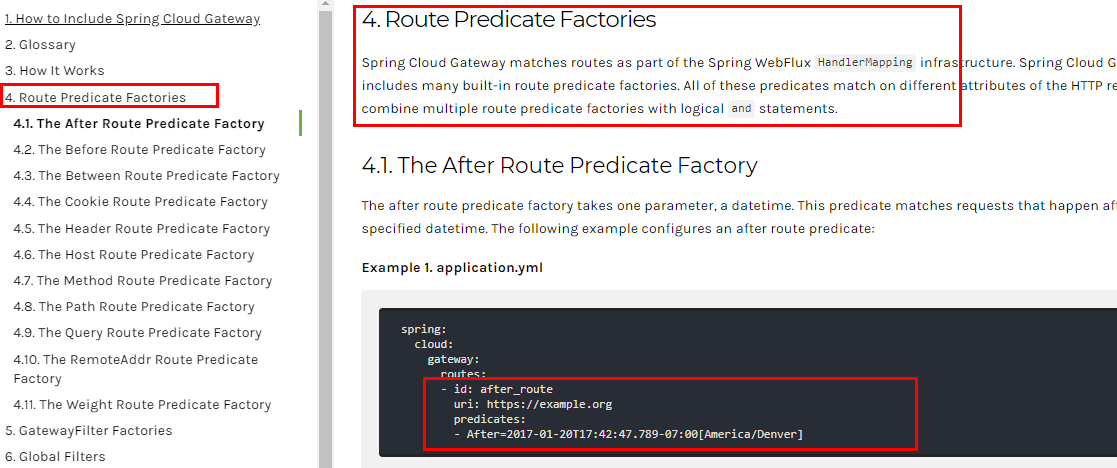
Spring Cloud Gateway将路由匹配作为Spring WebFlux HandlerMapping基础架构的一部分。
Spring Cloud Gateway包括许多内置的Route Predicate工厂。所有这些Predicate都与HTTP请求的不同属性匹配。多个Route Predicate工厂可以进行组合
Spring Cloud Gateway 创建 Route 对象时, 使用 RoutePredicateFactory 创建 Predicate 对象,Predicate 对象可以赋值给 Route。 Spring Cloud Gateway 包含许多内置的Route Predicate Factories。
所有这些谓词都匹配HTTP请求的不同属性。多种谓词工厂可以组合,并通过逻辑and。
6.2、常用的Route Predicate
6.2.1、After Route Predicate
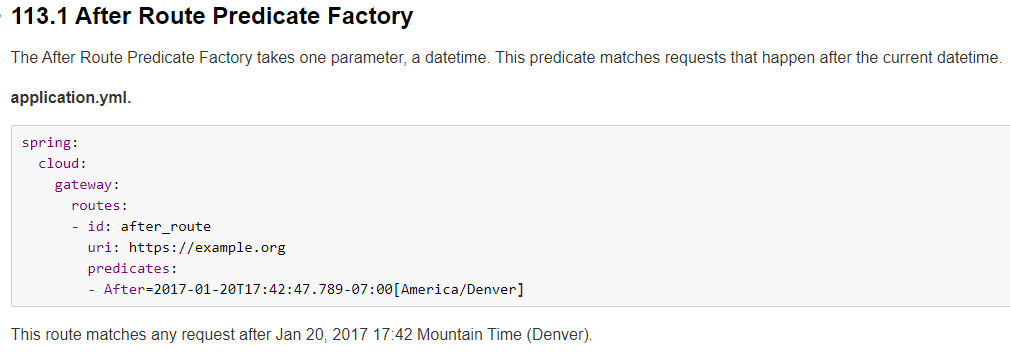
上述这个After好懂,这个时间串串???怎么写
1 | public class ZonedDateTimeDemo |
6.2.2、Before Route Predicate
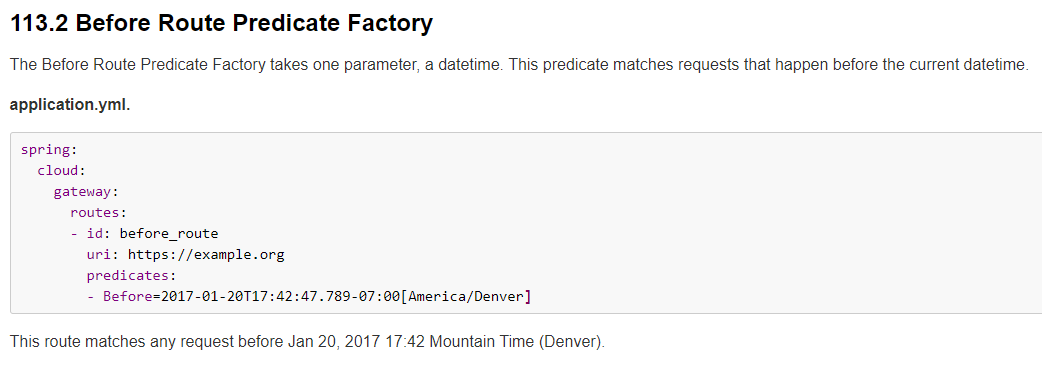
6.2.3、Between Route Predicate
6.2.4、Cookie Route Predicate
curl http://localhost:9527/payment/lb

curl http://localhost:9527/payment/lb –cookie “username=zzyy”

curl乱码:
https://blog.csdn.net/leedee/article/details/82685636
6.2.5、Header Route Predicate
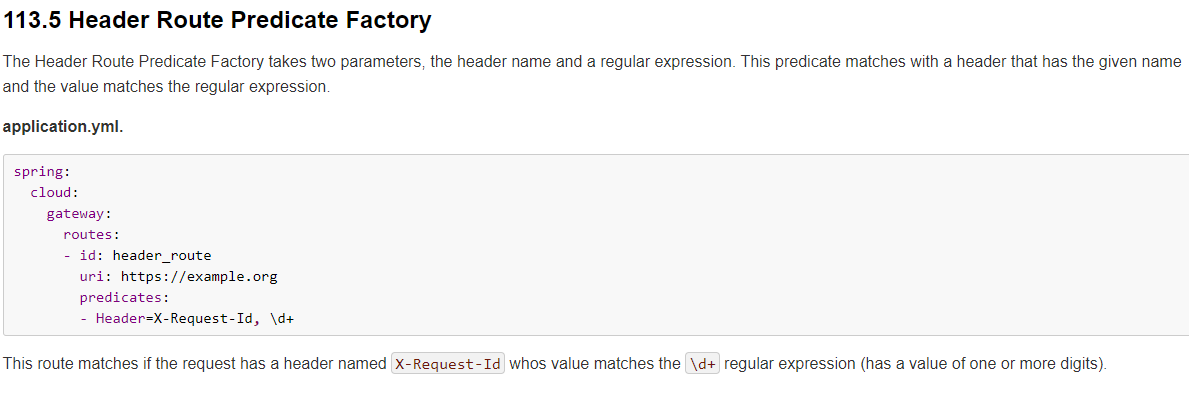
两个参数:一个是属性名称和一个正则表达式,这个属性值和正则表达式匹配则执行。
6.2.6、Host Route Predicate
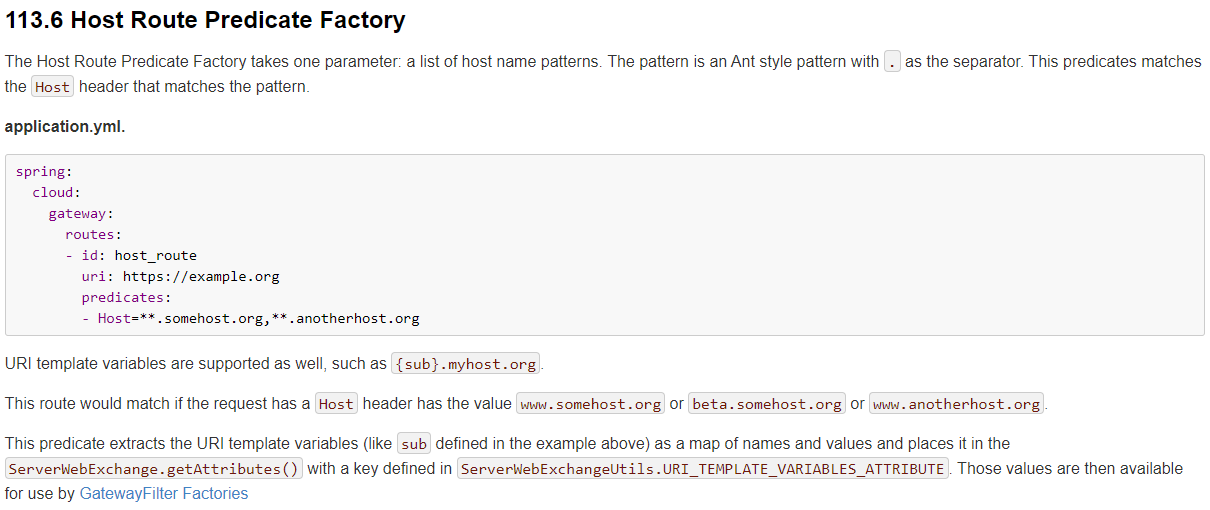
Host Route Predicate 接收一组参数,一组匹配的域名列表,这个模板是一个 ant 分隔的模板,用.号作为分隔符。
它通过参数中的主机地址作为匹配规则。
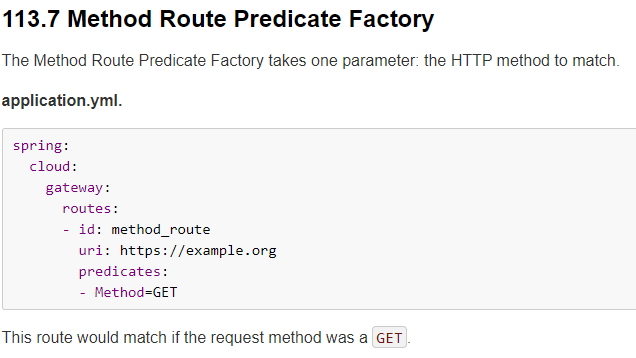
6.2.7、Method Route Predicate
6.2.8、Path Route Predicate

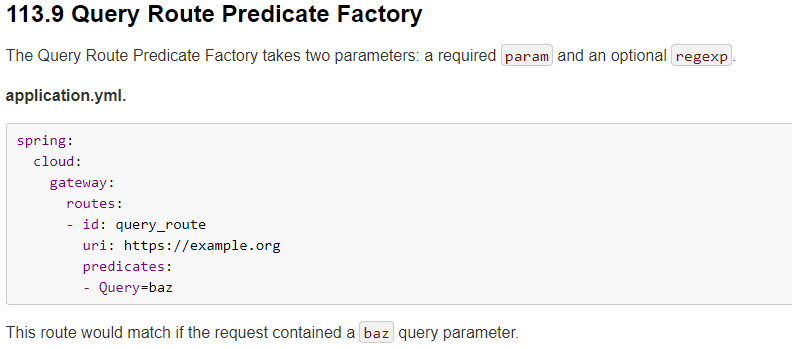
6.2.9、Query Route Predicate
6.2.10、小总结
1 | predicates: |
说白了,Predicate就是为了实现一组匹配规则,
让请求过来找到对应的Route进行处理。
目前新版的还有新的几个配置:
RemoteAddr Route Predicate:

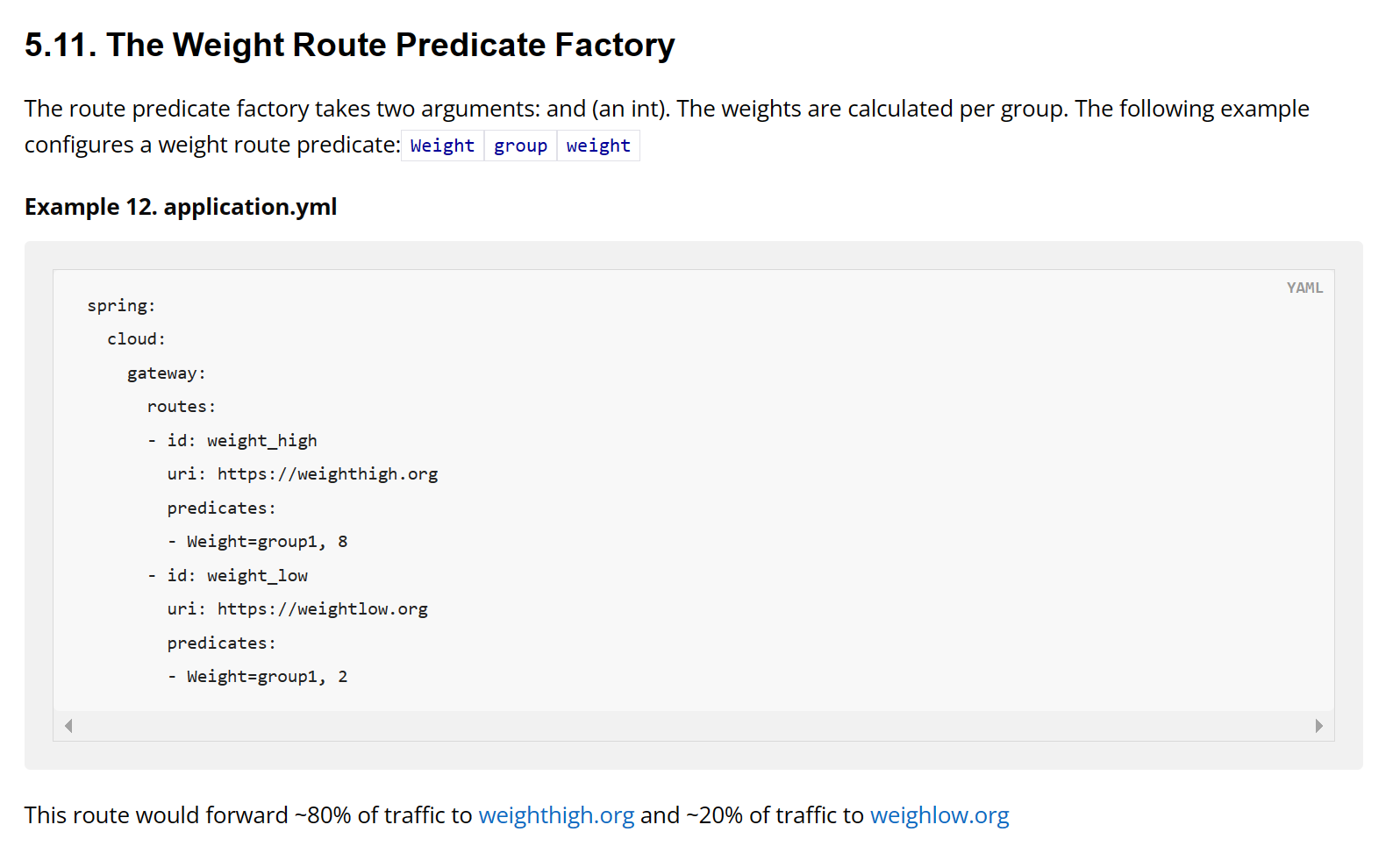
Weight Route Predicate:
XForwarded Remote Addr Route Predicate:
7、Filter的使用
7.1、是什么
1 | 路由过滤器可用于修改进入的HTTP请求和返回的HTTP响应,路由过滤器只能指定路由进行使用。 |
7.2、Spring Cloud Gateway的Filter
7.2.1、生命周期
pre和post
7.2.2、种类(两种)
GatewayFilter :
34种之多
GlobalFilter:

使用方法和作用自行查看官网文档:
7.3、常用的GateWayFilter
AddRequestParameter:
1 | spring: |
需要请求参数red=blue才可以通过
7.4、自定义过滤器
7.4.1、自定义全局GlobalFilter
两个主要接口介绍:implements GlobalFilter,Ordered
7.4.2、能干嘛:
全局日志记录
统一网关鉴权
…….
7.4.3、案例代码
1 | package com.lxg.springcloud.filter; |
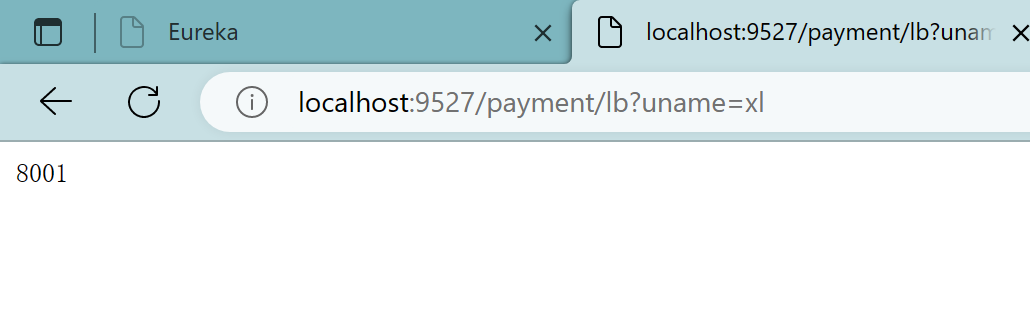
7.4.4、测试
启动7001、8001、8002、9527
localhost:9527/payment/lb?uname=xl
十四、springcloud Config分布式配置中心
1、概述
1.1、当前分布式系统存在的配置问题
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。
SpringCloud提供了ConfigServer来解决这个问题(我们每一个微服务自己带着一个application.yml,上百个配置文件的管理……
/(ㄒoㄒ)/~~)
1.2、是什么
1 | 是什么 |
1.3、能干嘛
集中管理配置文件
不同环境不同配置,动态化的配置更新,分环境部署比如dev/test/prod/beta/release
运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置
将配置信息以REST接口的形式暴露
post、curl访问刷新均可……
1.4、与GitHub整合配置
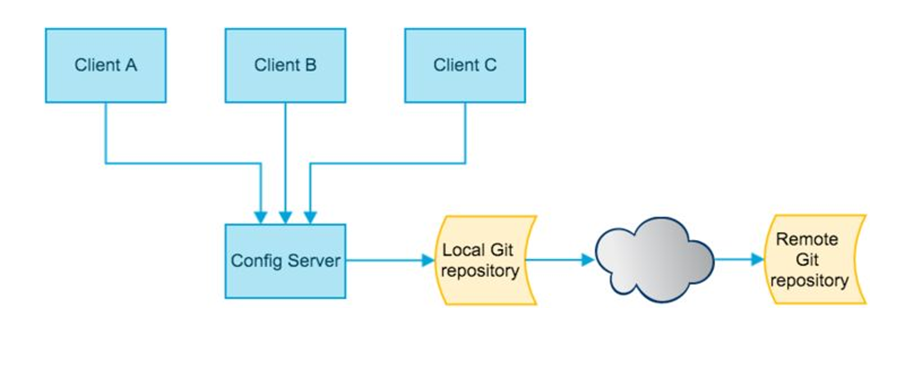
由于SpringCloud Config默认使用Git来存储配置文件(也有其它方式,比如支持SVN和本地文件),
但最推荐的还是Git,而且使用的是http/https访问的形式
1.5、官网
2、Config服务端配置与测试
2.1、github上创建一个名为springcloud-config的仓库
2.1.1、获取git地址
git@github.com:linXiao01/springcloud-config.git
2.2、在磁盘目录新建git仓库并clone
git clone git@github.com:linXiao01/springcloud-config.git
2.3、修改
如果需要修改,此处模拟运维人员操作git和github:
1 | git add |
2.4、新建Module模块cloud-config-center-3344
它即为Cloud的配置中心模块cloudConfig Center
2.5、修改pom文件
1 |
|
2.6、修改yml文件
1 | server: |
2.7、主启动类
1 | package com.lxg.springcloud; |
2.8、windows下修改host文件,增加映射
127.0.0.1 config-3344.com
2.9、测试
启动3344
config-3344.com:3344/main/config-dev.yml
2.10、配置读取规则
2.10.1、官网
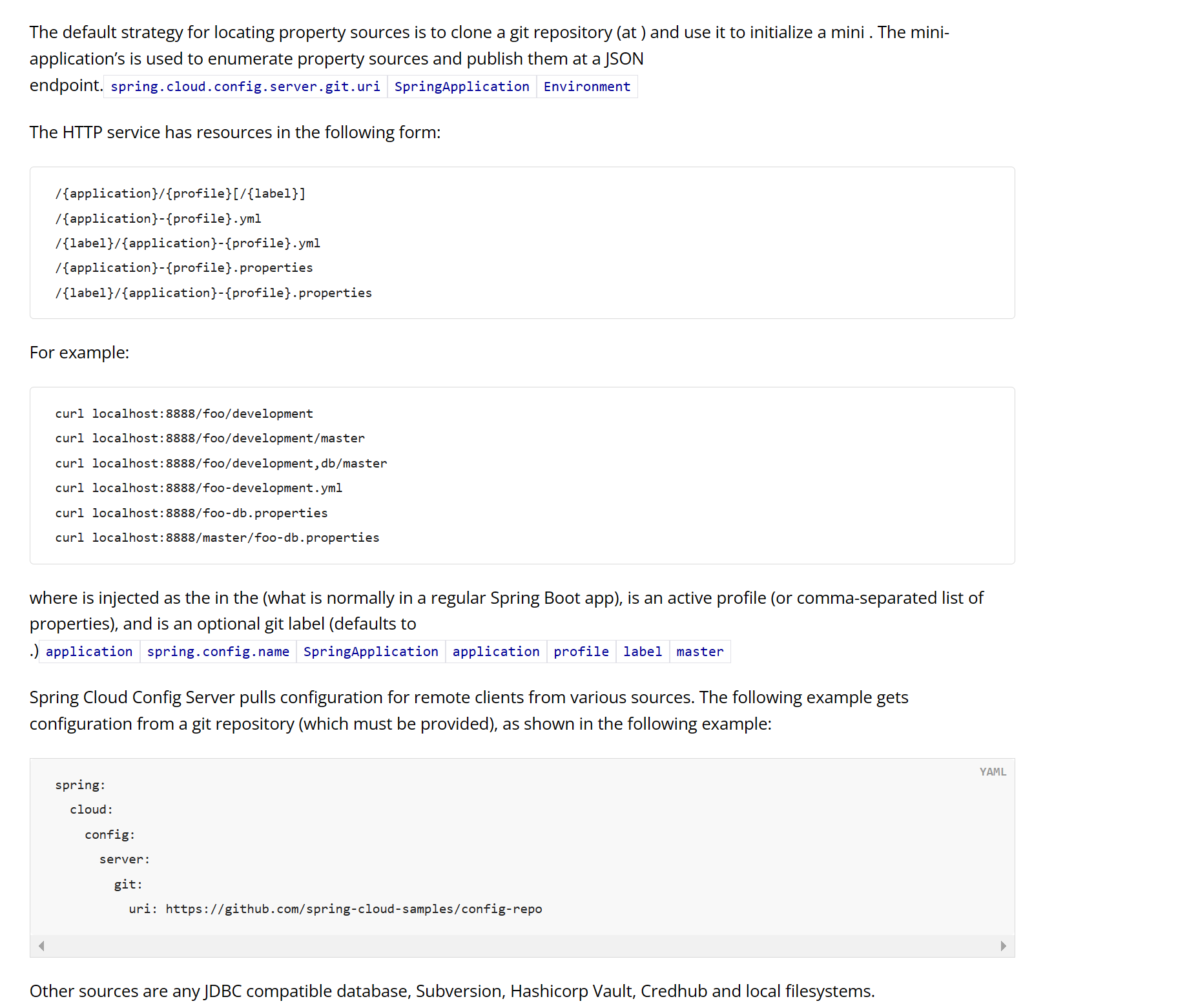
2.10.2、/{application}/{profile}[/{label}]
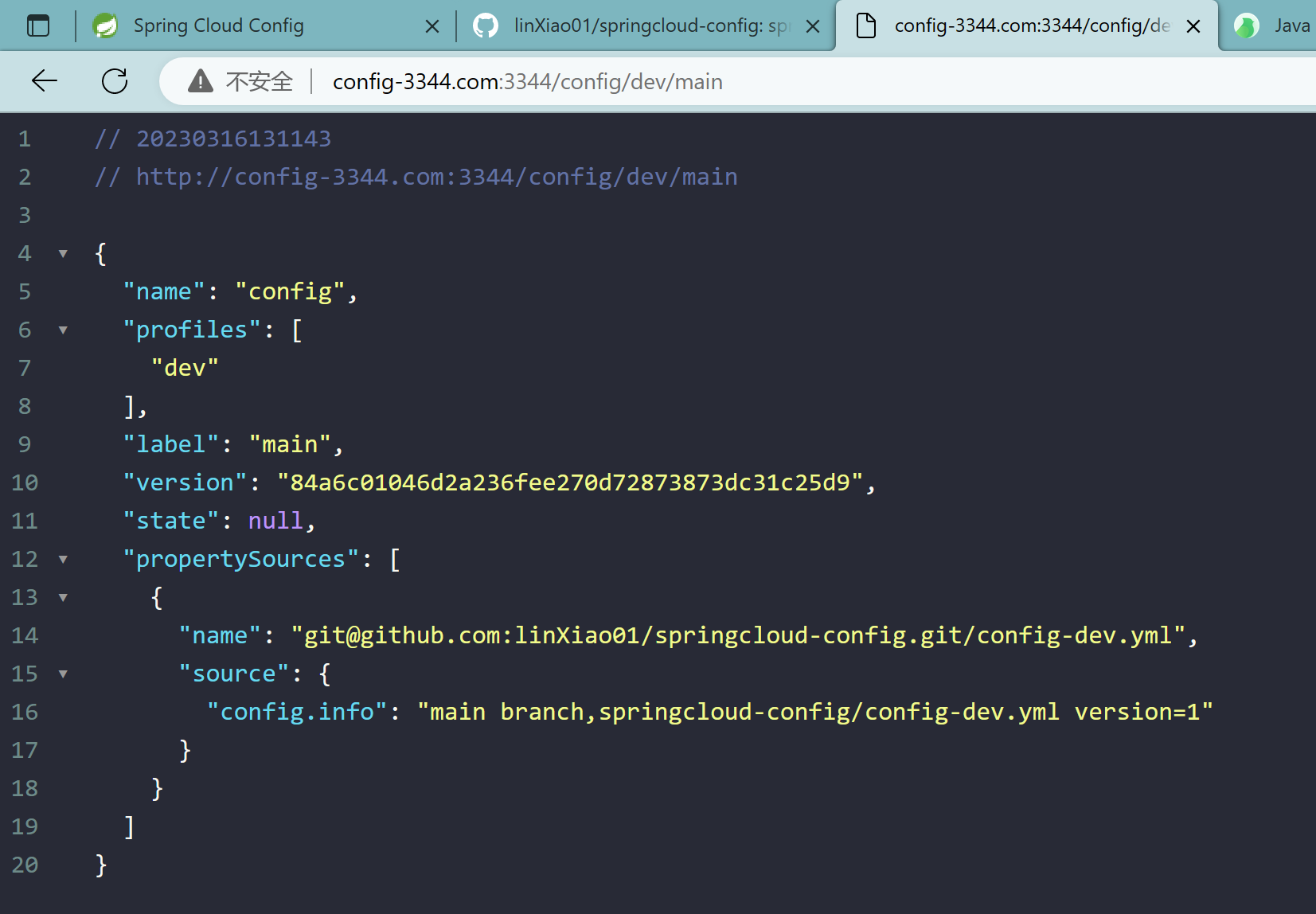
config-3344.com:3344/config/dev/main
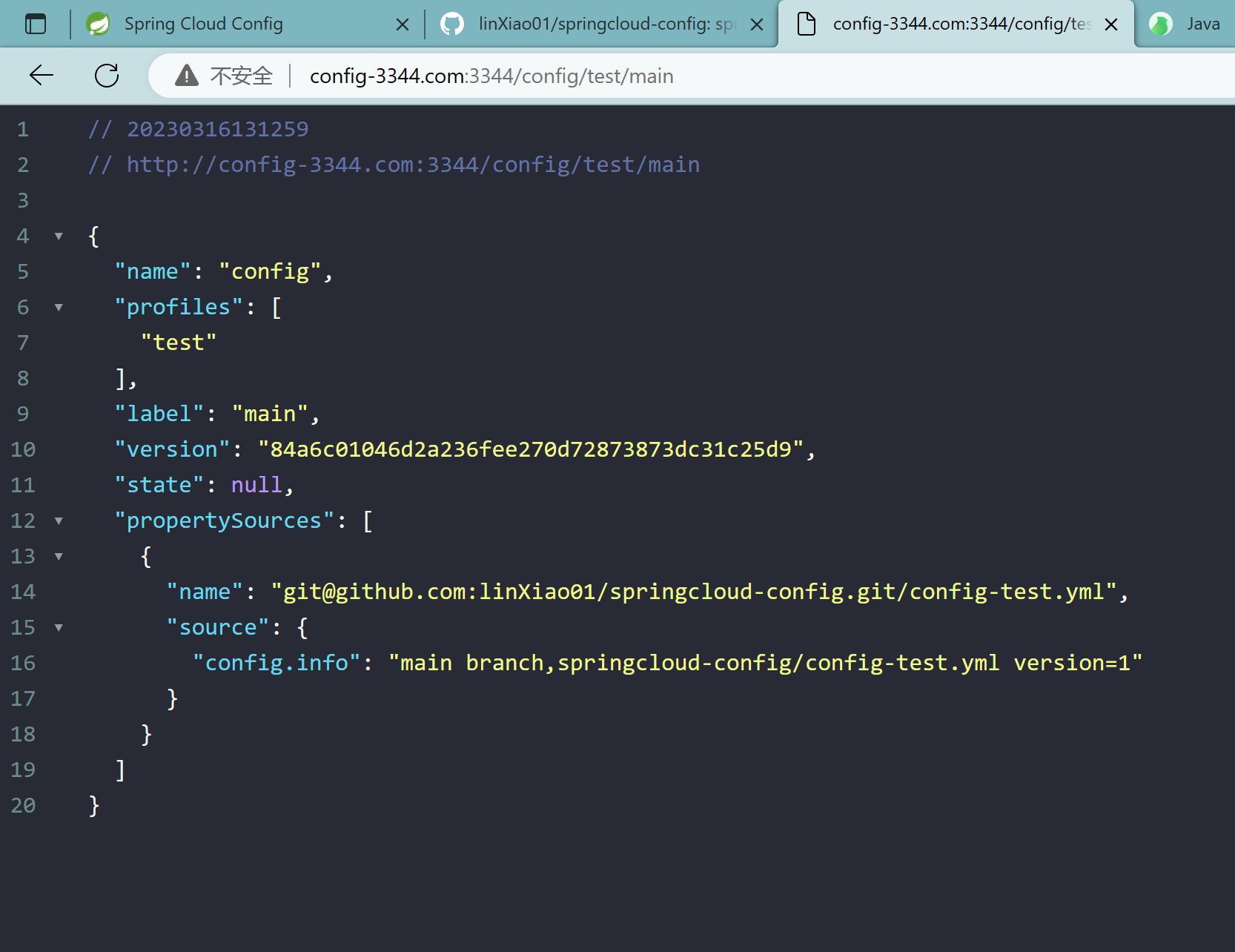
config-3344.com:3344/config/test/main
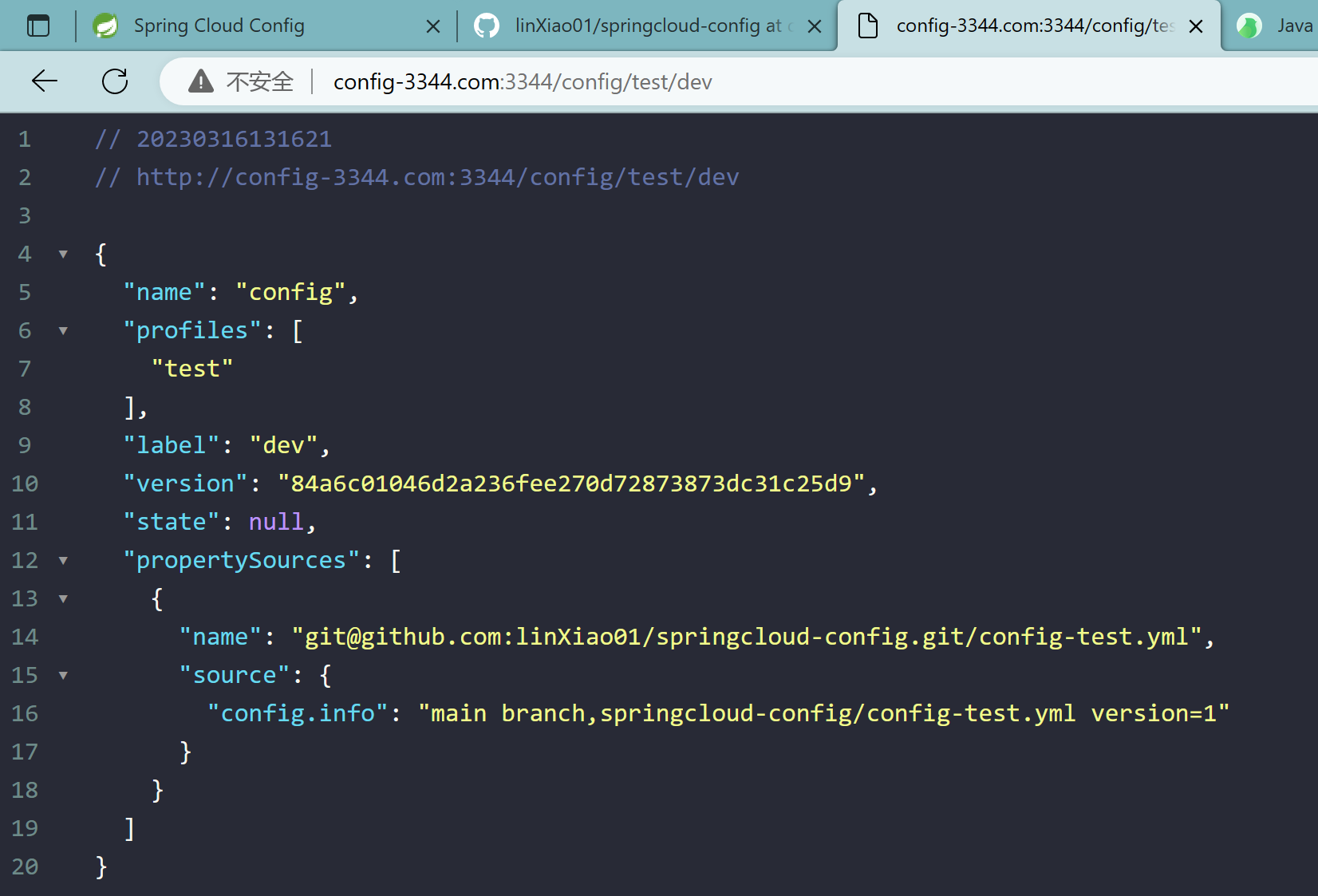
config-3344.com:3344/config/test/dev
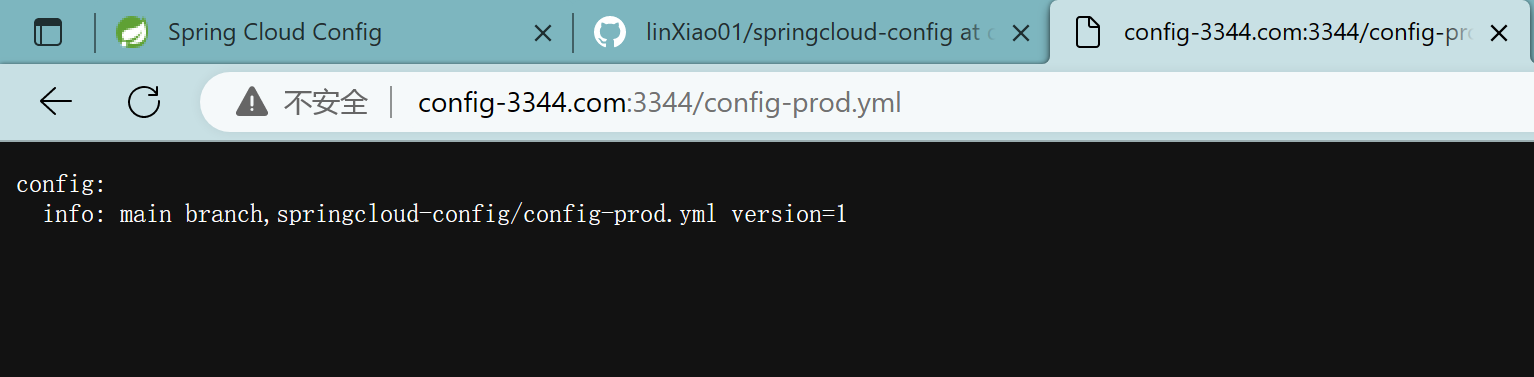
2.10.3、/{application}-{profile}.yml
config-3344.com:3344/config-prod.yml
访问不存在的配置:
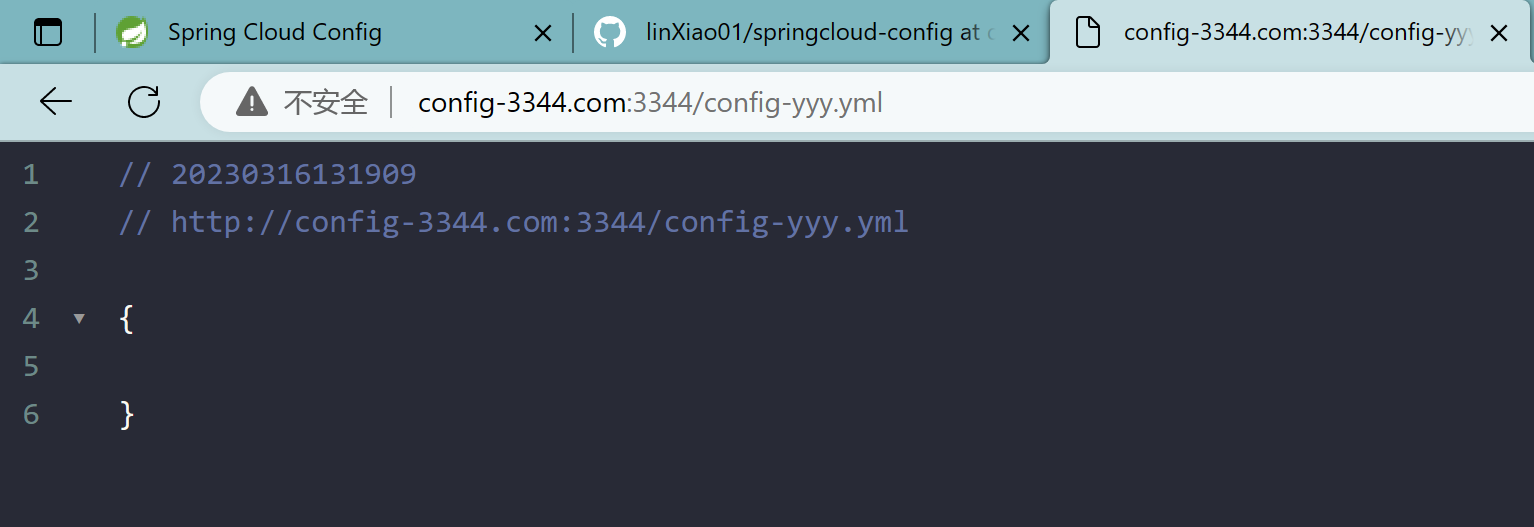
2.10.4、/{label}/{application}-{profile}.yml
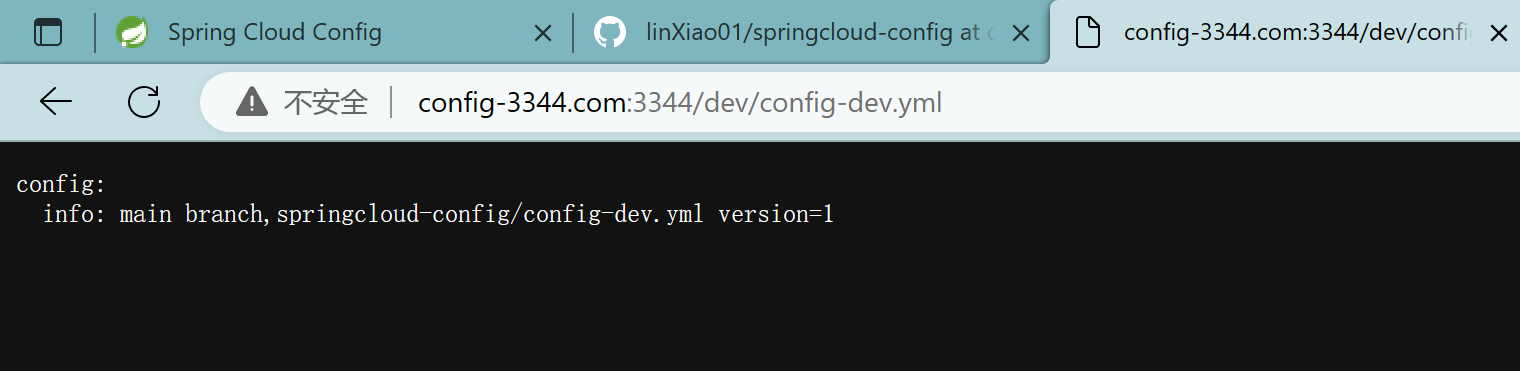
config-3344.com:3344/main/config-dev.yml

config-3344.com:3344/dev/config-dev.yml
2.10.5、重要配置细节总结
/{name}-{profiles}.yml
/{label}/{name}-{profiles}.yml
label:分支(branch)
name :服务名
profiles:环境(dev/test/prod)
以上成功实现了用SpringCloud Config通过GitHub获取配置信息,另外两个获取路径也是一样!
3、Config客户端配置与测试
3.1、新建cloud-config-client-3355
3.2、修改pom文件
1 |
|
新版的SpringBoot一定要加上最后的bootstrap依赖,否则会报错!!!
3.3、编写bootstrap.yml文件
3.3.1、是什么
1 |
|
3.3.2、内容
1 | server: |
3.3.3、说明

3.4、编写主启动类
1 | package com.lxg.springcloud; |
3.5、编写业务类
1 | package com.lxg.springcloud.controller; |
3.6、测试
config-3344.com:3344/main/config-dev.yml
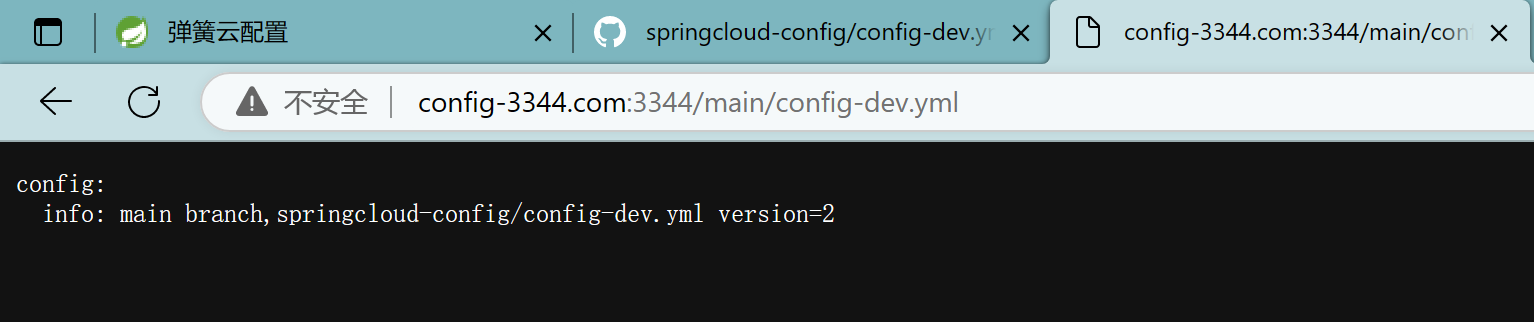

成功实现了客户端3355访问SpringCloud Config3344通过GitHub获取配置信息
3.7、问题
1 | Linux运维修改GitHub上的配置文件内容做调整 |
4、Config客户端之动态刷新
避免每次更新配置都要重启客户端微服务3355
4.1、修改3355pom
引入actutor监控
1 |
|
4.2、修改yml,暴露监控端口
1 | server: |
4.3、@RefreshScope业务类Controller修改
1 | package com.lxg.springcloud.controller; |
4.4、访问
3344可以正常更新
但是3355依然不能
4.5、怎么做
需要运维人员发送Post请求刷新3355
必须是POST请求
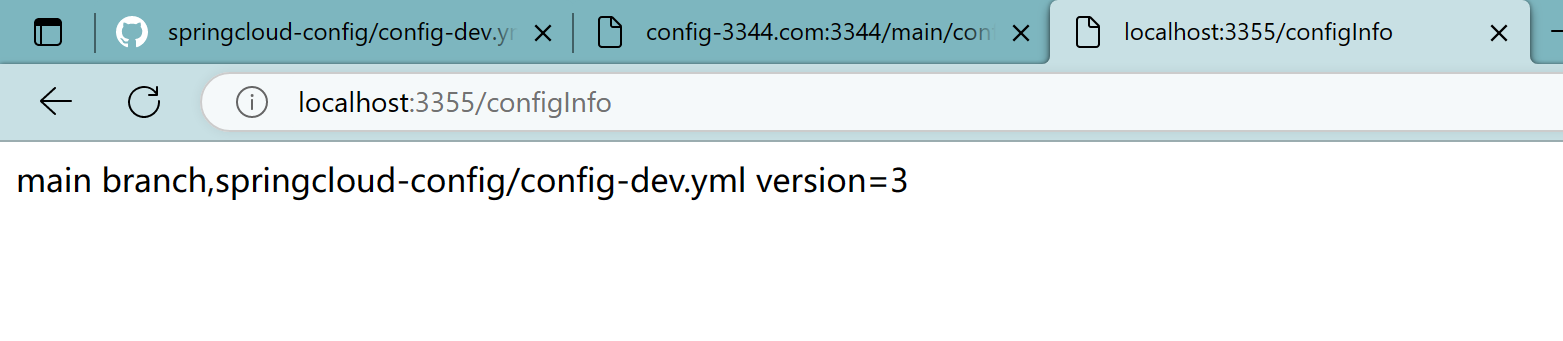
curl -X POST “http://localhost:3355/actuator/refresh“
4.6、再次访问

成功实现了客户端3355刷新到最新配置内容
4.7、还有什么问题
- 假如有多个微服务客户端3355/3366/3377
- 每个微服务都要执行一次post请求,手动刷新?
- 可否广播,一次通知,处处生效?
- 我们想大范围的自动刷新,求方法?
十五、SpringCloud Bus 消息总线
1、概述
分布式自动刷新配置功能:Spring Cloud Bus 配合 Spring Cloud Config 使用可以实现配置的动态刷新。
1.1、是什么
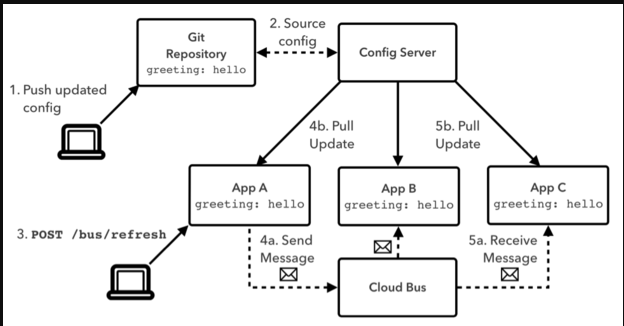
Spring Cloud Bus是用来将分布式系统的节点与轻量级消息系统链接起来的框架,
它整合了Java的事件处理机制和消息中间件的功能。
Spring Clud Bus目前支持RabbitMQ和Kafka。
1.2、能干嘛
Spring Cloud Bus能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改、事件推送等,也可以当作微服务间的通信通道。
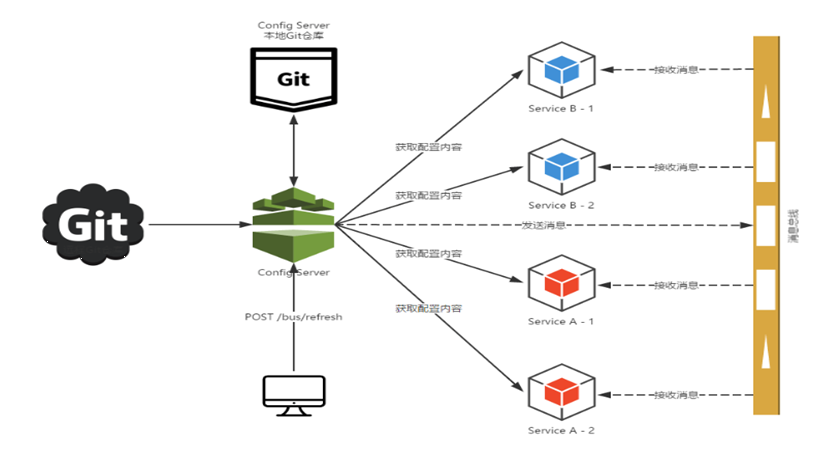
1.5、为何被称为总线
1 | 什么是总线 |
2、RabbitMQ环境配置
2.1、windows安装方法
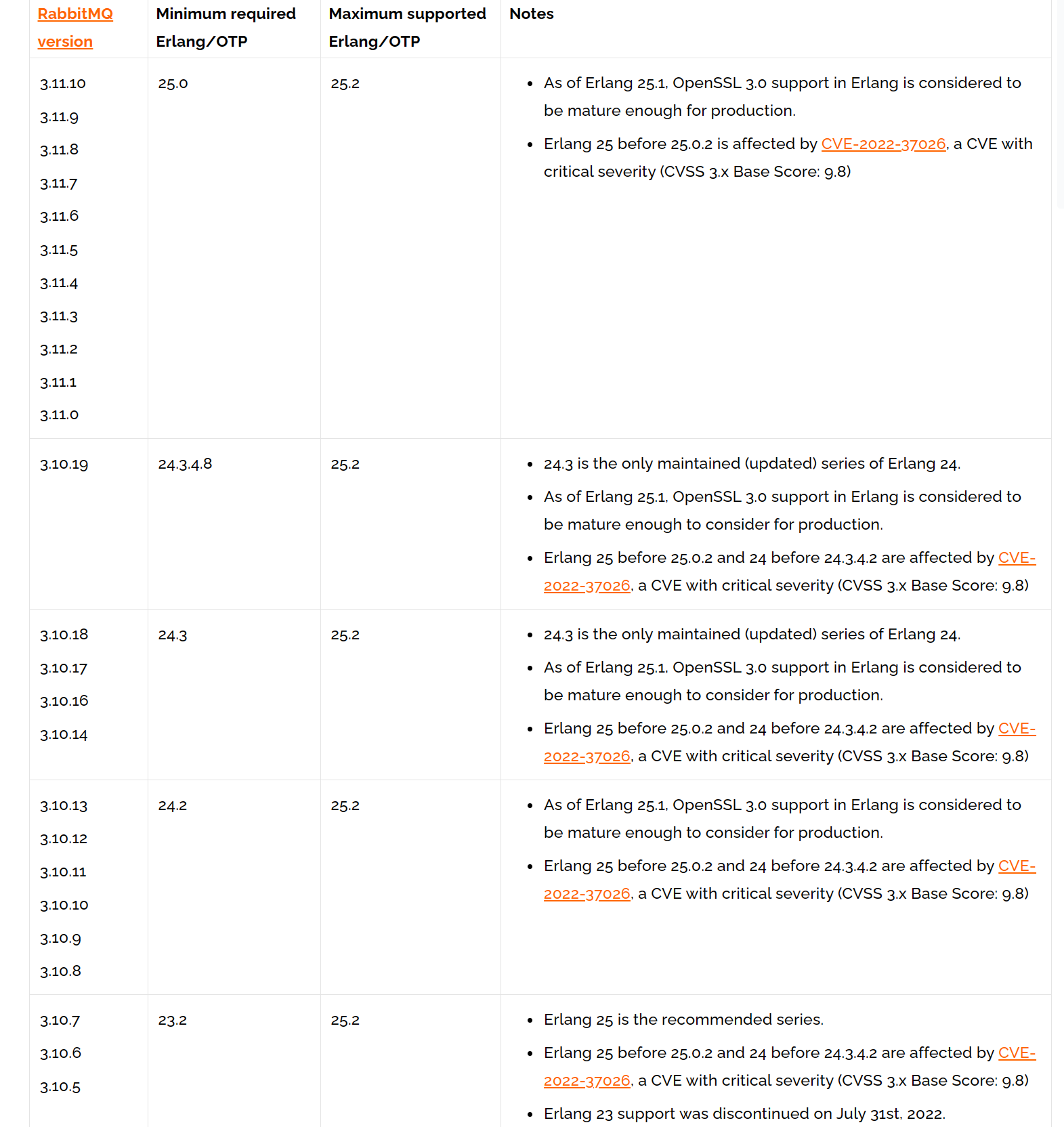
2.1.1、查看RabbitMQ和Erlang版本关系
RabbitMQ Erlang Version Requirements — RabbitMQ
2.1.2、安装Erlang环境
github:Release 25.2.1 · rabbitmq/erlang-rpm · GitHub
2.1.3、安装RabbitMQ
历史版本:https://www.rabbitmq.com/news.html
github:Releases · rabbitmq/rabbitmq-server (github.com)
最新版本:Installing on Windows Manually — RabbitMQ
2.1.4、安装后进行rabbitMQ安装目录的sbin
如:E:\software\RabbitMQ3.11.10\rabbitmq_server-3.11.10\sbin
2.1.5、命令cmd窗口打开,运行以下命令
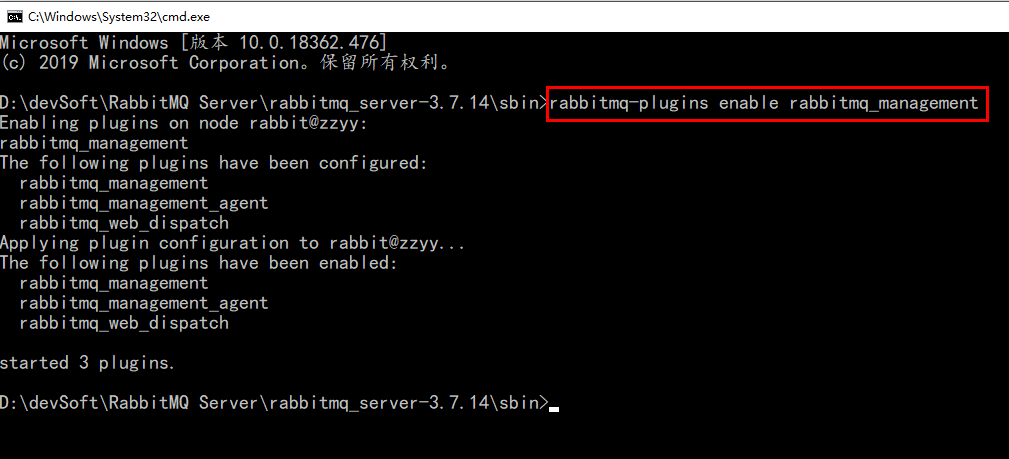
执行完毕会开始菜单会有以下内容:

对应下载,启动,停止,删除。
2.1.6、访问查看是否安装成功
默认账号密码:
guest guest
2.2、Linux系统安装
2.2.1、安装Erlang
rabbitmq/erlang - Packages · packagecloud
使用wegt命令进行安装:
1 | wget --content-disposition "https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-23.3.4.11-1.el7.x86_64.rpm/download.rpm?distro_version_id=140" |
2.2.2、安装RabbitMQ
https://packagecloud.io/rabbitmq/rabbitmq-server?page=23
2.2.3、具体教程
https://blog.csdn.net/m0_67392182/article/details/126040124
3、SpringCloud Bus动态刷新全局广播
以上配置完rabbitMQ环境后启动
3.1、以3355为模板新建一个3366模块
3.1.1、修改pom文件
1 |
|
3.1.2、修改yml文件(bootstrap)
1 | server: |
3.1.3、主启动类
1 | package com.lxg.springcloud; |
3.1.4、controller
1 | package com.lxg.springcloud.controller; |
特别注意@RefreshScope
3.2、设计思想
利用消息总线触发一个客户端/bus/refresh,而刷新所有客户端的配置
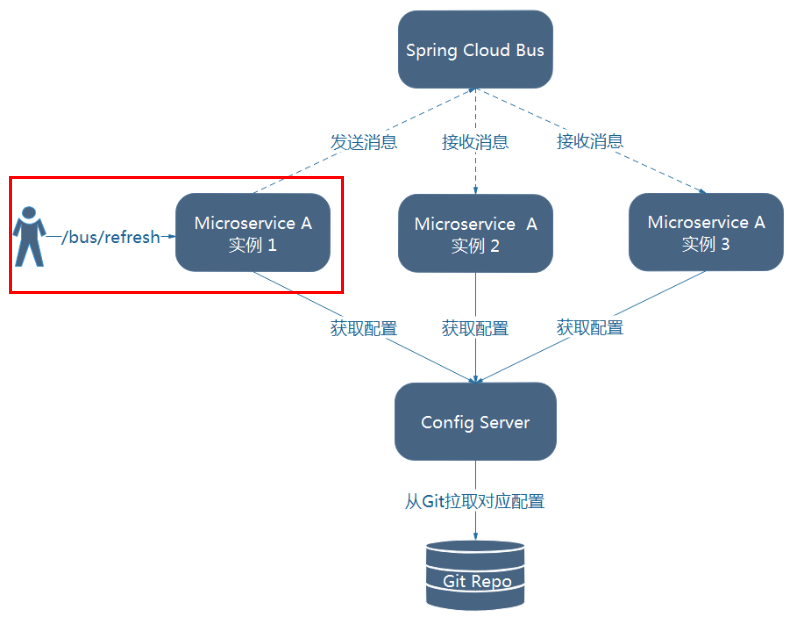
利用消息总线触发一个服务端ConfigServer的/bus/refresh端点,而刷新所有客户端的配置
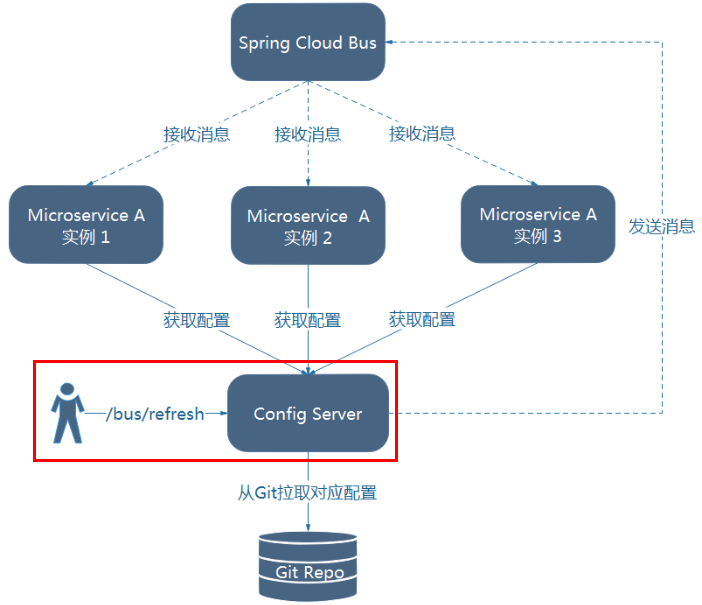
图二的架构显然更加适合,图一不适合的原因如下:
1 | 打破了微服务的职责单一性,因为微服务本身是业务模块,它本不应该承担配置刷新的职责。 |
3.3、给config3344配置中心增加消息总线支持
3.3.1、修改pom文件(添加)
1 |
|
3.3.2、修改yml文件
1 | server: |
3.4、修改3366
3.4.1、修改pom(添加)
1 | <!--添加消息总线RabbitMQ支持--> |
3.4.2、修改yml
1 | server: |
3.5、修改3355
3.5.1、修改pom(添加)
1 | <!--添加消息总线RabbitMQ支持--> |
3.5.2、修改yml
1 | server: |
3.6、测试
依次启动7001、3344、3355、3366
3.6.1、修改github上的版本号
3.6.2、发送post请求
新版
1 | curl -X POST "http://localhost:3344/actuator/busrefresh" |
老版
1 | curl -X POST "http://localhost:3344/actuator/bus-refresh" |
3.6.3、查看配置中心
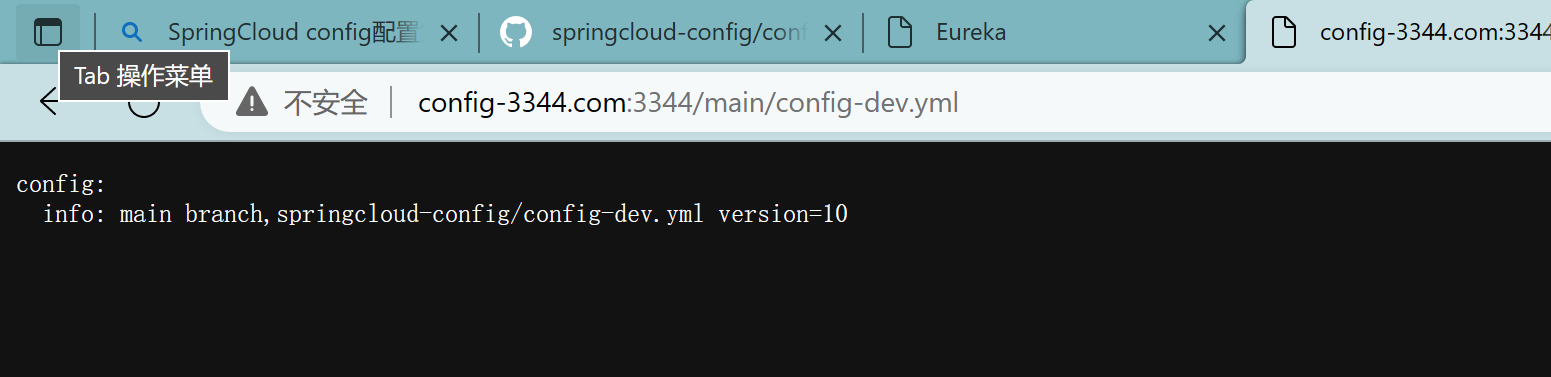
3.6.4、查看3355、3366
http://localhost:3355/configInfo
http://localhost:3366/configInfo
版本由9转为10,没有重新启动过

一次修改,广播通知,处处生效
4、SpringCloud Bus动态刷新定点通知
4.1、目的
只通知3355,不通知3366
指定具体某一个实例生效而不是全部
4.2、如何做
公式:http://localhost:配置中心的端口号/actuator/bus-refresh/{destination}
/bus/refresh请求不再发送到具体的服务实例上,而是发给config server并
通过destination参数类指定需要更新配置的服务或实例
4.3、刷新3355
curl -X POST “http://localhost:3344/actuator/bus-refresh/config-client:3355“

服务名:端口号
4.4、总结
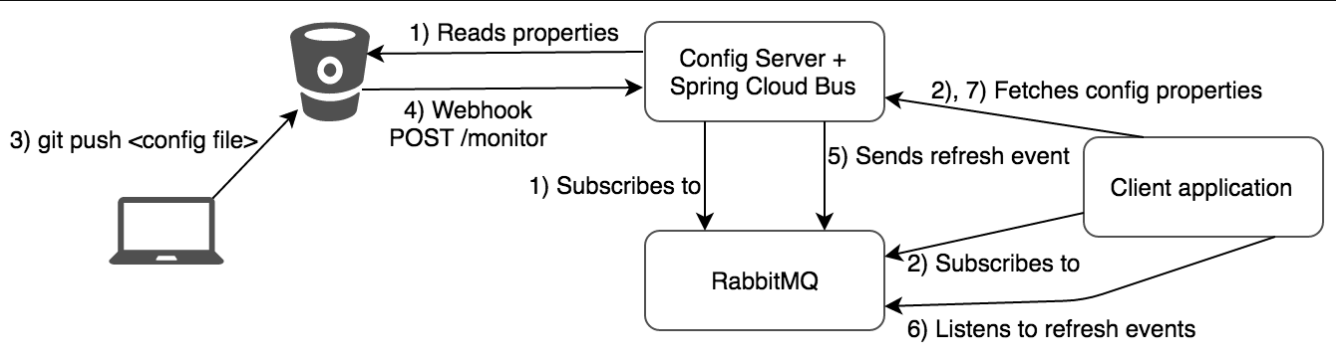
十六、SpringCloud Stream消息驱动
1、消息驱动概述
1.1、是什么
1.1.1、一句话
1 | 什么是SpringCloudStream |
1.1.2、官网
https://spring.io/projects/spring-cloud-stream#overview
Spring Cloud Stream是用于构建与共享消息传递系统连接的高度可伸缩的事件驱动微服务框架,该框架提供了一个灵活的编程模型,它建立在已经建立和熟悉的Spring熟语和最佳实践上,包括支持持久化的发布/订阅、消费组以及消息分区这三个核心概念
Spring Cloud Stream Reference Documentation
Spring Cloud Stream中文指导手册:https://m.wang1314.com/doc/webapp/topic/20971999.html
1.2、设计思想
1.2.1、标准MQ
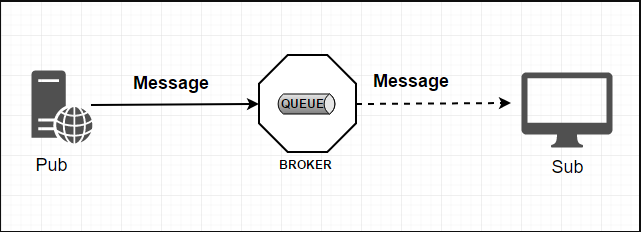
生产者/消费者之间靠消息媒介传递信息内容(Message)
消息必须走特定的通道(消息通道MessageChannel)
消息通道里的消息如何被消费呢,谁负责收发处理:消息通道MessageChannel的子接口SubscribableChannel,由MessageHandler消息处理器所订阅
1.2.2、为什么用Could Stream
比方说我们用到了RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同,
像RabbitMQ有exchange,kafka有Topic和Partitions分区
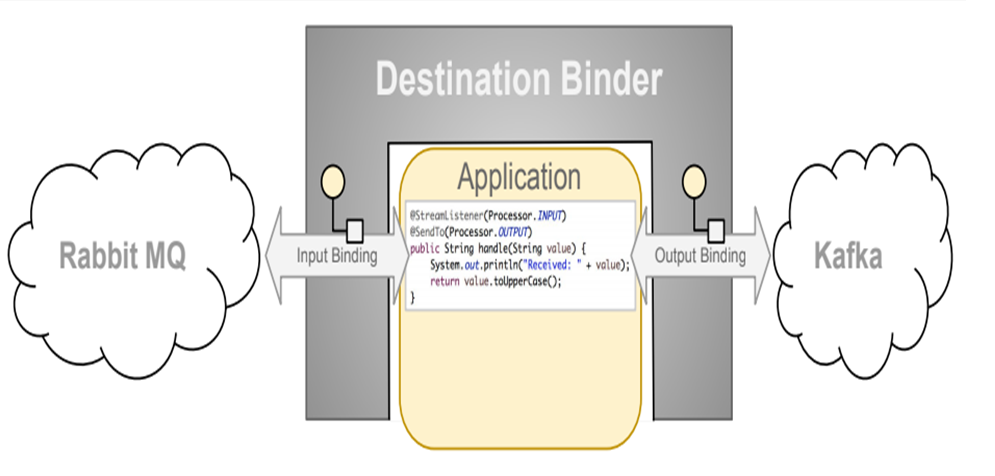
这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求,我想往另外一种消息队列进行迁移,这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这时候springcloud Stream给我们提供了一种解耦合的方式。
stream凭什么可以统一底层差异:
1 | 在没有绑定器这个概念的情况下,我们的SpringBoot应用要直接与消息中间件进行信息交互的时候, |
通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离。
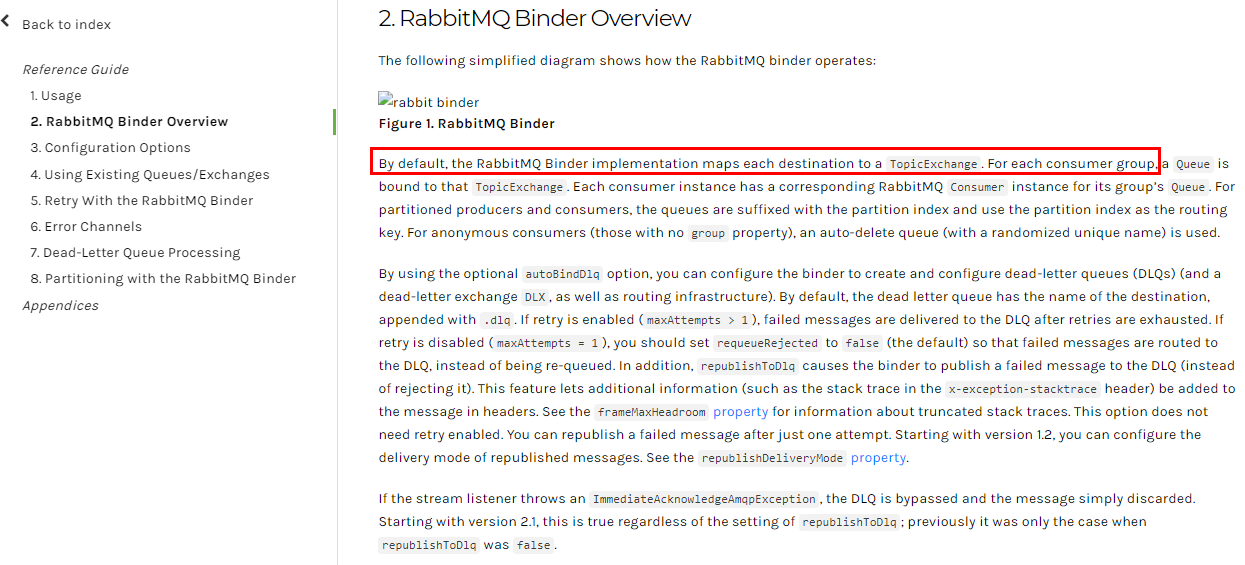
Binder:
在没有绑定器这个概念的情况下,我们的SpringBoot应用要直接与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现细节上会有较大的差异性,通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离。Stream对消息中间件的进一步封装,可以做到代码层面对中间件的无感知,甚至于动态的切换中间件(rabbitmq切换为kafka),使得微服务开发的高度解耦,服务可以关注更多自己的业务流程
通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离。
Binder可以生成Binding,Binding用来绑定消息容器的生产者和消费者,它有两种类型,INPUT和OUTPUT,INPUT对应于消费者,OUTPUT对应于生产者。
1.2.3、Stream中的消息通信方式遵循了发布-订阅模式
Topic主题进行广播:
在RabbitMQ就是Exchange,在Kakfa中就是Topic
1.3、Spring Cloud Stream标准流程套路
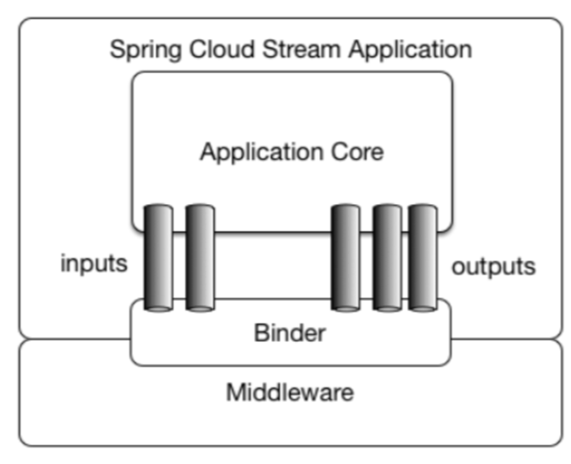
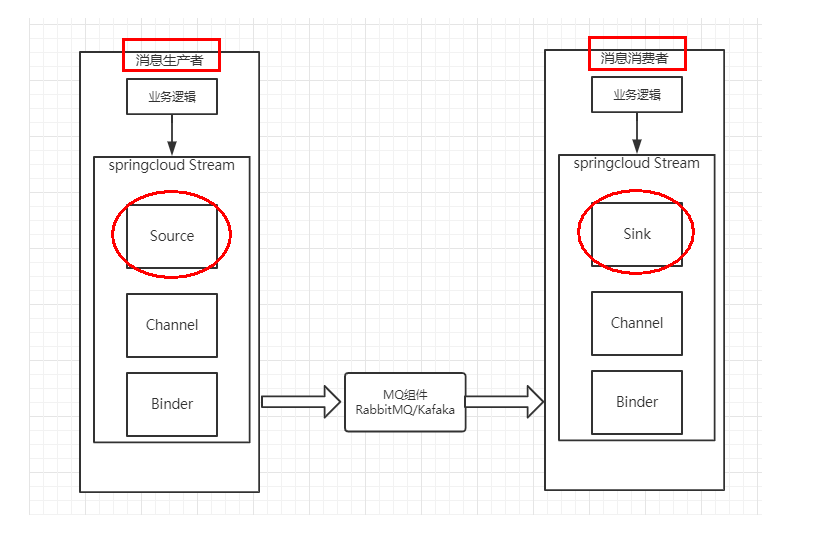
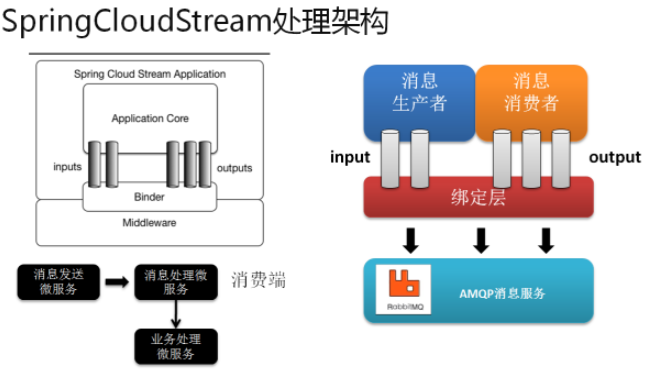
Binder:很方便的连接中间件,屏蔽差异
Channel:通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置
Source和Sink:简单的可理解为参照对象是Spring Cloud Stream自身,从Stream发布消息就是输出,接受消息就是输入。
1.4、编码API和常用注解

2、案例说明
2.1、配置好RabbitMQ环境
2.2、工程中新建三个子模块
cloud-stream-rabbitmq-provider8801, 作为生产者进行发消息模块
cloud-stream-rabbitmq-consumer8802,作为消息接收模块
cloud-stream-rabbitmq-consumer8803 作为消息接收模块
3、消息驱动之生产者
3.1、新建cloud-stream-rabbitmq-provider8801模块
3.2、修改pom文件
1 |
|
3.3、创建主启动类
1 | package com.lxg.springcloud; |
3.4、第一种发送消息的方式(老版)
3.4.1、修改yml文件
1 | server: |
3.4.2、消息接口
1 | package com.lxg.springcloud.service; |
3.4.3、实现类
1 | package com.lxg.springcloud.service.impl; |
3.4.4、controller
1 | package com.lxg.springcloud.controller; |
3.4.5、测试
启动RabbitMQ
启动7001
启动8801
访问http://localhost:8801/sendMessage
3.5、第二种发送消息的方式(streamBridge)
3.5.1、修改yml文件(与第一种一致)
3.5.2、消息接口(与第一种一致)
3.5.3、实现类
1 | package com.lxg.springcloud.service.impl; |
注意send方法中的output是通道名称,与yml文件配置一致
3.5.4、controller(与第一种一致)
3.6、第三种发送方式(Supplier)
使用Supplier接口发送消息:
- 新建一个bean返回type为
Supplier,方法为hello(),会自动创建exchange=hello-out-0 - 默认情况下每1秒钟由Spring框架触发1次。
- 修改默认值:
spring.cloud.stream.poller.fixedDelay=5000 - Reactive风格编程,
Supplier<Flux<String>> hello(),Flux.just(String),只会触发一次。 - Reactive风格编程,配合Thread.sleep和Schedulers.elastic(),可实现每1秒发送1次消息。
- Reactive风格编程,使用
@PollableBean轻松实现每1秒发送1次消息。
3.6.1、修改yml
1 | server: |
3.6.2、消息接口
1 | package com.lxg.springcloud.service; |
3.6.3、实现类
1 | package com.lxg.springcloud.service.impl; |
3.6.4、controller
1 | package com.lxg.springcloud.controller; |
每个1秒自动触发发送一次消息,比如我们加上spring.cloud.stream.poller.fixedDelay=5000,那么Supplier消息就会每隔5秒发送一次。
4、消息驱动之消费者
4.1、新建cloud-stream-rabbitmq-consumer8802模块
4.2、修改pom文件
1 |
|
4.3、创建主启动类
1 | package com.lxg.springcloud; |
4.4、第一种接收消息的方式(老版)
4.4.1、修改yml
1 | server: |
4.4.2、controller
1 | package com.lxg.springcloud.controller; |
4.5、第二种接收消息的方式(consumer)
使用这个默认会自动生成一个方法名-in-0的exchange来接收,所以应该在发送端指定发送的exchange名字

4.5.1、修改yml
1 | server: |
4.5.2、controller
1 | package com.lxg.springcloud.controller; |
5、自定义消息通道(老版,新版不需要)
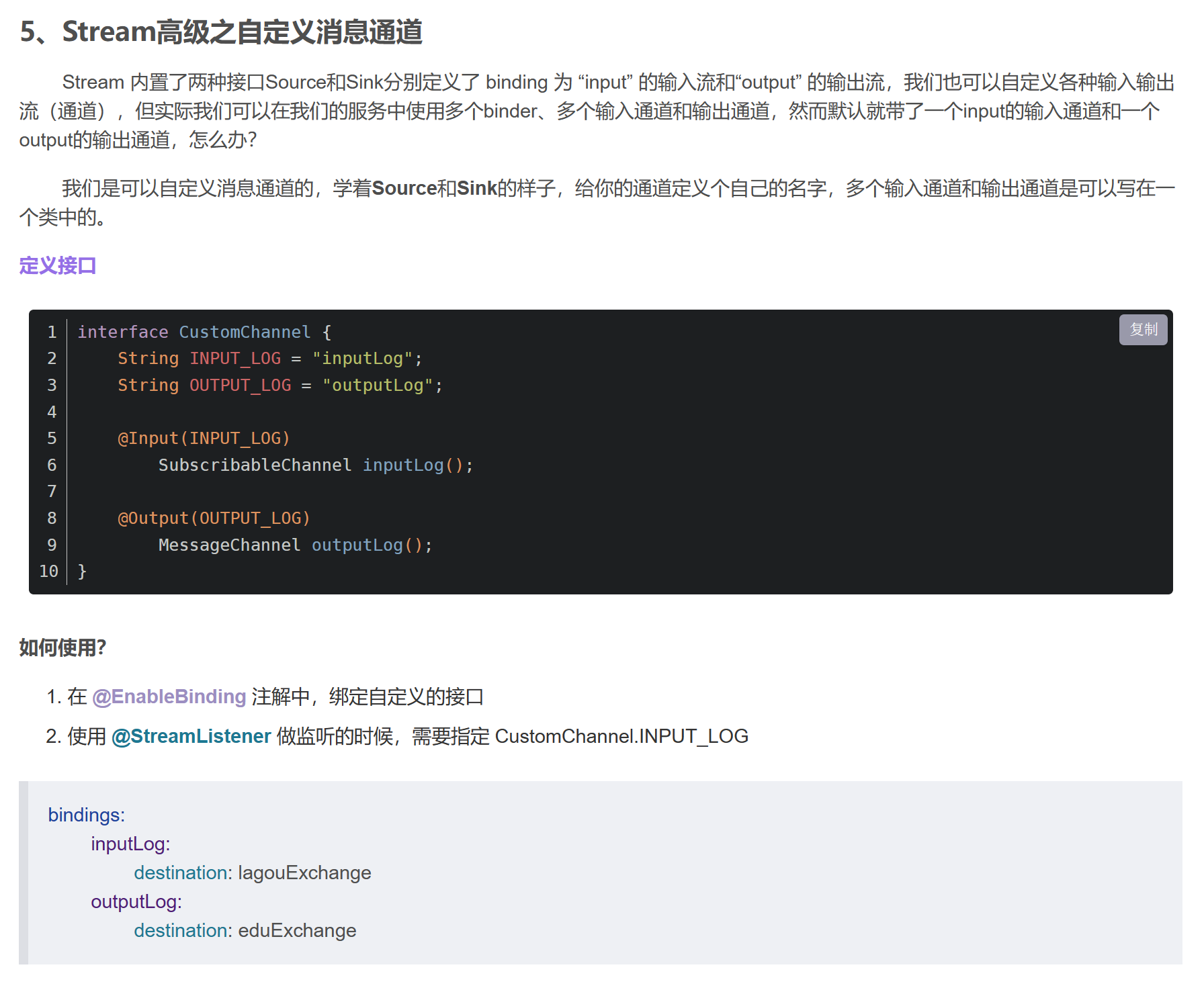
6、分组消费与持久化
6.1、依照8802,新建一个8803
6.1.1、pom
1 |
|
6.1.2、yml
1 | server: |
6.1.3、主启动类
1 | package com.lxg.springcloud; |
6.1.4、controller
1 | package com.lxg.springcloud.controller; |
6.2、启动
启动RabbitMQ、7001、8801、8802、8803
运行后的问题:
- 8802和8803都能接收消息来处理
- 消息持久化
其实就是这个队列是topic模式,routing-key是#,即所有队列都能接收消费,而默认不同消费者使用的是不同队列
6.3、消费
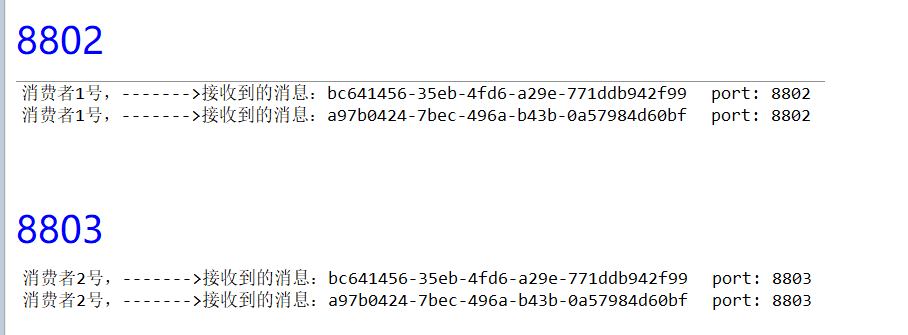
目前是8802/8803同时都收到了,存在重复消费问题
http://localhost:8801/sendMessage
6.3.1、如何解决
分组和持久化属性group
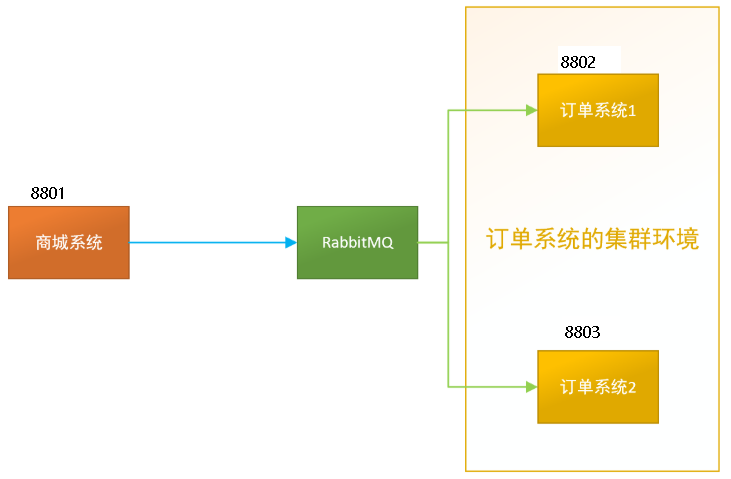
6.3.2、生产实际案例
比如在如下场景中,订单系统我们做集群部署,都会从RabbitMQ中获取订单信息,
那如果一个订单同时被两个服务获取到,那么就会造成数据错误,我们得避免这种情况。
这时我们就可以使用Stream中的消息分组来解决
注意在Stream中处于同一个group中的多个消费者是竞争关系,就能够保证消息只会被其中一个应用消费一次。
不同组是可以全面消费的(重复消费),
同一组内会发生竞争关系,只有其中一个可以消费。
使用后,即同一group的消费者使用同一个队列,竞争消费消息
6.4、分组
6.4.1、原理
微服务应用放置于同一个group中,就能够保证消息只会被其中一个应用消费一次。
不同的组是可以消费的,同一个组内会发生竞争关系,只有其中一个可以消费。
6.4.2、8802/8803都变成不同组,group两个相同
分布式微服务应用为了实现高可用和负载均衡,实际上都会部署多个实例,本例阳哥启动了两个消费微服务(8802/8803)
多数情况,生产者发送消息给某个具体微服务时只希望被消费一次,按照上面我们启动两个应用的例子,虽然它们同属一个应用,但是这个消息出现了被重复消费两次的情况。为了解决这个问题,在Spring Cloud Stream中提供了消费组的概念。
8802和8803修改yml:
1 | bindings: # 服务的整合处理 |
8802/8803实现了轮询分组,每次只有一个消费者
8801模块的发的消息只能被8802或8803其中一个接收到,这样避免了重复消费。
同一个组的多个微服务实例,每次只会有一个拿到
6.5、持久化
通过上述,解决了重复消费问题,再看看持久化
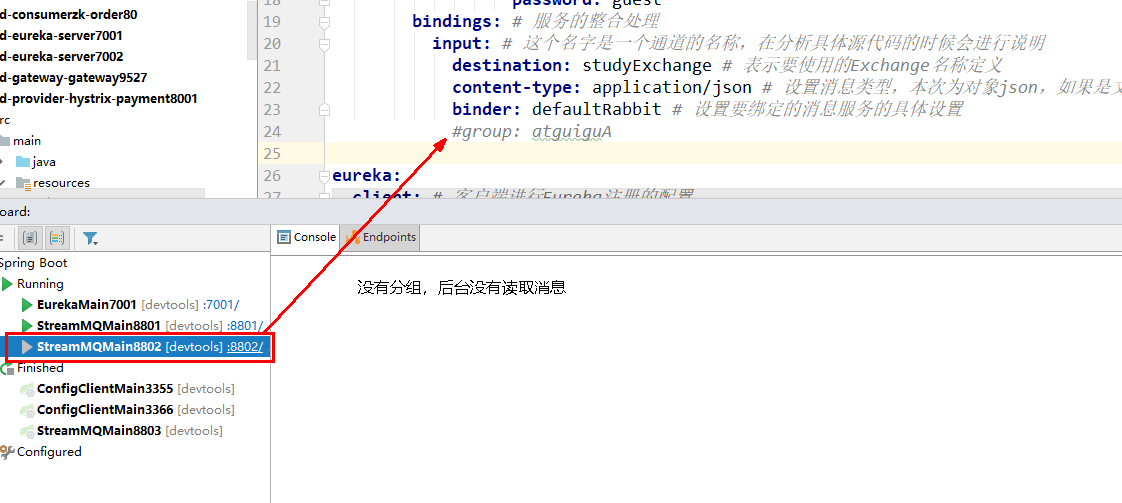
停止8802/8803并去除掉8802的分组group:xiaolinA
8803的分组group: xiaolinA没有去掉
8801先发送4条消息到rabbitmq
先启动8802,无分组属性配置,后台没有打出来消息
再启动8803,有分组属性配置,后台打出来了MQ上的消息
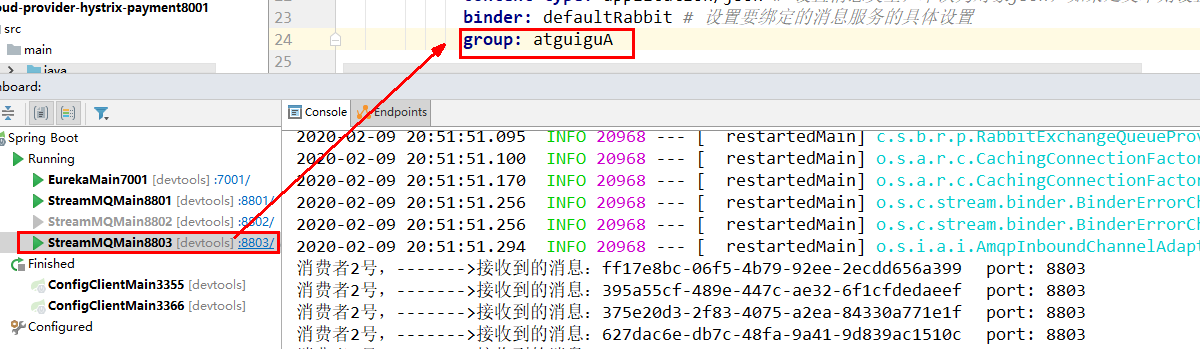
十七、SpringCloud Sleuth分布式请求链路跟踪
1、概述
1.1、为什么会出现这个技术,解决什么问题?
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。

1.2、是什么?
https://github.com/spring-cloud/spring-cloud-sleuth
Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案
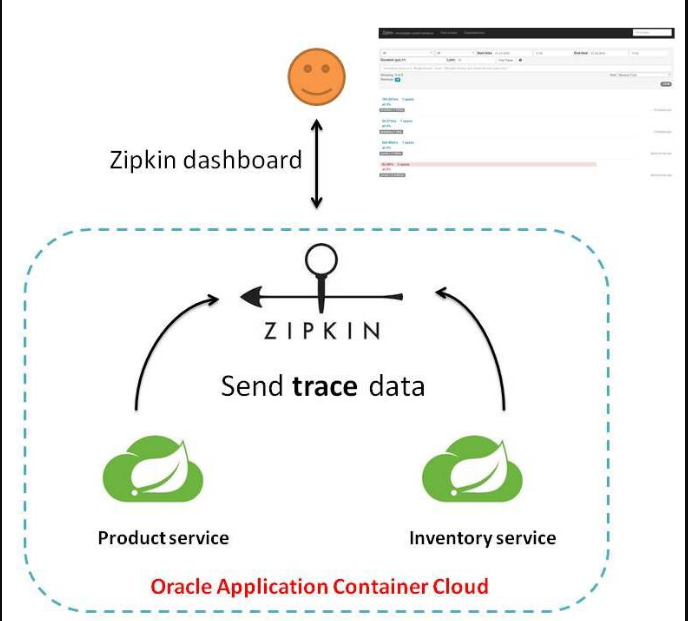
在分布式系统中提供追踪解决方案并且兼容支持了zipkin
1.3、解决
2、搭建链路监控步骤
2.1、zipkin
2.1.1、下载
SpringCloud从F版起已不需要自己构建Zipkin Server了,只需调用jar包即可
项目地址:Central Repository: io/zipkin/zipkin-server (maven.org)
安装包:zipkin-server-2.23.9-exec.jar
2.1.2、运行jar
java -jar zipkin-server-2.23.9-exec.jar
2.1.3、运行控制台
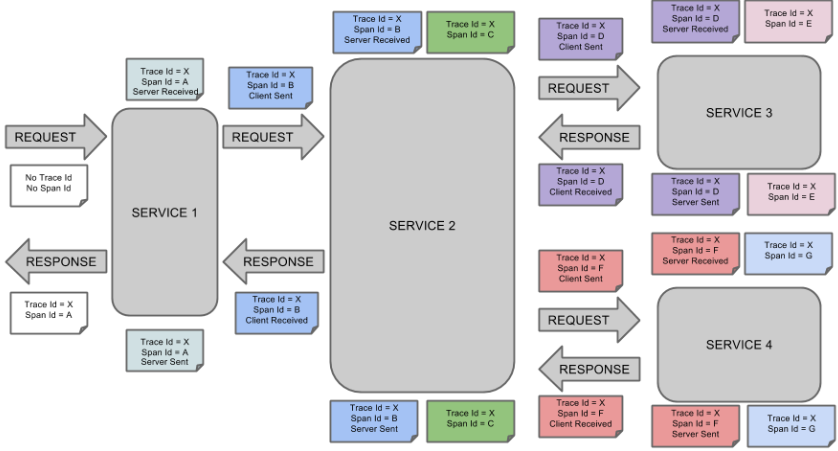
完整的调用链路:
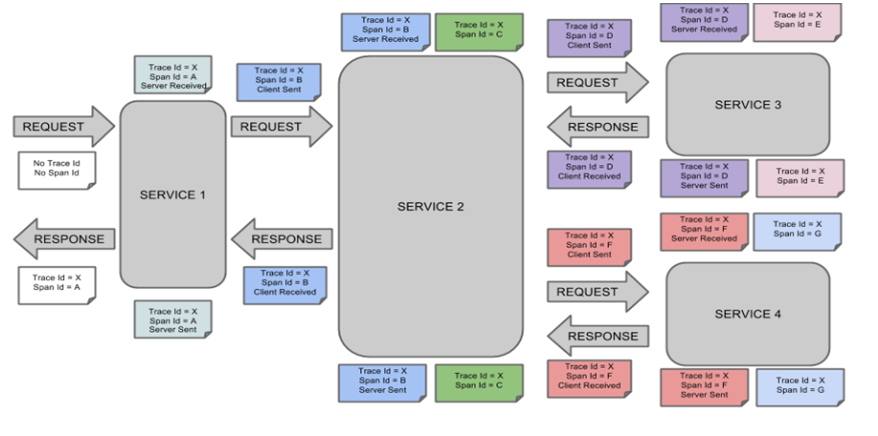
表示一请求链路,一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来
术语:
一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来
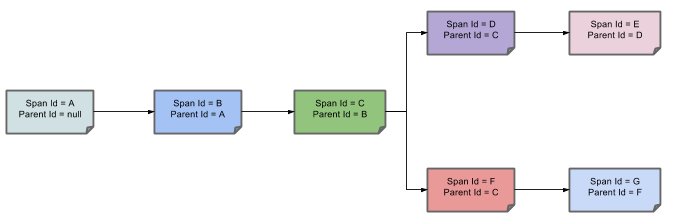

名词解释:
Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
span:表示调用链路来源,通俗的理解span就是一次请求信息
2.2、服务提供者
以cloud-provider-payment8001为例
2.2.1、修改pom文件(添加)
1 | <!--包含了sleuth+zipkin--> |
2.2.2、修改yml
1 | server: |
2.2.3、业务类PaymentController
1 |
|
2.3、服务消费者(调用方)
以cloud-consumer-order80为例
2.3.1、修改pom文件
1 | <!--包含了sleuth+zipkin--> |
2.3.2、修改yml文件
1 | spring: |
2.3.3、业务类OrderController
1 | // ====================> zipkin+sleuth |
2.4、测试
启动7001、8001、80
调用:localhost/consumer/payment/zipkin
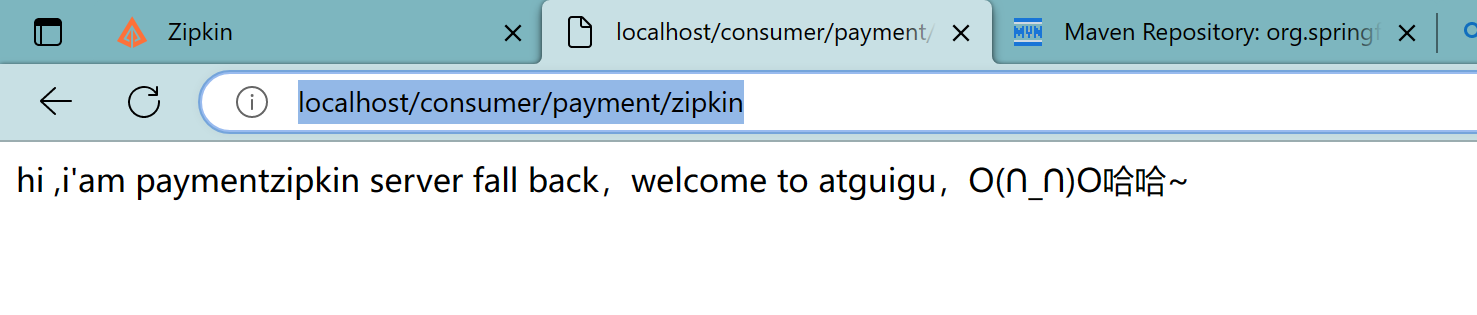
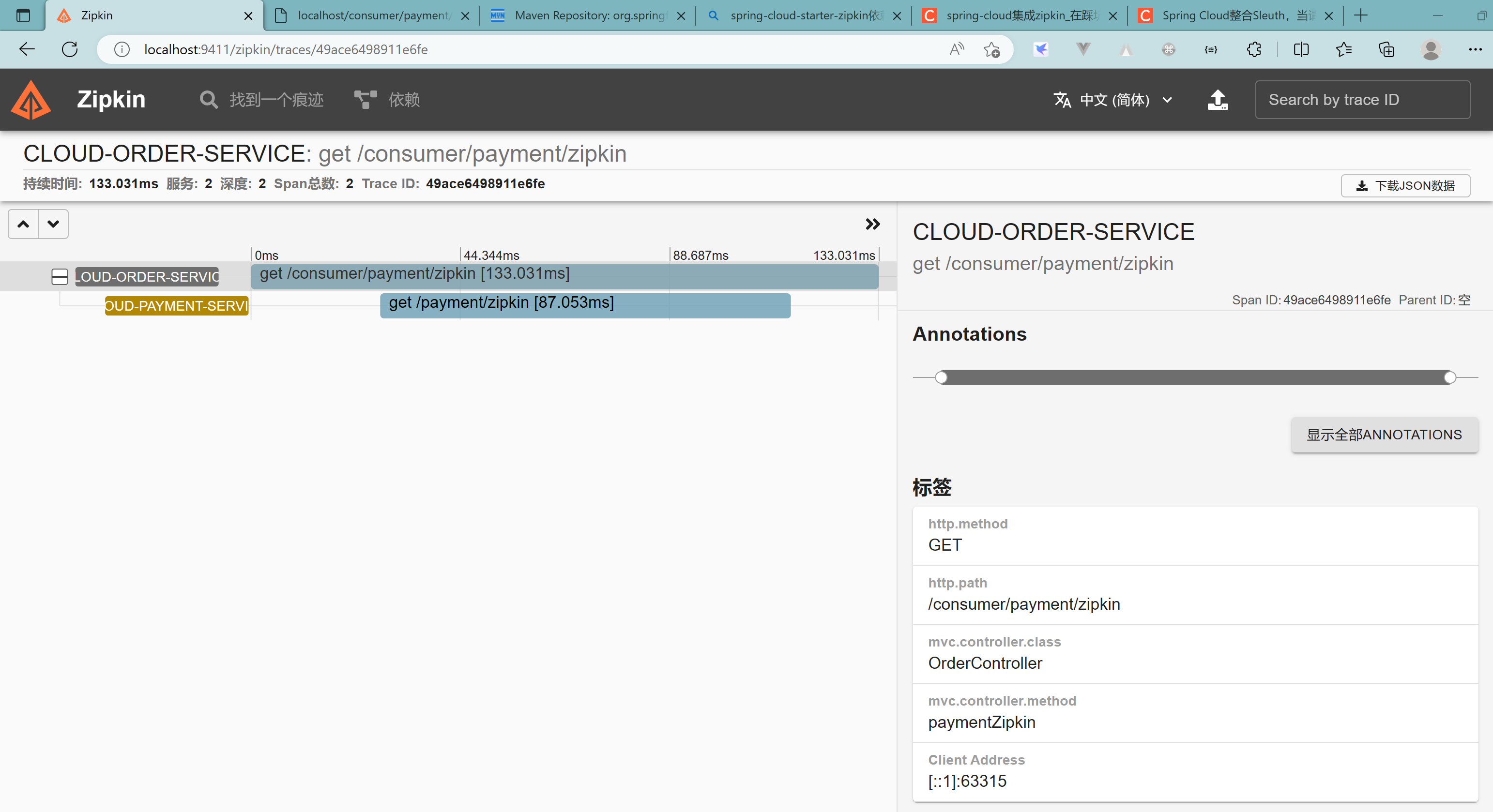
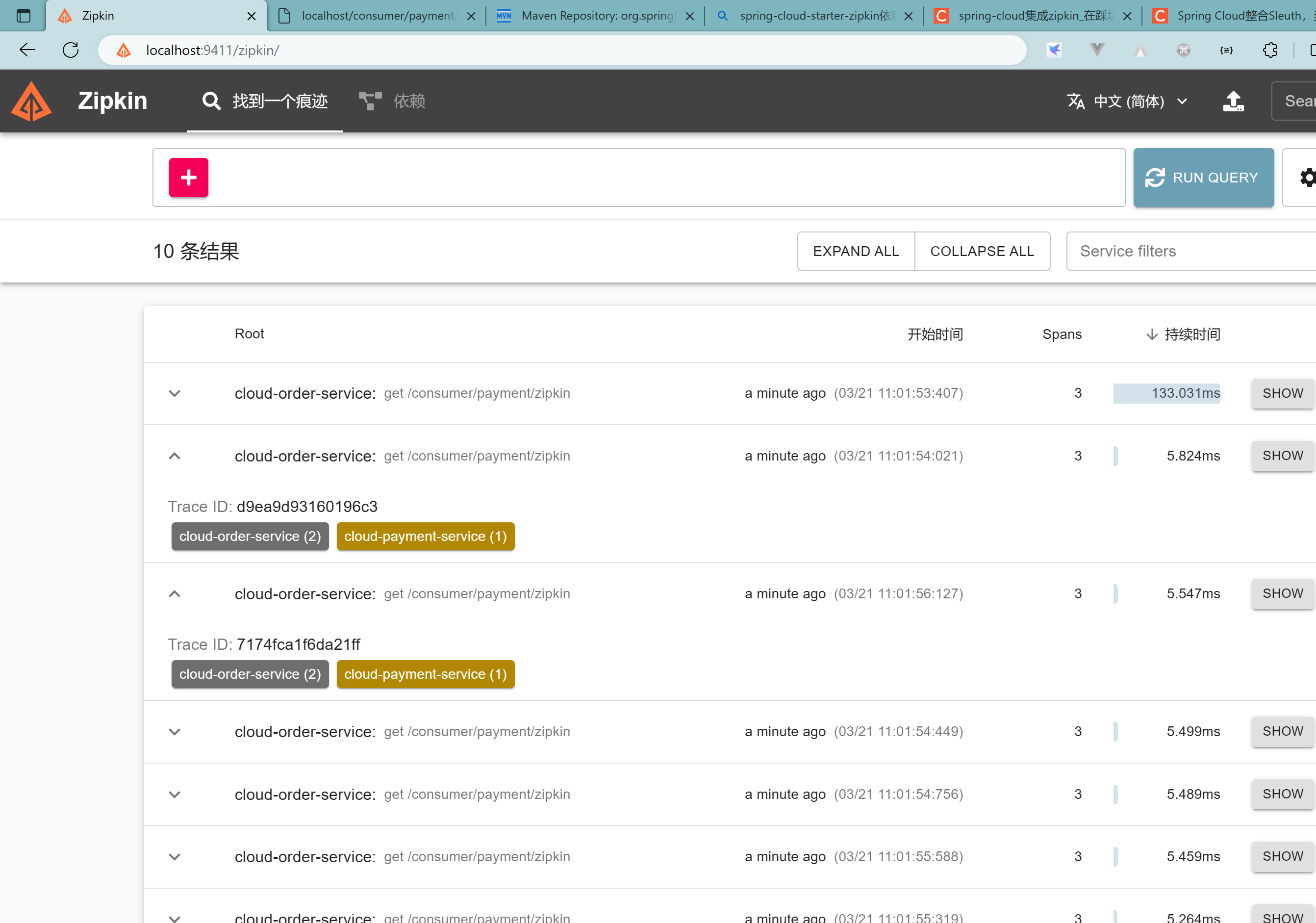
打开浏览器访问:http://localhost:9411/zipkin/
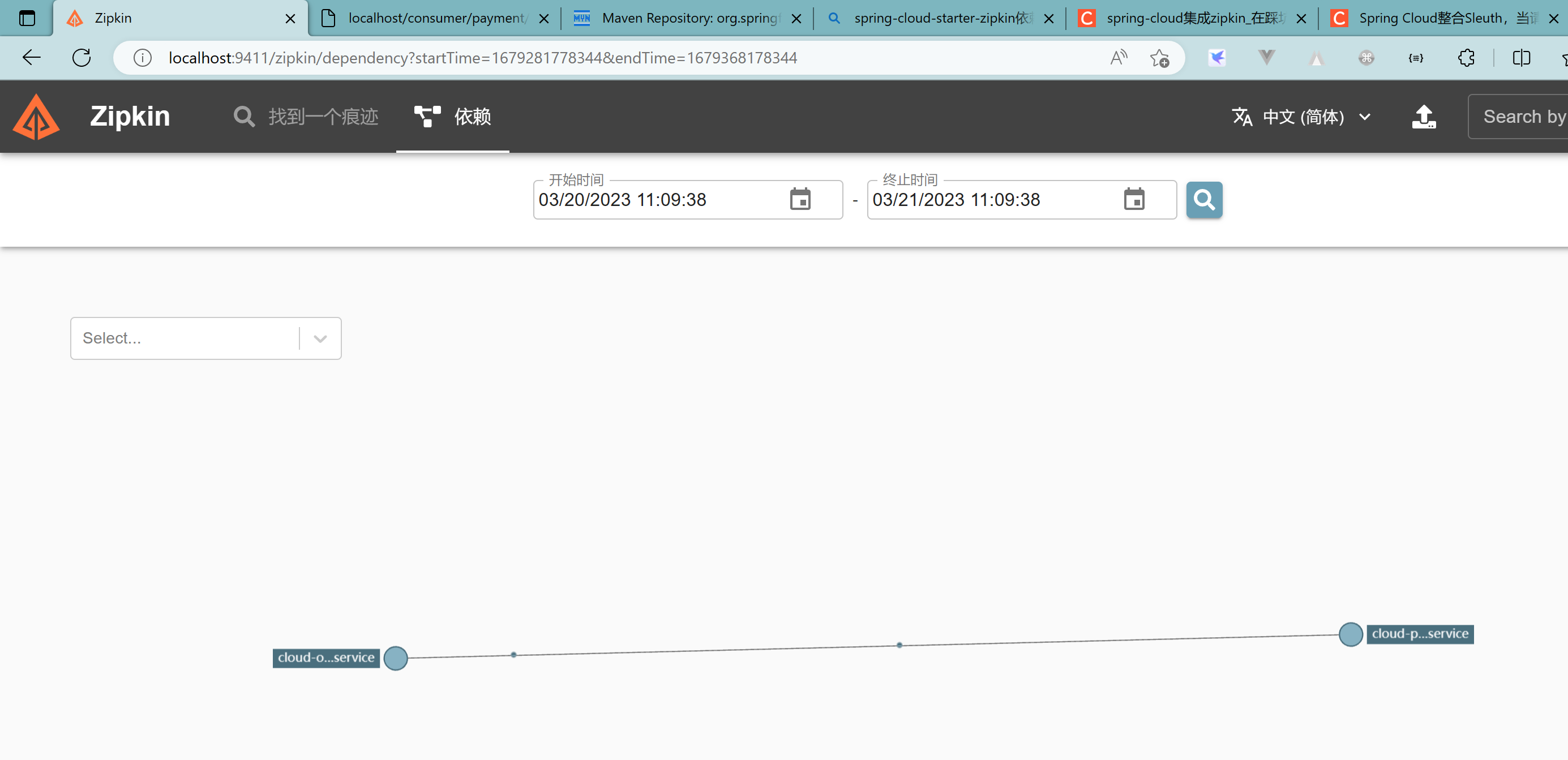
查看依赖关系:
原理:
查看详情: