SpringCloud Alibaba
一、入门简介
1、why会出现SpringCloud alibaba
1.1、Spring Cloud Netflix项目进入维护模式
https://spring.io/blog/2018/12/12/spring-cloud-greenwich-rc1-available-now
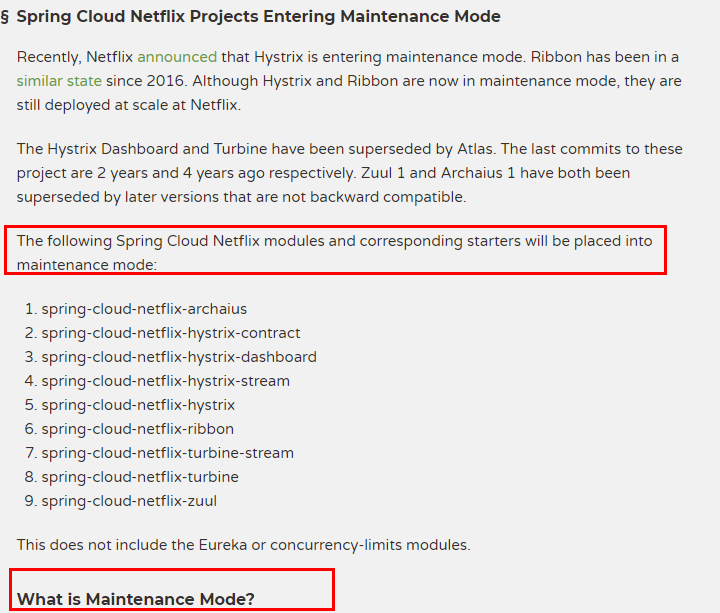
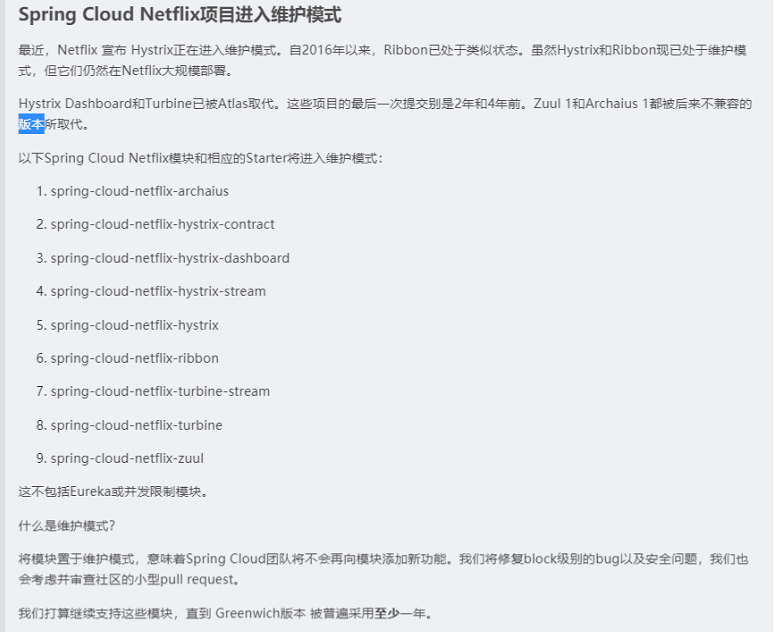
1.2、Spring Cloud Netflix Projects Entering Maintenance Mode
1.2.1、什么是维护模式
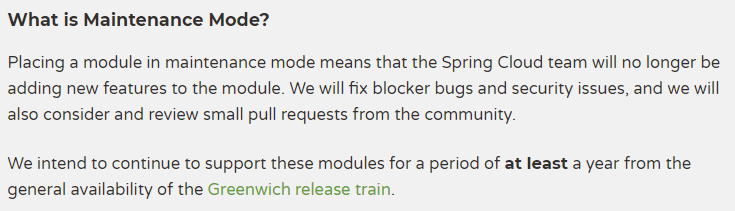
将模块置于维护模式,意味着 Spring Cloud 团队将不会再向模块添加新功能。
我们将修复 block 级别的 bug 以及安全问题,我们也会考虑并审查社区的小型 pull request。
1.2.2、进入维护模式意味着什么呢?
进入维护模式意味着
Spring Cloud Netflix 将不再开发新的组件
我们都知道Spring Cloud 版本迭代算是比较快的,因而出现了很多重大ISSUE都还来不及Fix就又推另一个Release了。进入维护模式意思就是目前一直以后一段时间Spring Cloud Netflix提供的服务和功能就这么多了,不在开发新的组件和功能了。以后将以维护和Merge分支Full Request为主
新组件功能将以其他替代平代替的方式实现

2、SpringCloud alibaba带来了什么
2.1、是什么
官网:
Spring Cloud Alibaba 参考文档 (spring-cloud-alibaba-group.github.io)
spring-cloud-alibaba/README-zh.md at 2021.x · alibaba/spring-cloud-alibaba · GitHub
诞生:
2018.10.31,Spring Cloud Alibaba 正式入驻了 Spring Cloud 官方孵化器,并在 Maven 中央库发布了第一个版本。

2.2、能干嘛
- 服务限流降级:默认支持 Servlet、Feign、RestTemplate、Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。
- 服务注册与发现:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
- 消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
2.3、去哪下载
spring-cloud-alibaba/README-zh.md at 2021.x · alibaba/spring-cloud-alibaba · GitHub
2.4、怎么玩

3、SpringCloud alibaba学习资料获取
3.1、官网

Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
SpringCloud Alibaba进入了SpringCloud官方孵化器,而且毕业了
https://spring.io/projects/spring-cloud-alibaba#overview
3.2、英文版
https://github.com/alibaba/spring-cloud-alibaba
https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
3.3、中文版
spring-cloud-alibaba/README-zh.md at 2021.x · alibaba/spring-cloud-alibaba · GitHub
二、SpringCloud Alibaba Nacos服务注册和配置中心
1、Nacos简介
1.1、为什么叫Nacos
前四个字母分别为Naming和Configuration的前两个字母,最后的s为Service。
1.2、是什么
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Nacos: Dynamic Naming and Configuration Service
Nacos就是注册中心 + 配置中心的组合
等价于:Nacos = Eureka+Config +Bus
1.3、能干嘛
替代Eureka做服务注册中心
替代Config做服务配置中心
1.4、去哪下
https://github.com/alibaba/Nacos
官网文档:
1.5、各种注册中心比较
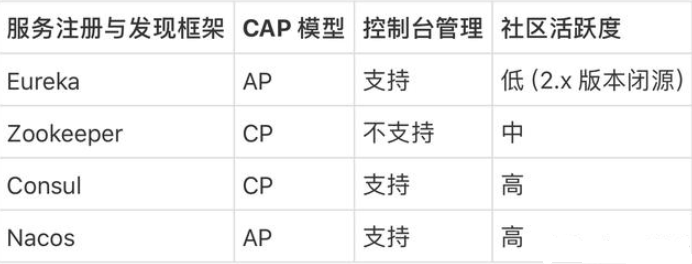
据说 Nacos 在阿里巴巴内部有超过 10 万的实例运行,已经过了类似双十一等各种大型流量的考验
2、安装运行Nacos
本地Java8+Maven环境已经OK
2.1、先从官网下载Nacos:https://github.com/alibaba/nacos/releases
2.2、解压安装包,直接运行bin目录下的startup.cmd
startup.cmd -m standalone
新版的需要修改配置application.properties
使用以下程序生成秘钥:
1 | import javax.crypto.KeyGenerator; |
搜索并添加到配置文件中:
nacos.core.auth.plugin.nacos.token.secret.key=

2.3、登录
默认账号密码都是:nacos
2.4、结果页面:
3、Nacos作为服务注册中心演示
3.1、官网文档
Spring Cloud Alibaba Reference Documentation (spring-cloud-alibaba-group.github.io)
3.2、基于Nacos的服务提供者
3.2.1、新建cloudalibaba-provider-payment9001
3.2.2、改pom
1 |
|
3.2.3、改yml
1 | server: |
3.2.4、主启动类
1 | package com.lxg.springcloud; |
3.2.5、业务类
1 | package com.lxg.springcloud.controller; |
3.2.6、测试
http://localhost:9001/payment/nacos/1
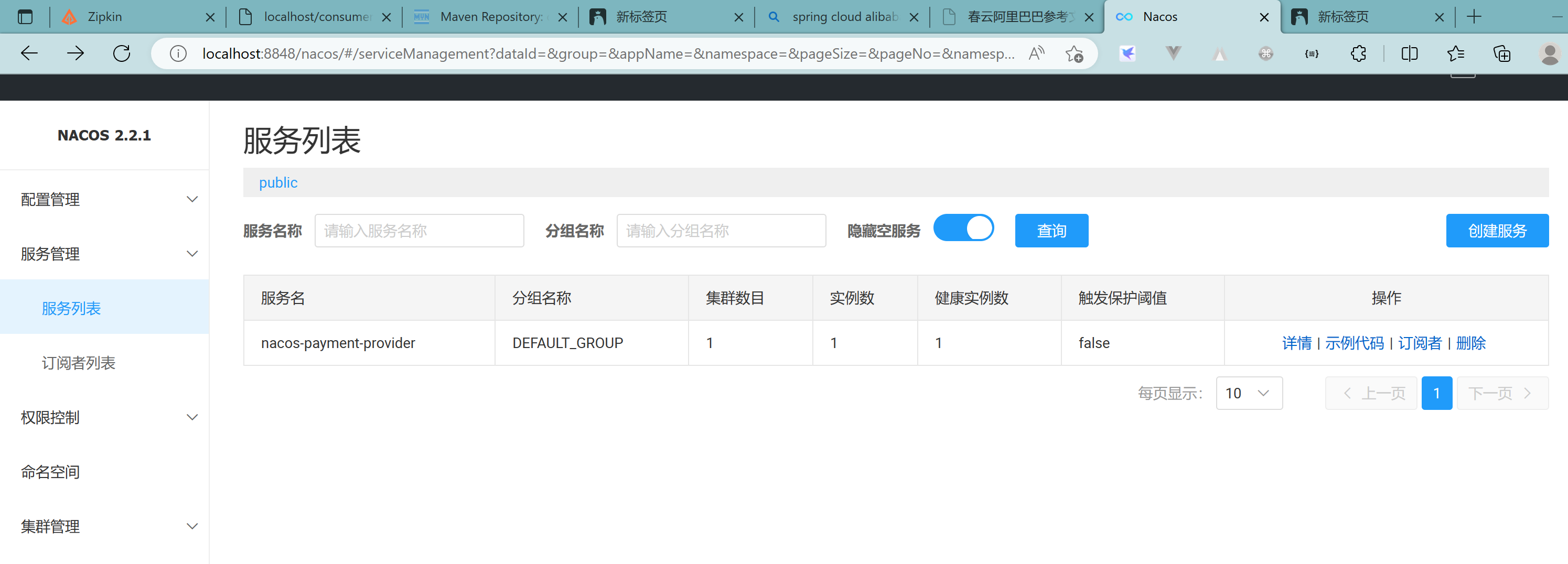
nacos服务注册中心+服务提供者9001都OK了
3.2.7、新建9002
新建cloudalibaba-provider-payment9002
与9001完全一致,只需要更改端口号即可
或者取巧不想新建重复体力劳动,直接拷贝虚拟端口映射:
3.3、基于Nacos的服务消费者
3.3.1、新建cloudalibaba-consumer-nacos-order83模块
3.3.2、pom文件
1 |
|
注意:老版的nacos自带ribbon负载均衡,但是新版的已经没有,需要加入loadbalancer依赖
3.3.3、yml文件
1 | server: |
3.3.4、主启动类
1 | package com.lxg.springcloud; |
3.3.5、业务类
ApplicationContextBean:
1 | package com.lxg.springcloud.config; |
OrderNacosController
1 | package com.lxg.springcloud.controller; |
3.3.6、测试
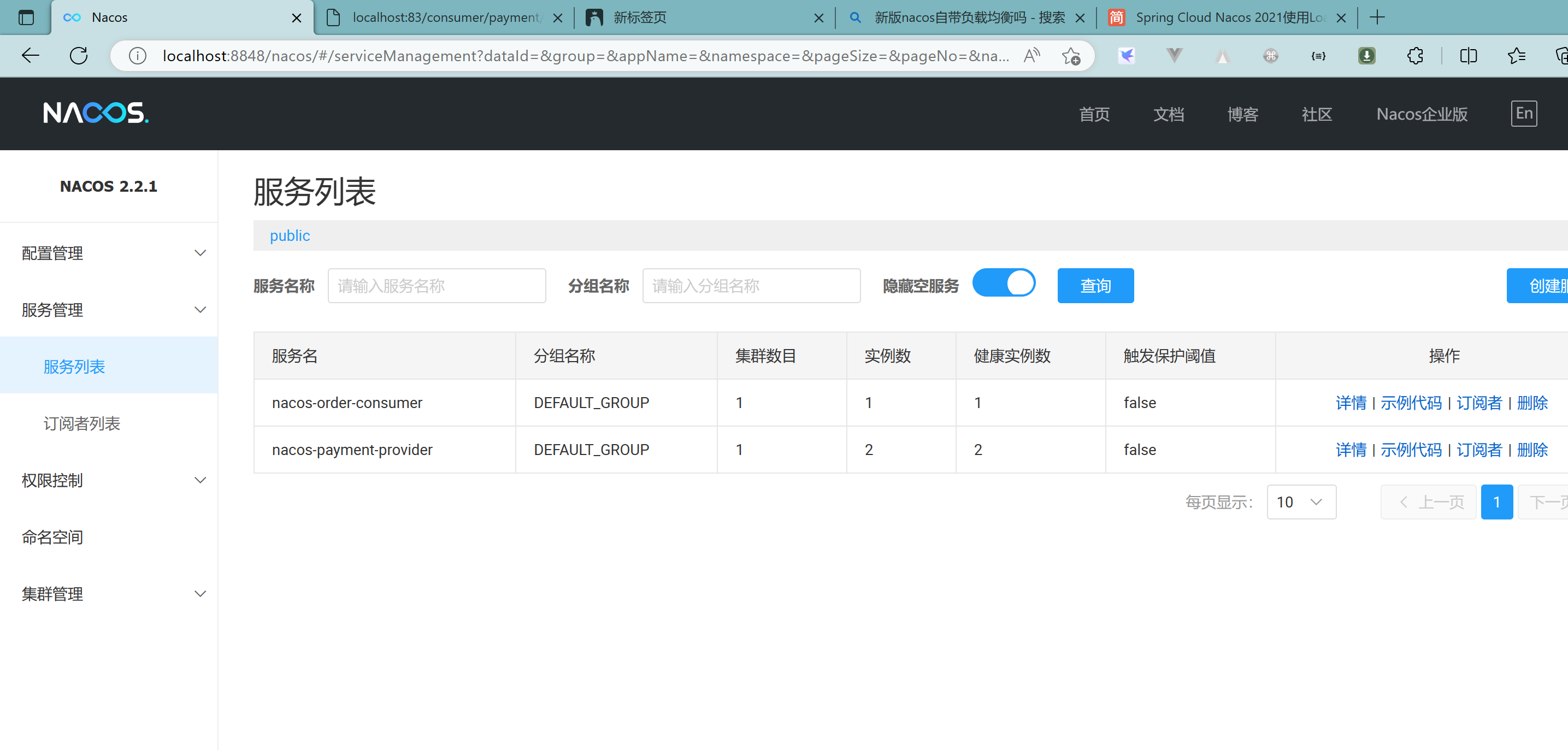
localhost:83/consumer/payment/nacos/13
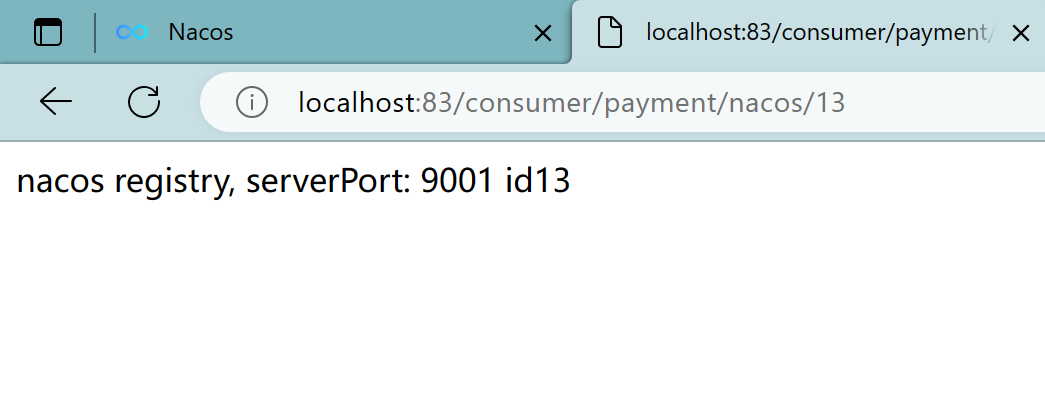
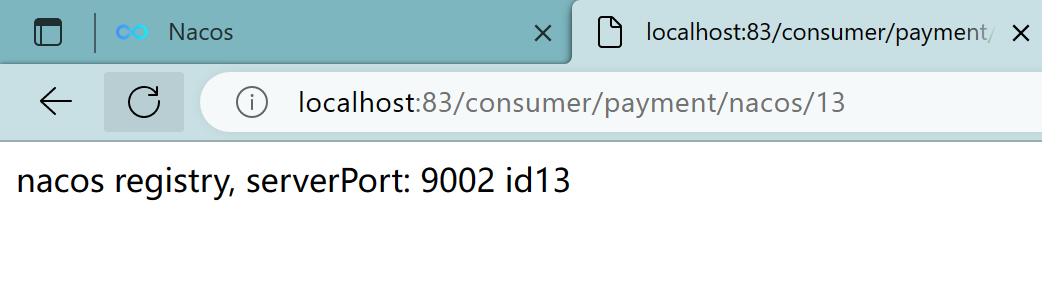
实现了负载均衡
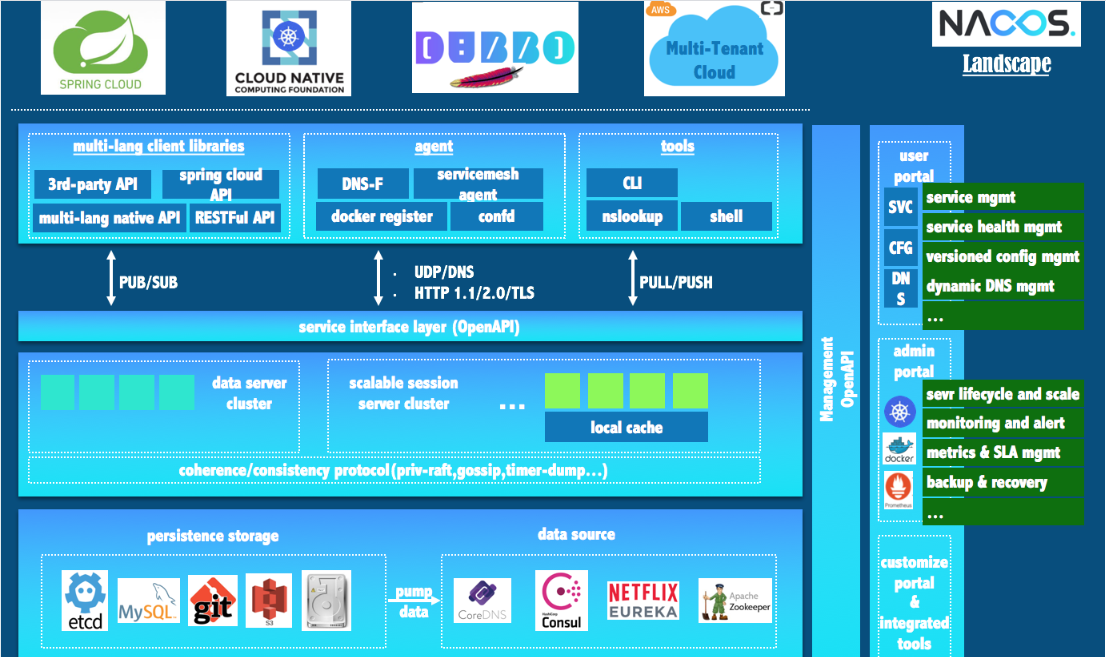
3.4、服务注册中心对比
3.4.1、各种注册中心的对比
Nacos全景图所示
Nacos和CAP
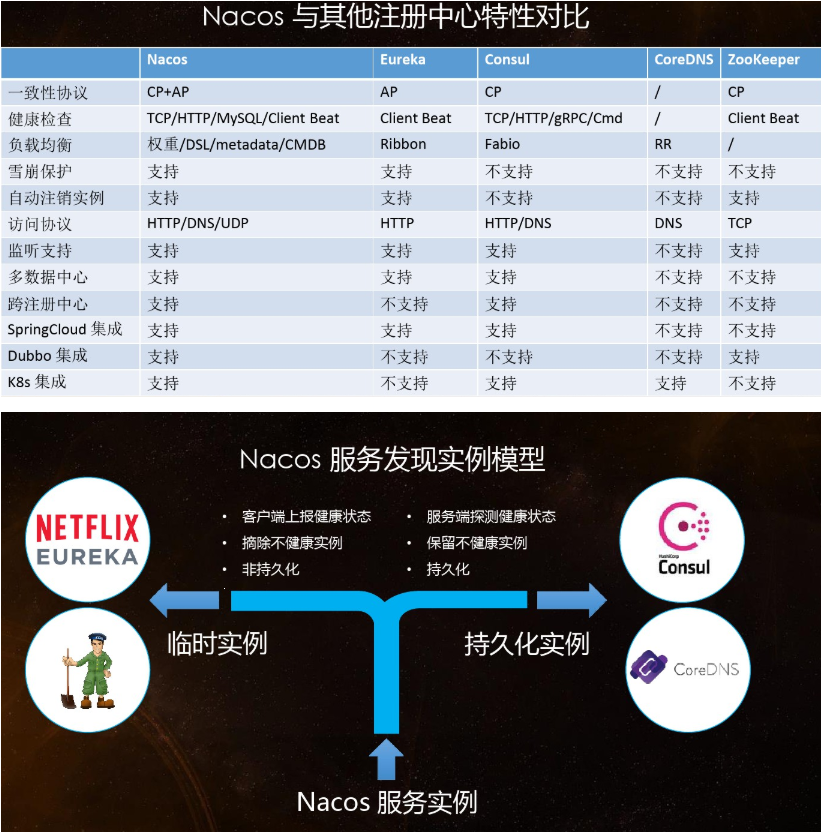
Nacos 支持AP和CP模式的切换:
1 | C是所有节点在同一时间看到的数据是一致的;而A的定义是所有的请求都会收到响应。 |
4、Nacos作为服务配置中心演示
4.1、Nacos作为配置中心-基础配置
4.1.1、新建cloudalibaba-config-nacos-client3377
4.1.2、pom文件
1 |
|
注意,使用了bootstrap.yml就别忘记引入bootstrap依赖
4.1.3、yml文件
why配置两个:
1 | Nacos同springcloud-config一样,在项目初始化时,要保证先从配置中心进行配置拉取, |
bootstrap.yml:
1 | # nacos配置 |
application.yml:
1 | spring: |
4.1.4、主启动类
1 | package com.lxg.springcloud; |
4.1.5、业务类
ConfigClientController:
1 | package com.lxg.springcloud.controller; |
@RefreshScope:

4.1.6、在nacos中添加配置信息
Nacos中的匹配规则:
Nacos中的dataid的组成格式及与SpringBoot配置文件中的匹配规则
官网:
https://nacos.io/zh-cn/docs/quick-start-spring-cloud.html
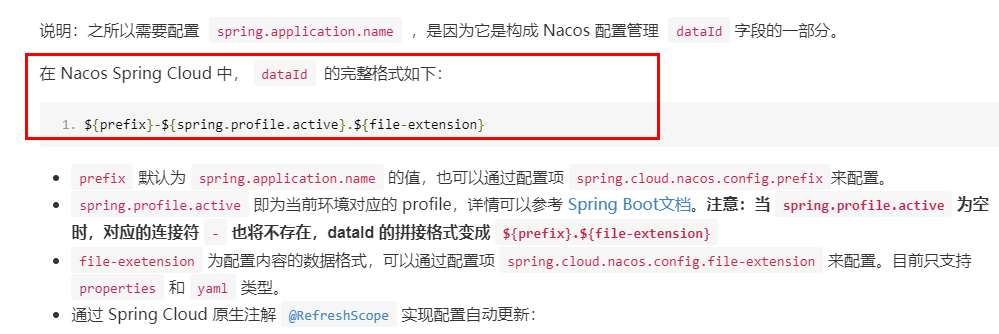
最后公式:
1 | ${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension} |
配置新增:
nacos-config-dev.yaml
Nacos界面配置对应
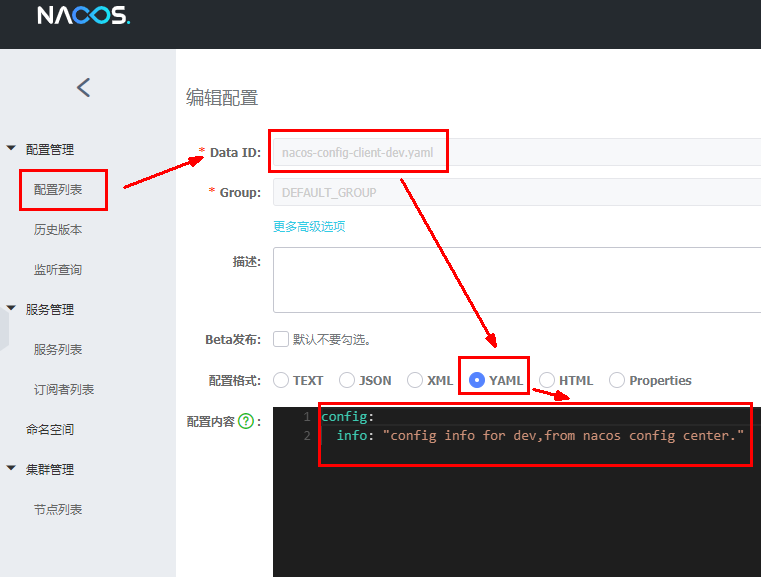
设置DataId
公式:${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}
1 | prefix 默认为 spring.application.name 的值 |
小总结说明:
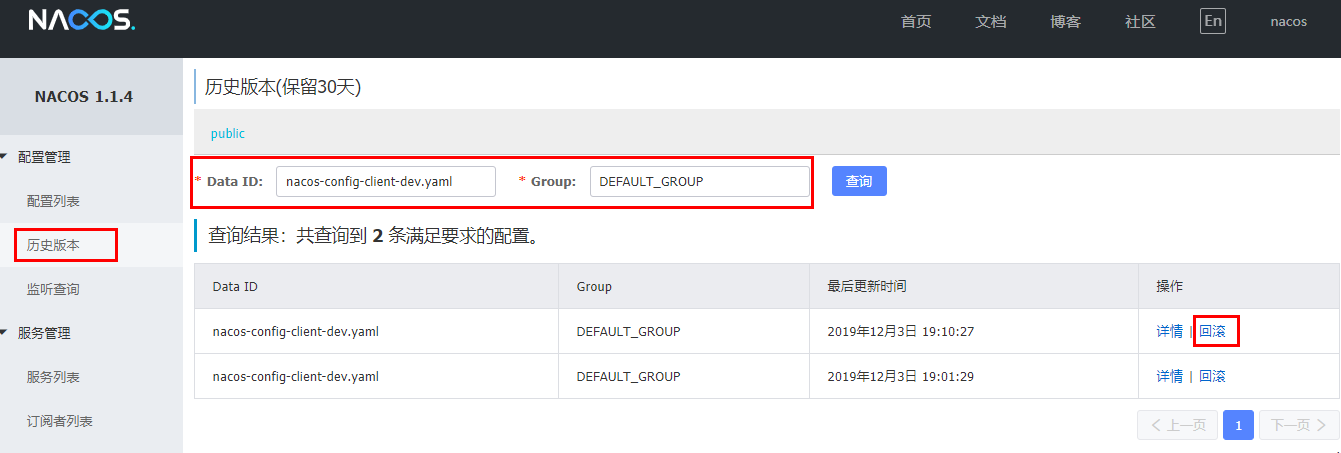
历史配置:
Nacos会记录配置文件的历史版本默认保留30天,此外还有一键回滚功能,回滚操作将会触发配置更新
回滚:
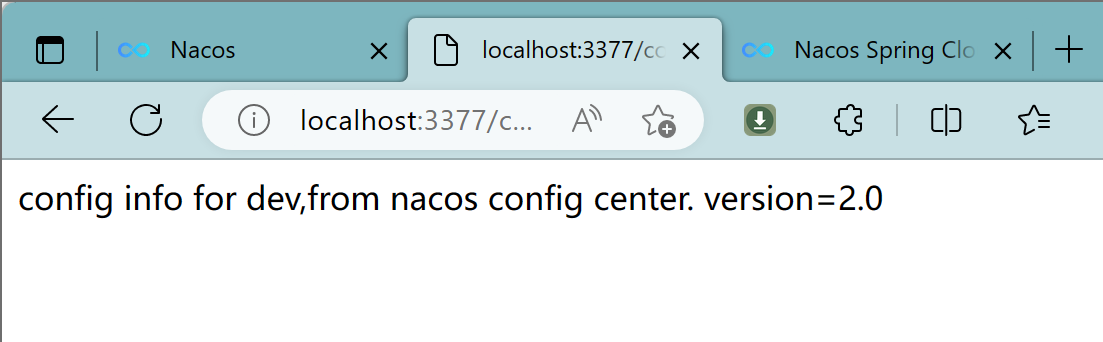
4.1.7、测试
启动前需要在nacos客户端-配置管理-配置管理栏目下有对应的yaml配置文件
运行cloud-config-nacos-client3377的主启动类
调用接口查看配置信息:http://localhost:3377/config/info
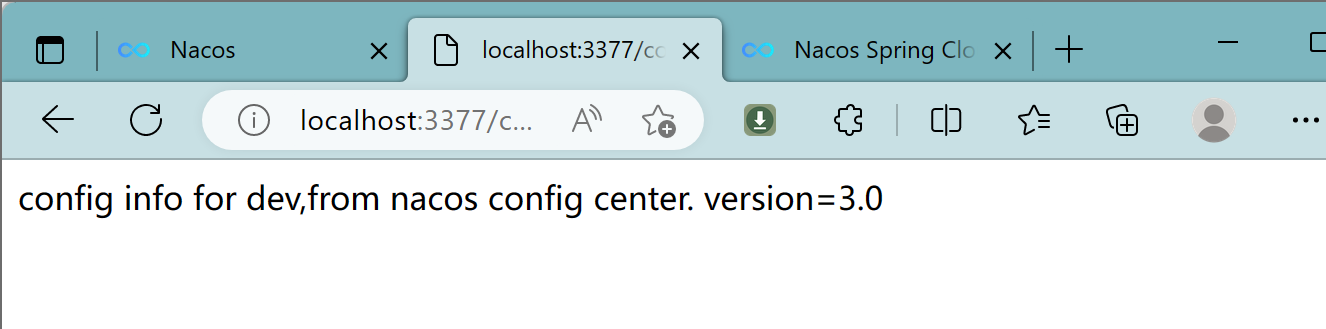
自带动态刷新:
修改下Nacos中的yaml配置文件,再次调用查看配置的接口,就会发现配置已经刷新
4.2、Nacos作为配置中心-分类配置
4.2.1、问题
多环境多项目管理
问题1:
实际开发中,通常一个系统会准备
dev开发环境
test测试环境
prod生产环境。
如何保证指定环境启动时服务能正确读取到Nacos上相应环境的配置文件呢?
问题2:
一个大型分布式微服务系统会有很多微服务子项目,
每个微服务项目又都会有相应的开发环境、测试环境、预发环境、正式环境……
那怎么对这些微服务配置进行管理呢?
4.2.2、Nacos的图形化管理界面
配置管理
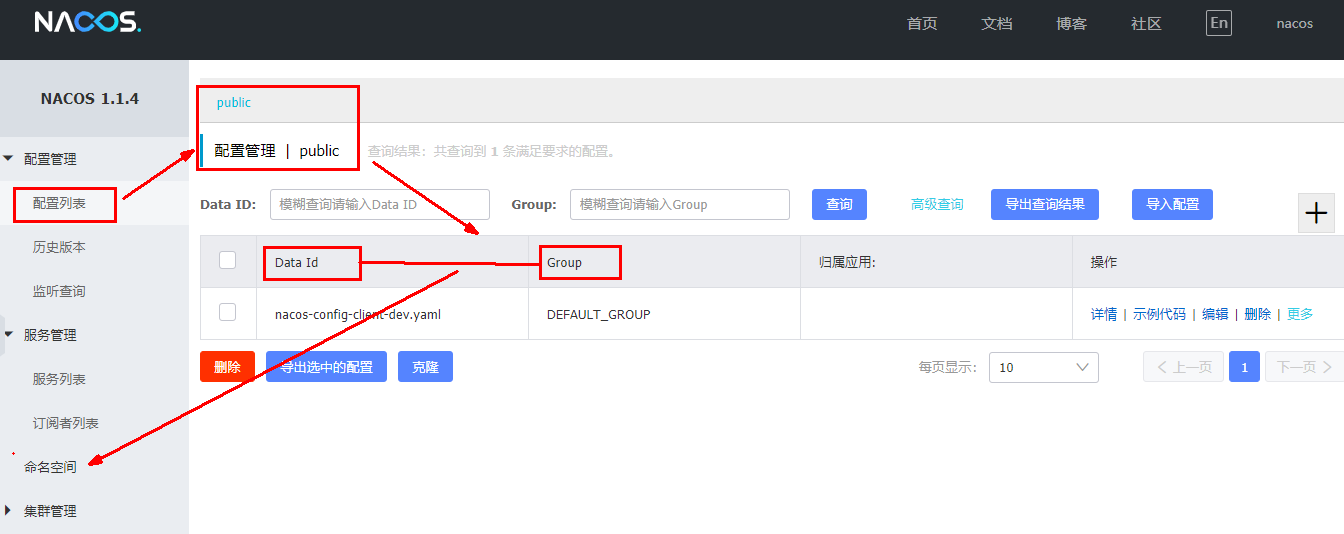
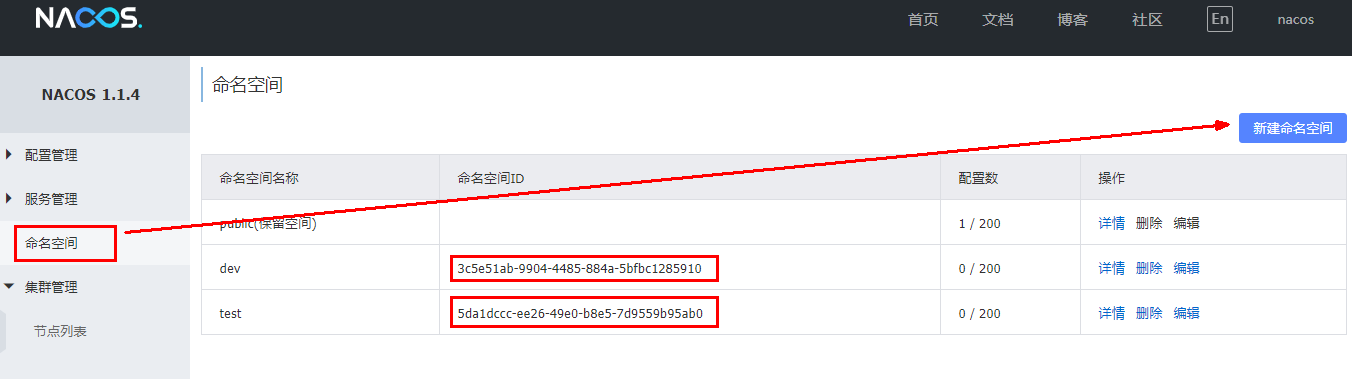
命名空间
Namespace+Group+Data ID三者关系?为什么这么设计?
- 是什么
类似Java里面的package名和类名,最外层的namespace是可以用于区分部署环境的,Group和DataID逻辑上区分两个目标对象。
三者情况
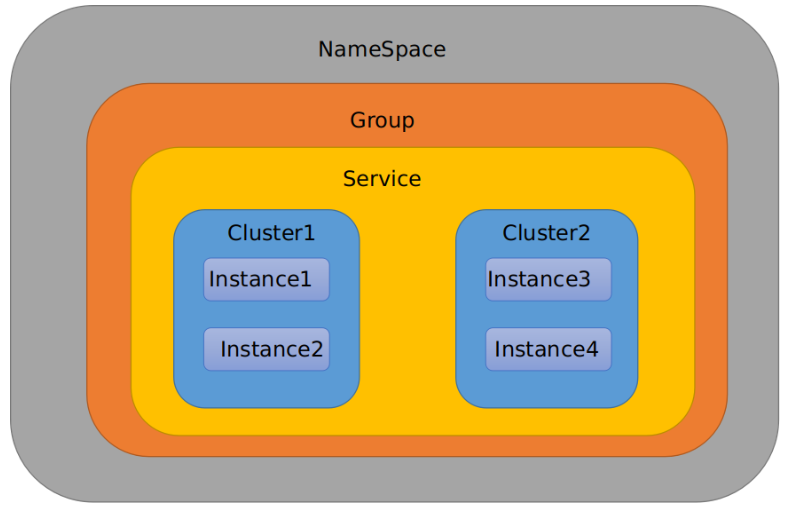
默认情况:
Namespace=public,Group=DEFAULT_GROUP, 默认Cluster是DEFAULTNacos默认的命名空间是public,Namespace主要用来实现隔离。
比方说我们现在有三个环境:开发、测试、生产环境,我们就可以创建三个Namespace,不同的Namespace之间是隔离的。Group默认是DEFAULT_GROUP,Group可以把不同的微服务划分到同一个分组里面去
Service就是微服务;一个Service可以包含多个Cluster(集群),Nacos默认Cluster是DEFAULT,Cluster是对指定微服务的一个虚拟划分。
比方说为了容灾,将Service微服务分别部署在了杭州机房和广州机房,
这时就可以给杭州机房的Service微服务起一个集群名称(HZ),
给广州机房的Service微服务起一个集群名称(GZ),还可以尽量让同一个机房的微服务互相调用,以提升性能。最后是Instance,就是微服务的实例。
4.2.3、案例
三种方案加载配置
DataID方案
指定spring.profile.active和配置文件的DataID来使不同环境下读取不同的配置
默认空间+默认分组+新建dev和test两个DataID:
新建dev配置DataID:
新建test配置DataID:
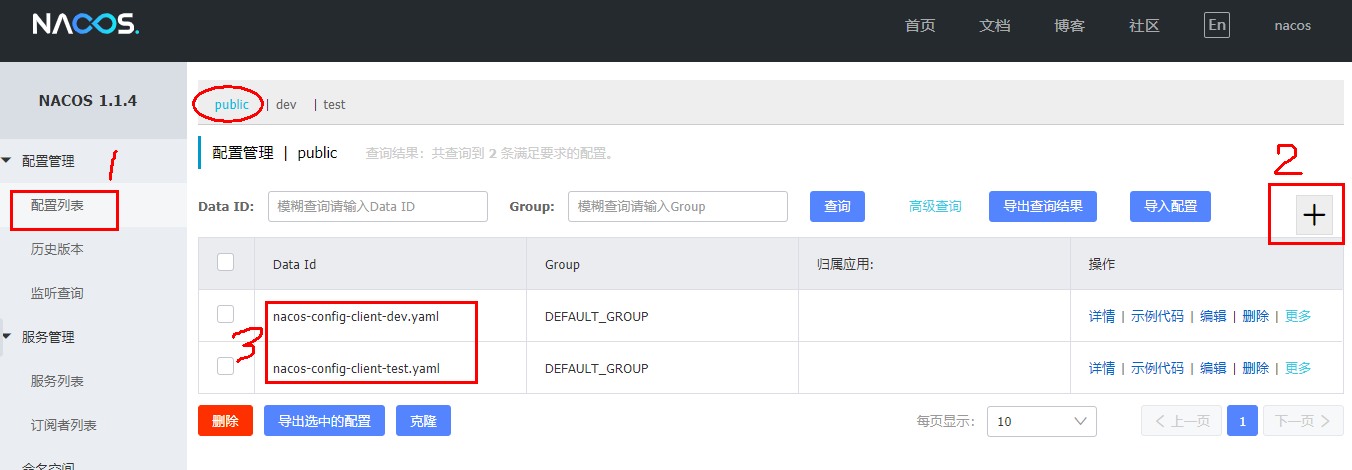
通过spring.profile.active属性就能进行多环境下配置文件的读取:
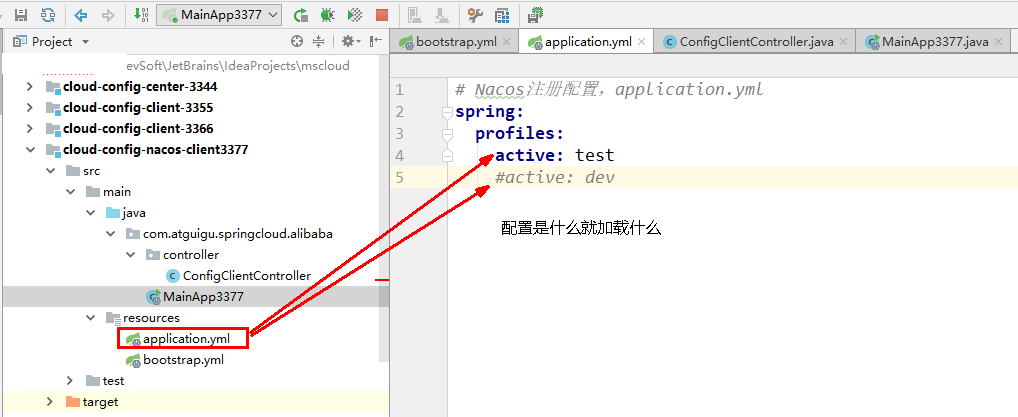
测试:
http://localhost:3377/config/info
配置是什么就加载什么
Group方案
通过Group实现环境区分
新建group
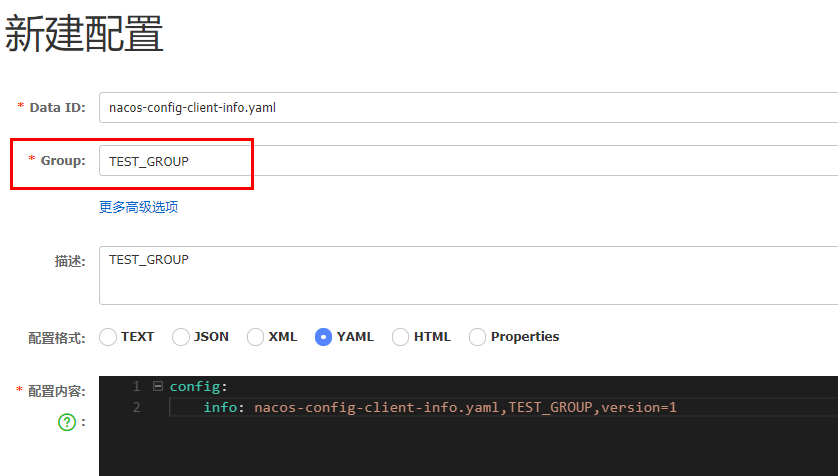
在nacos图形界面控制台上面新建配置文件DataID:
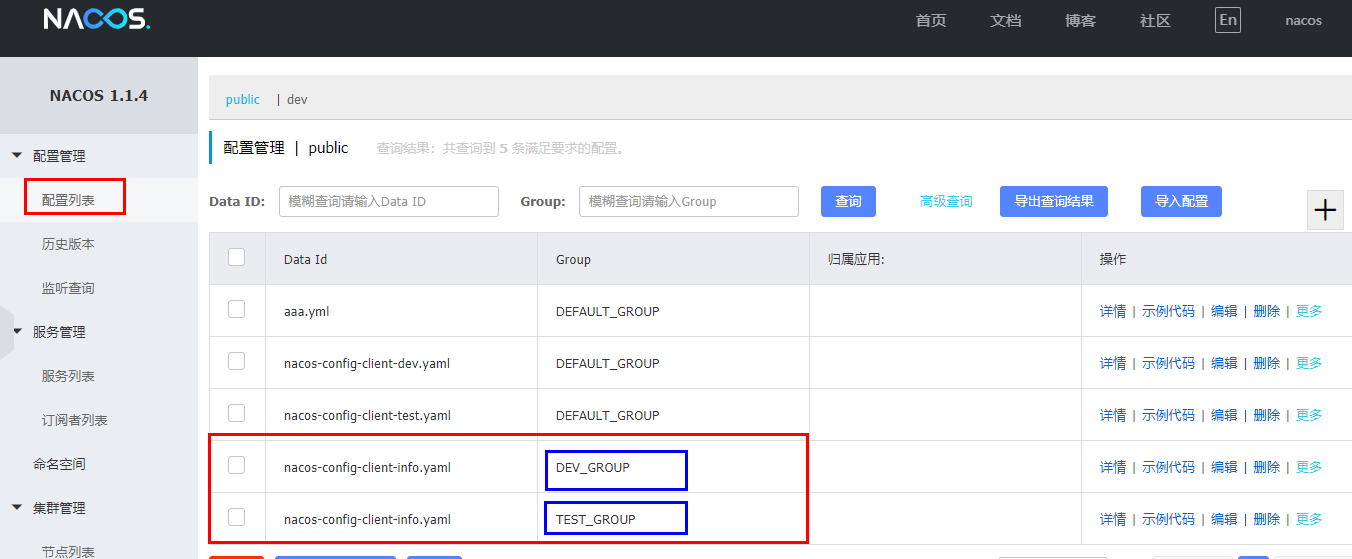
bootstrap+application:
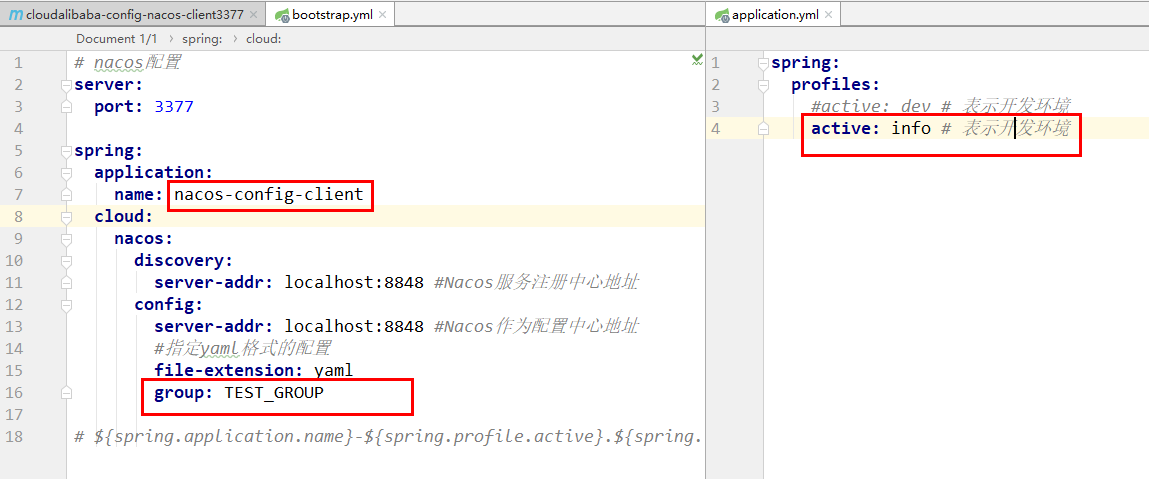
在config下增加一条group的配置即可。
可配置为DEV_GROUP或TEST_GROUPNamespace方案
新建dev/test的Namespace:
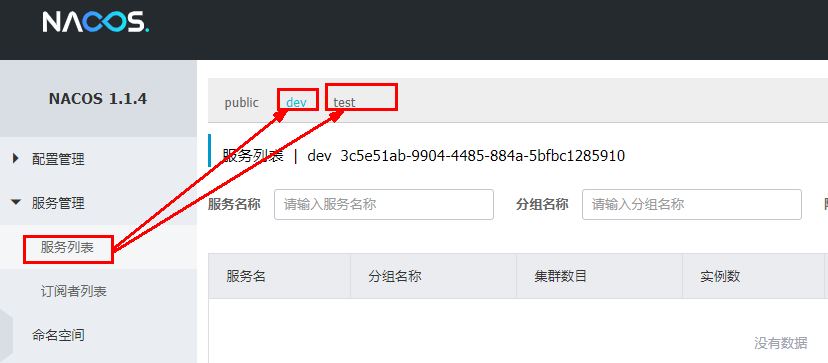
回到服务管理-服务列表查看:
按照域名配置填写:
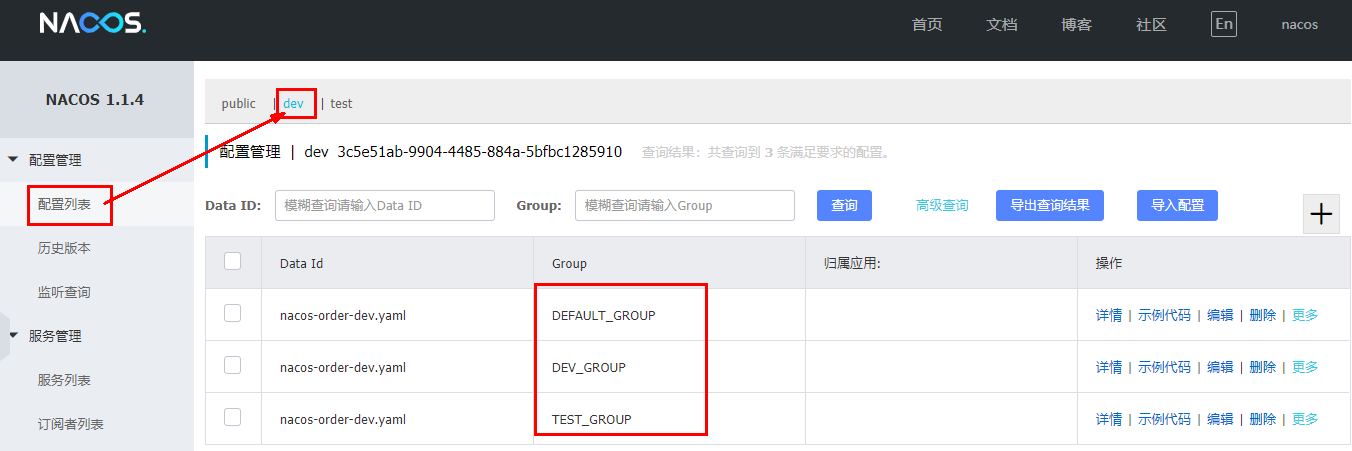
YML:
bootstrap:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# nacos配置
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848 #Nacos作为配置中心地址
file-extension: yaml #指定yaml格式的配置
group: DEV_GROUP
namespace: b4f3cb1a-30bc-4230-92a6-3c81497217f7
# ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
# nacos-config-client-dev.yamlapplication:
1
2
3
4
5
6# Nacos注册配置,application.yml
spring:
profiles:
#active: test
active: dev
#active: info
5、Nacos集群和持久化配置(重要)
5.1、官网说明
https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html
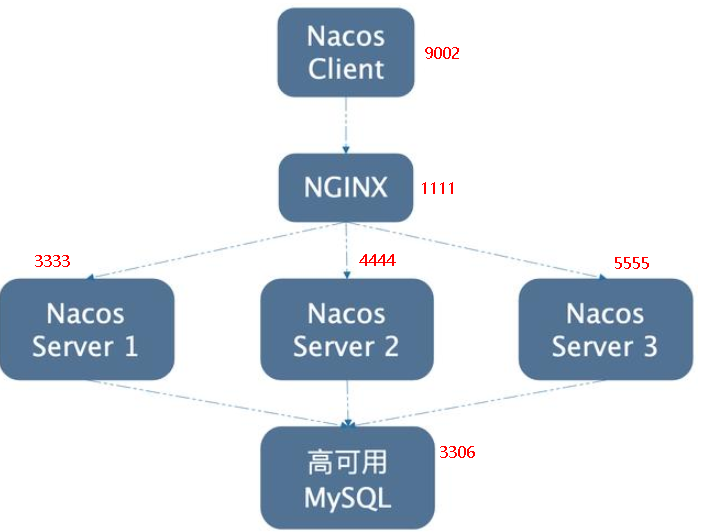
5.1.1、官网架构图
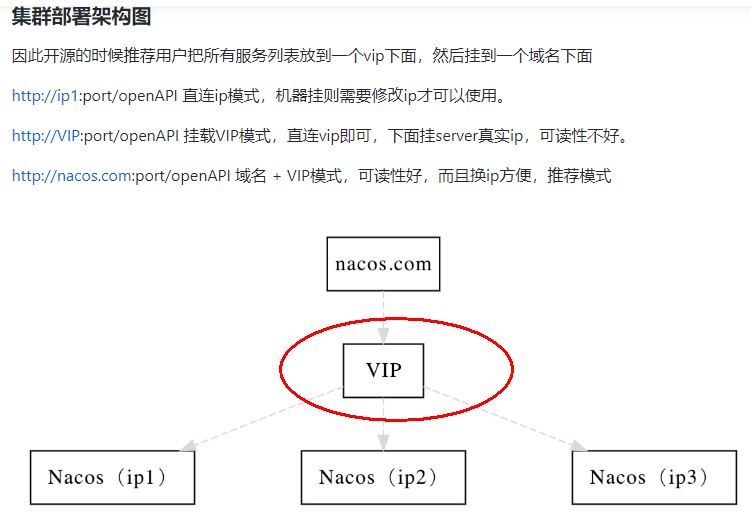
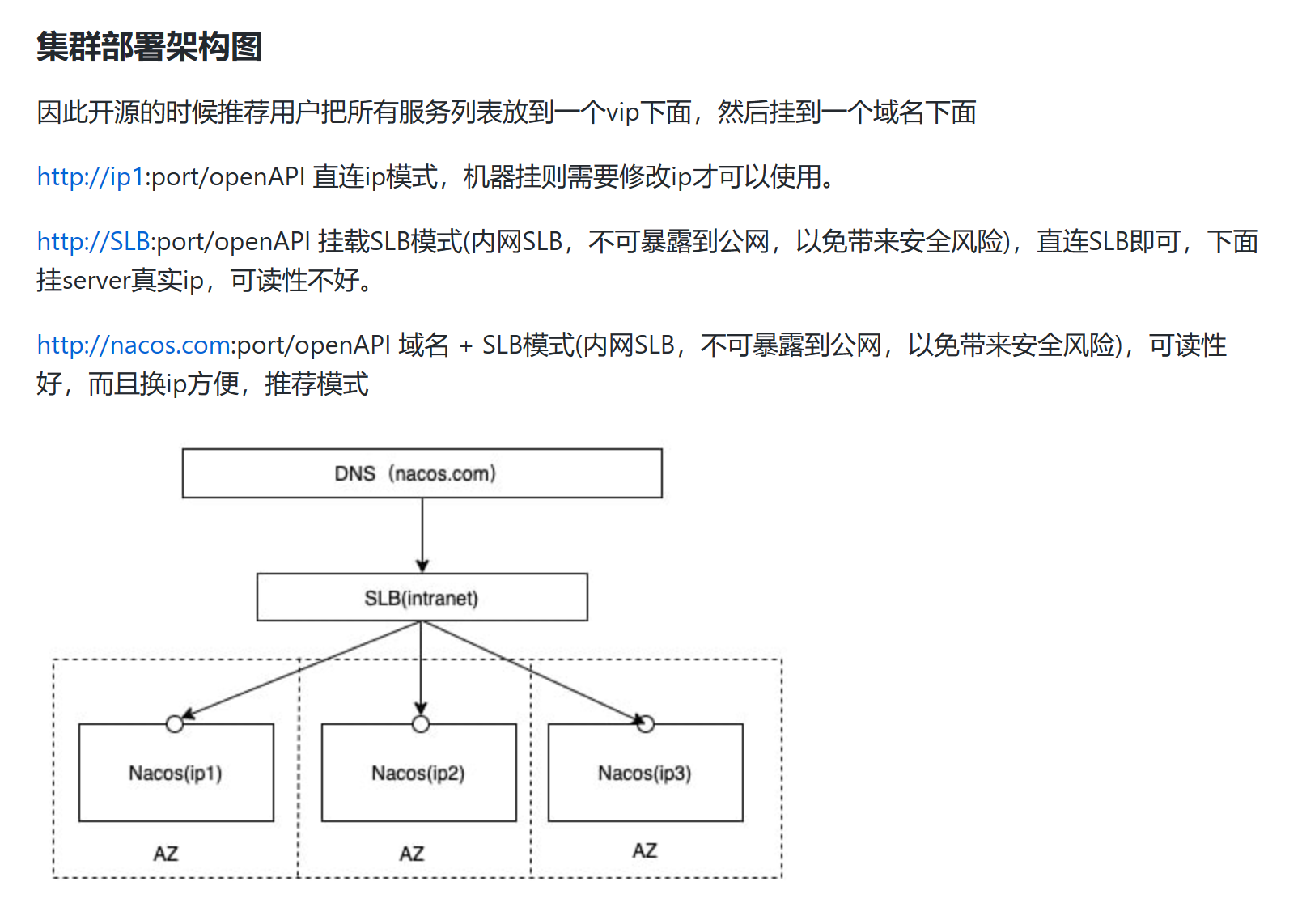
5.1.2、上图官网翻译,真实情况
即VIP就是虚拟ip配置nginx进行访问
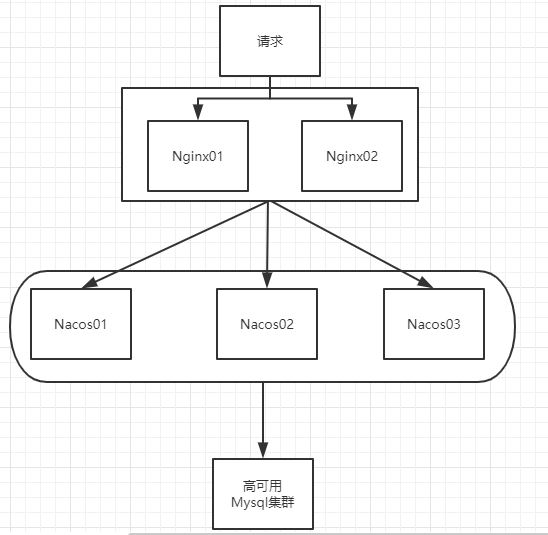
5.1.3、说明
默认Nacos使用嵌入式数据库实现数据的存储。(如Nacos关掉后再打开,里面的配置依然存在)但是因为这样,如果启动多个默认配置下的Nacos节点,数据存储是存在一致性问题的。
为了解决这个问题,Nacos采用了集中式存储的方式来支持集群化部署,目前只支持MySQL的存储。
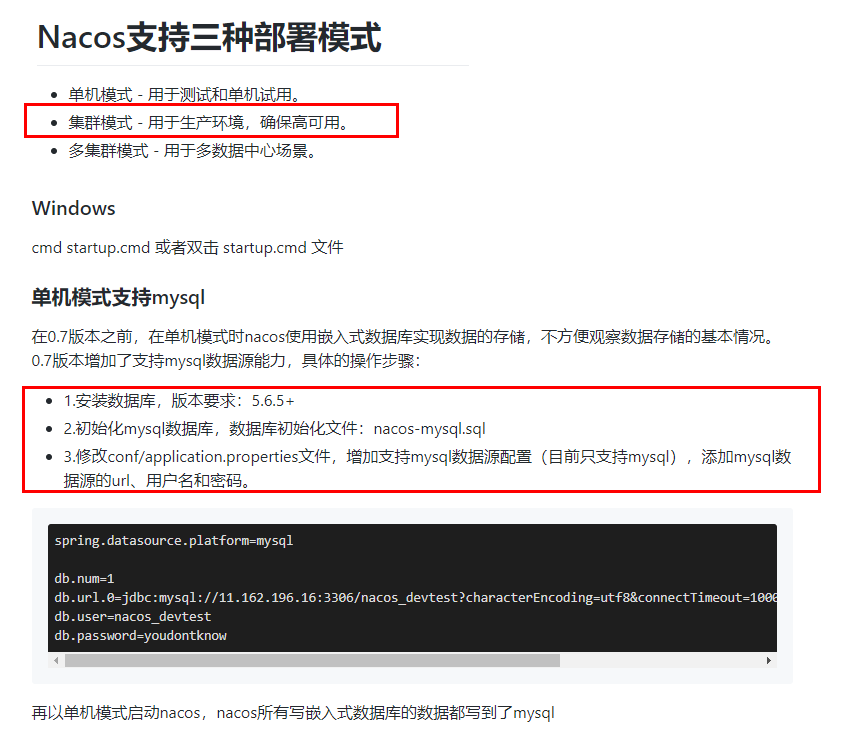
按照上述,我们需要mysql数据库
官网说明:https://nacos.io/zh-cn/docs/deployment.html
5.2、Nacos持久化配置解释
5.2.1、Nacos默认自带的是嵌入式数据库derby
https://github.com/alibaba/nacos/blob/develop/config/pom.xml
观察到pom文件引入了derby
5.2.2、derby到mysql切换配置步骤
nacos安装目录conf目录下找到sql脚本
新版是mysql-schema.sql,执行脚本(新版需要自建数据库)
nacos安装目录conf目录下找到application.properties
添加配置
1
2
3
4
5
6spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=123456
5.2.3、启动
启动Nacos,可以看到是个全新的空记录界面,以前是记录进derby
5.2.4、新建配置文件
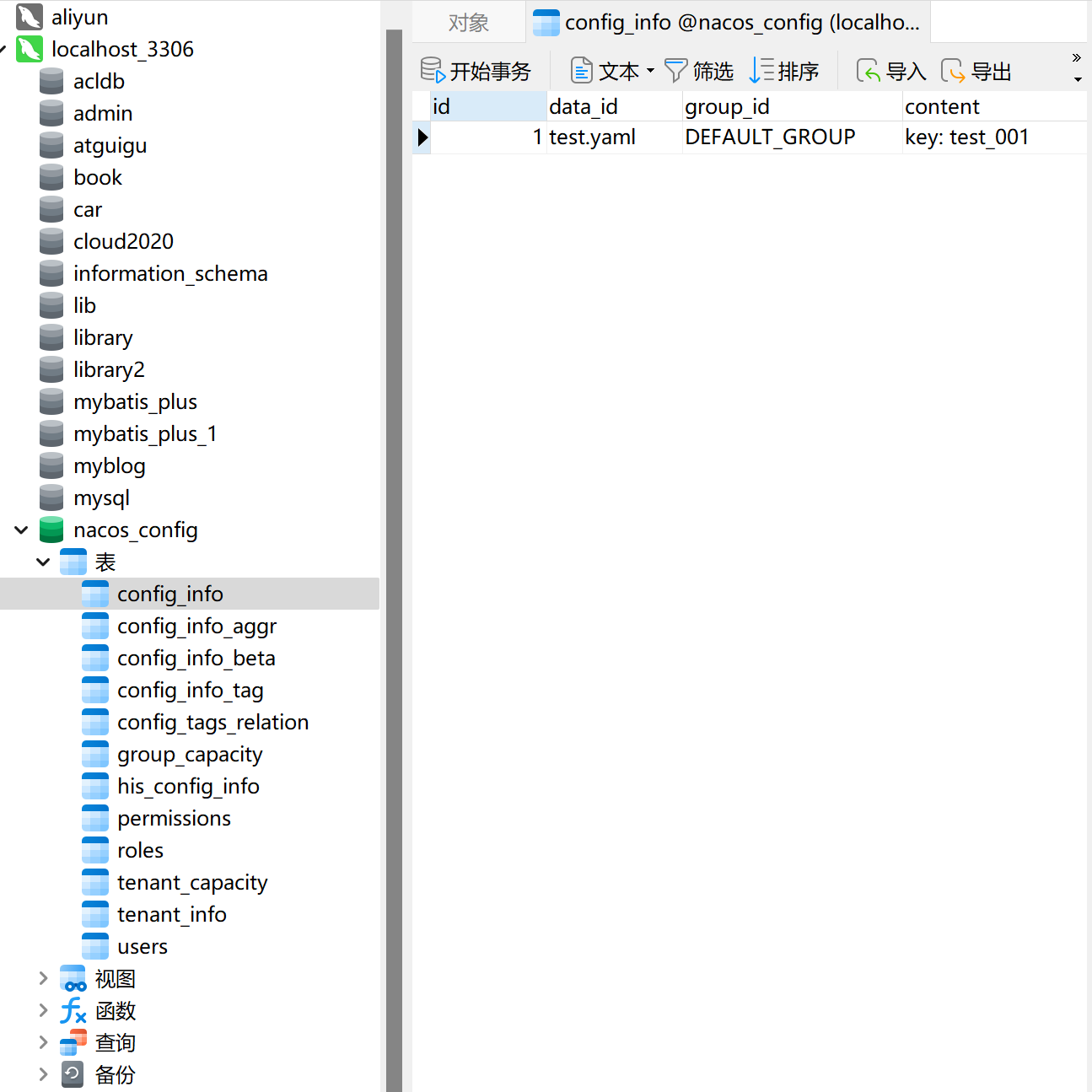
已经保存进mysql数据库
5.3、Linux版 Nacos+MySQL生产环境配置
这个章节一堆坑!!!!!!
若是三台机器搭建需要每一台都按照如下配置
5.3.1、首先安装好mysql
Linux 安装Mysql 详细教程(图文教程)-CSDN博客
5.3.2、安装jdk(1.8+)
Linux 安装JDK详细步骤_linux 安装 jdk_Charge8的博客-CSDN博客
5.3.3、安装Nacos
Release 2.2.1 (Mar 17th, 2023) · alibaba/nacos · GitHub
5.3.4、Linux服务器上mysql数据库配置
SQL脚本在哪里:
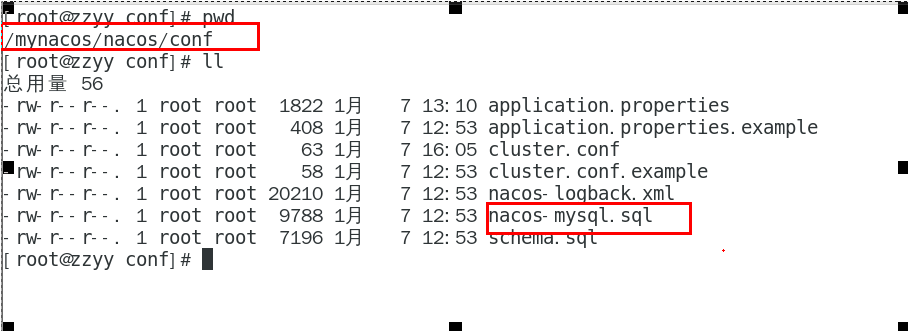
复制sql语句执行即可
5.3.5、application.properties 配置
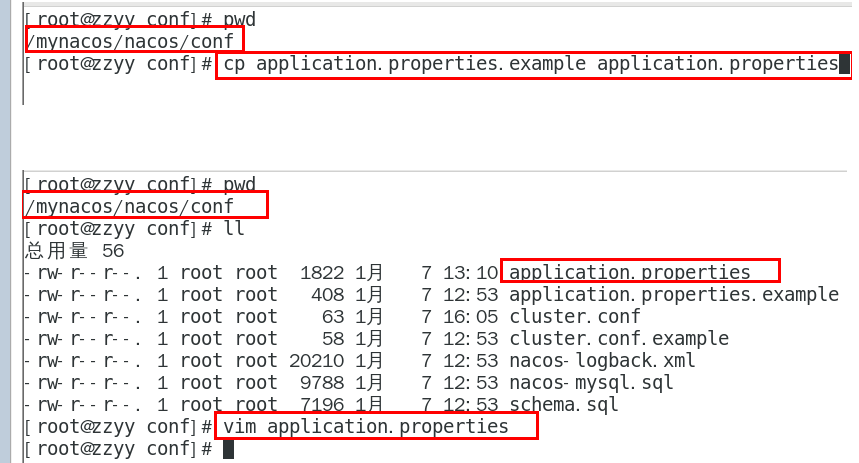
更改数据存放位置:
1 | spring.datasource.platform=mysql |
新版的需要修改配置application.properties!!!!!!!!
nacos.core.auth.plugin.nacos.token.secret.key=
报错改一下午!!!!
key可以通过以上的类进行生成:[tip](# 2.2、解压安装包,直接运行bin目录下的startup.cmd)
5.3.6、需要更改机器的hostname
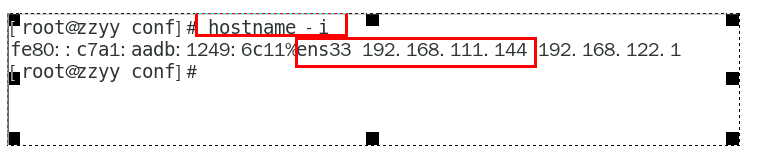
hostname -i 查看主机名(不能是127.0.0.1)
如果是,需要修改:
vi /etc/hostname
1 | 直接写名字 |
继续 vi /etc/hosts
主机映射:
1 | 192.168.131.101(主机实际ip) centos01 |
然后重启才可以生效
5.3.7、Linux服务器上nacos的集群配置cluster.conf
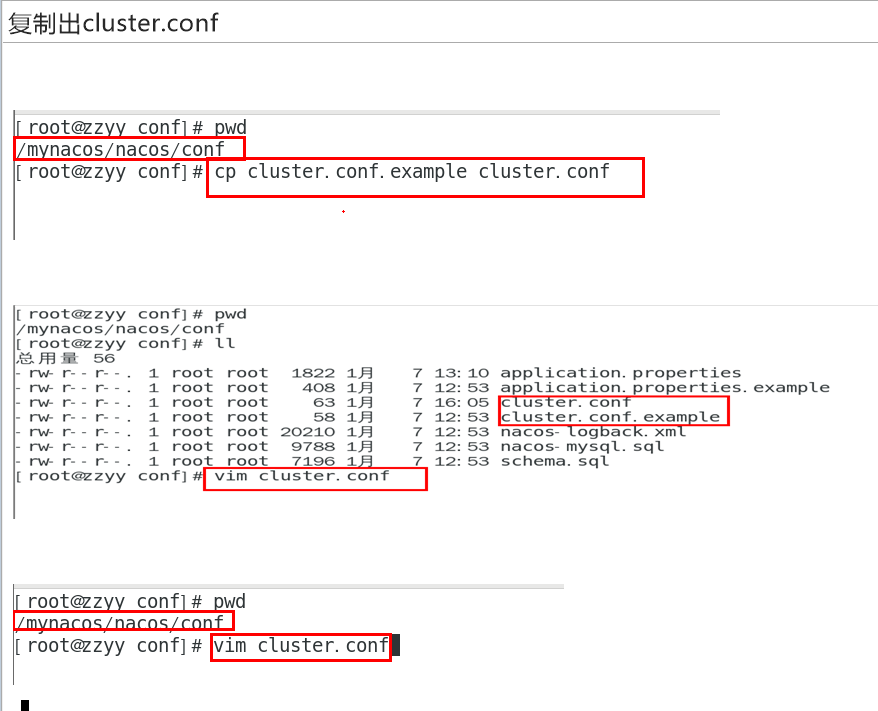
如果是伪分布集群可以:
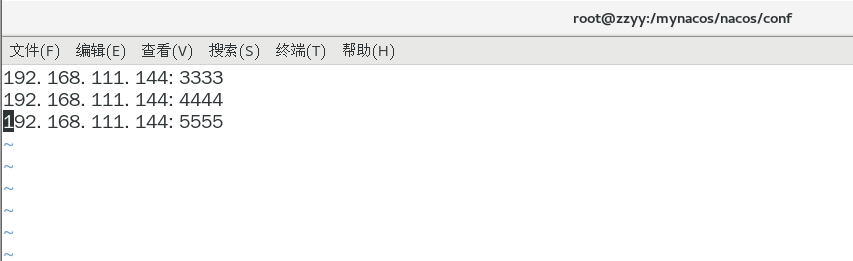
这个IP不能写127.0.0.1,必须是
Linux命令hostname -i能够识别的IP
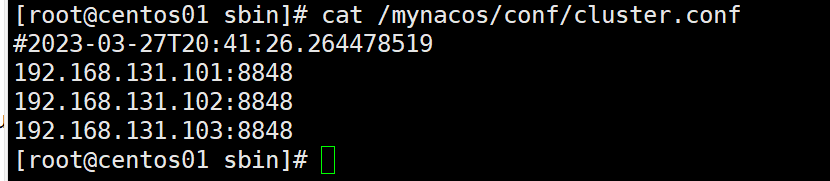
真实三台机器:
5.3.8、编辑Nacos的启动脚本startup.sh,使它能够接受不同的启动端口
新版已经自带这个功能了(不是伪分布式和新版的可以跳过)
/mynacos/nacos/bin 目录下有startup.sh
平时单机版的启动,都是./startup.sh即可。
但是
集群启动,我们希望可以类似其它软件的shell命令,传递不同的端口号启动不同的nacos实例。
命令:./startup.sh -p 3333 表示启动端口号为3333的nacos服务器实例,和上一步的cluster.conf配置的一致。

执行方式: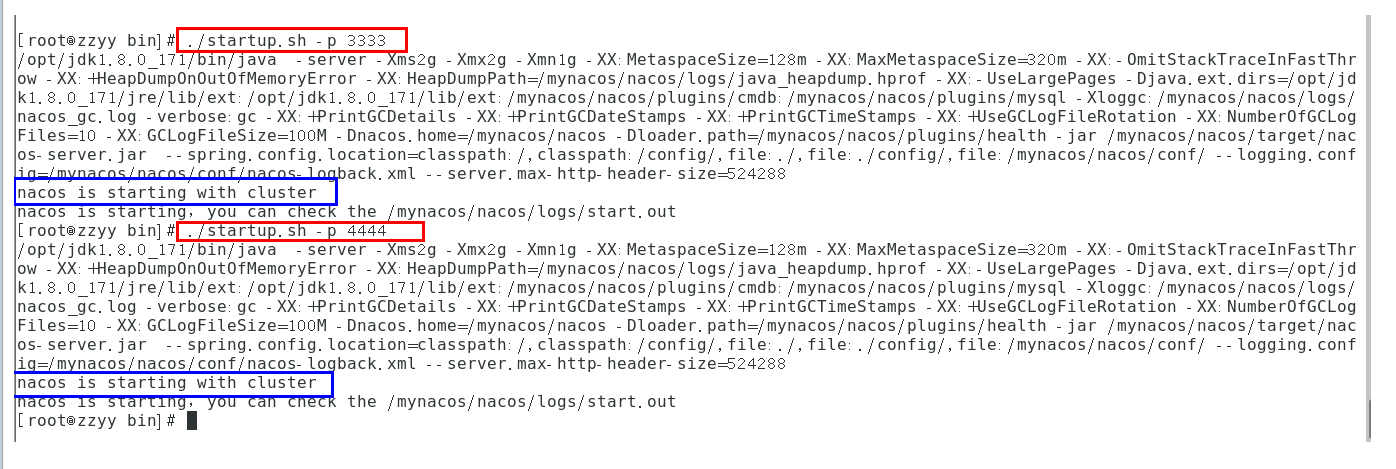
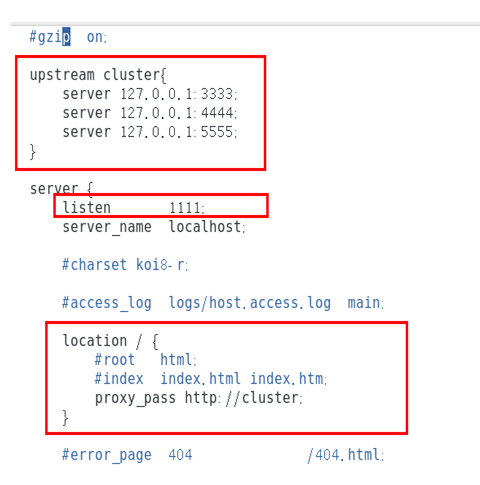
5.3.9、Nginx的配置,由它作为负载均衡器
安装好nginx
修改配置文件:
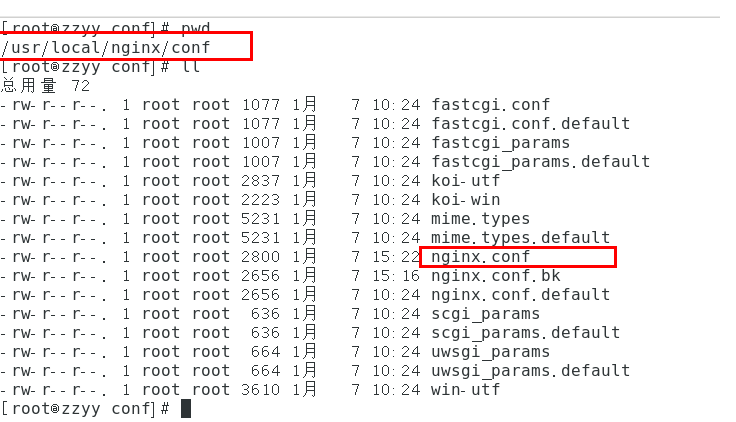
老版:
1 | upstream cluster{ |
新版有grpc,需要多以下配置,否则启动报错:
1 | # nacos服务器grpc相关地址和端口,需要nginx已经有stream模块 |
按照指定启动
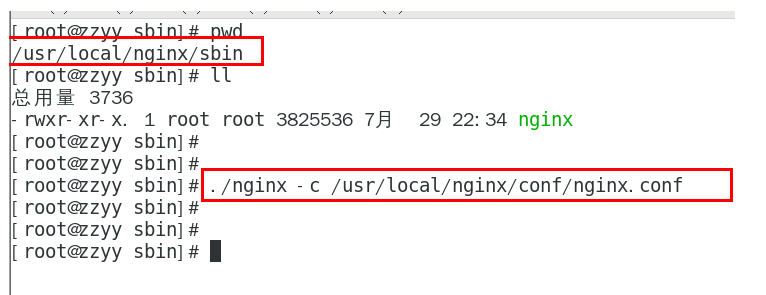
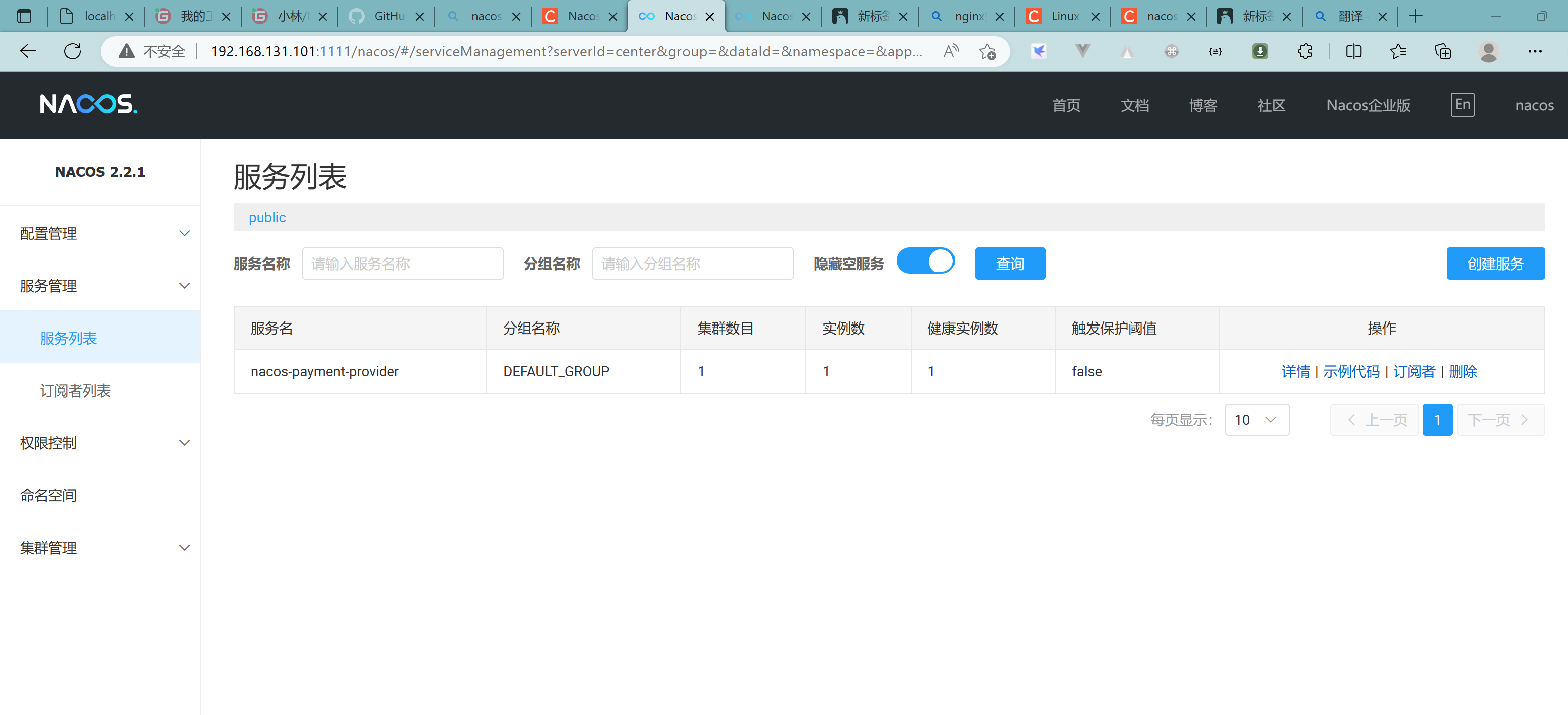
5.3.10、截止到此处,1个Nginx+3个nacos注册中心+1个mysql
测试通过nginx访问nacos
http://192.168.131.101:1111/nacos/#/login
新建一个配置测试:
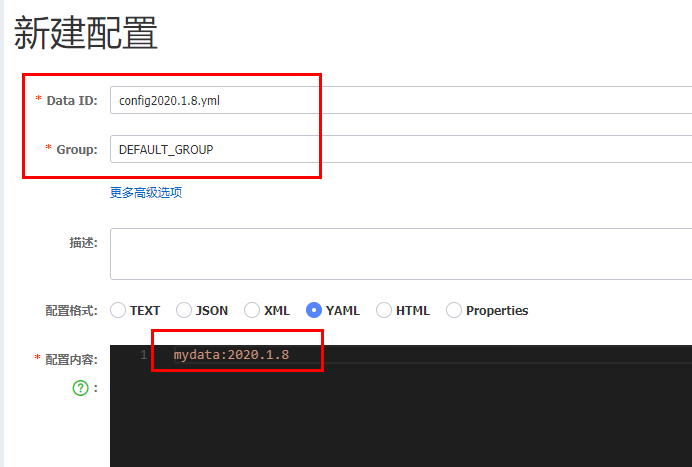
linux服务器的mysql插入一条记录

如果想要三台机器的数据统一,则必须配置同一个数据库
5.3.11、微服务cloudalibaba-provider-payment9002启动注册进nacos集群
5.3.12、高可用小总结
三、SpringCloud Alibab Sentinel实现熔断与限流
1、Sentinel
1.1、官网
https://github.com/alibaba/Sentinel
中文:introduction | Sentinel (sentinelguard.io)
1.2、是什么

一句话解释,之前我们学过的Hystrix
1.3、去哪下
https://github.com/alibaba/Sentinel/releases
下载jar包
1.4、能干嘛
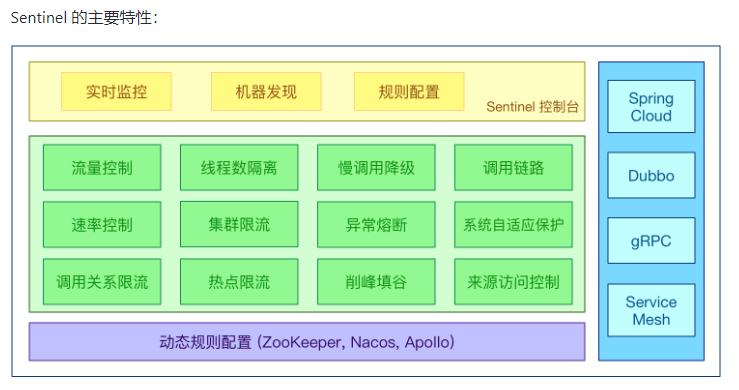
1.5、怎么玩
服务使用中的各种问题:
- 服务雪崩
- 服务降级
- 服务熔断
- 服务限流
2、安装Sentinel控制台
2.1、sentinel组件由2部分构成

- 后台
- 前台8080
2.2、安装步骤
2.2.1、下载
https://github.com/alibaba/Sentinel/releases
2.2.2、运行命令
前提:
- java8环境ok
- 8080端口不能被占用
命令:java -jar sentinel-dashboard-1.8.6.jar
2.2.3、访问sentinel管理界面
登录账号密码均为sentinel
3、初始化演示工程
3.1、启动Nacos8848成功
http://localhost:8848/nacos/#/login
3.2、Module
3.2.1、新建cloudalibaba-sentinel-service8401
3.2.2、改pom文件
1 |
|
3.2.3、改yml文件
1 | server: |
3.2.4、主启动类
1 | package com.lxg.springcloud; |
3.2.5、controller
1 | package com.lxg.springcloud.controller; |
3.2.6、启动Sentinel8080
java -jar sentinel-dashboard-1.8.6.jar
3.2.7、启动微服务8401
3.2.8、查看sentinel控制台
发现现在空空如也
Sentinel采用的懒加载说明:需要执行访问
执行一次访问即可:
效果:
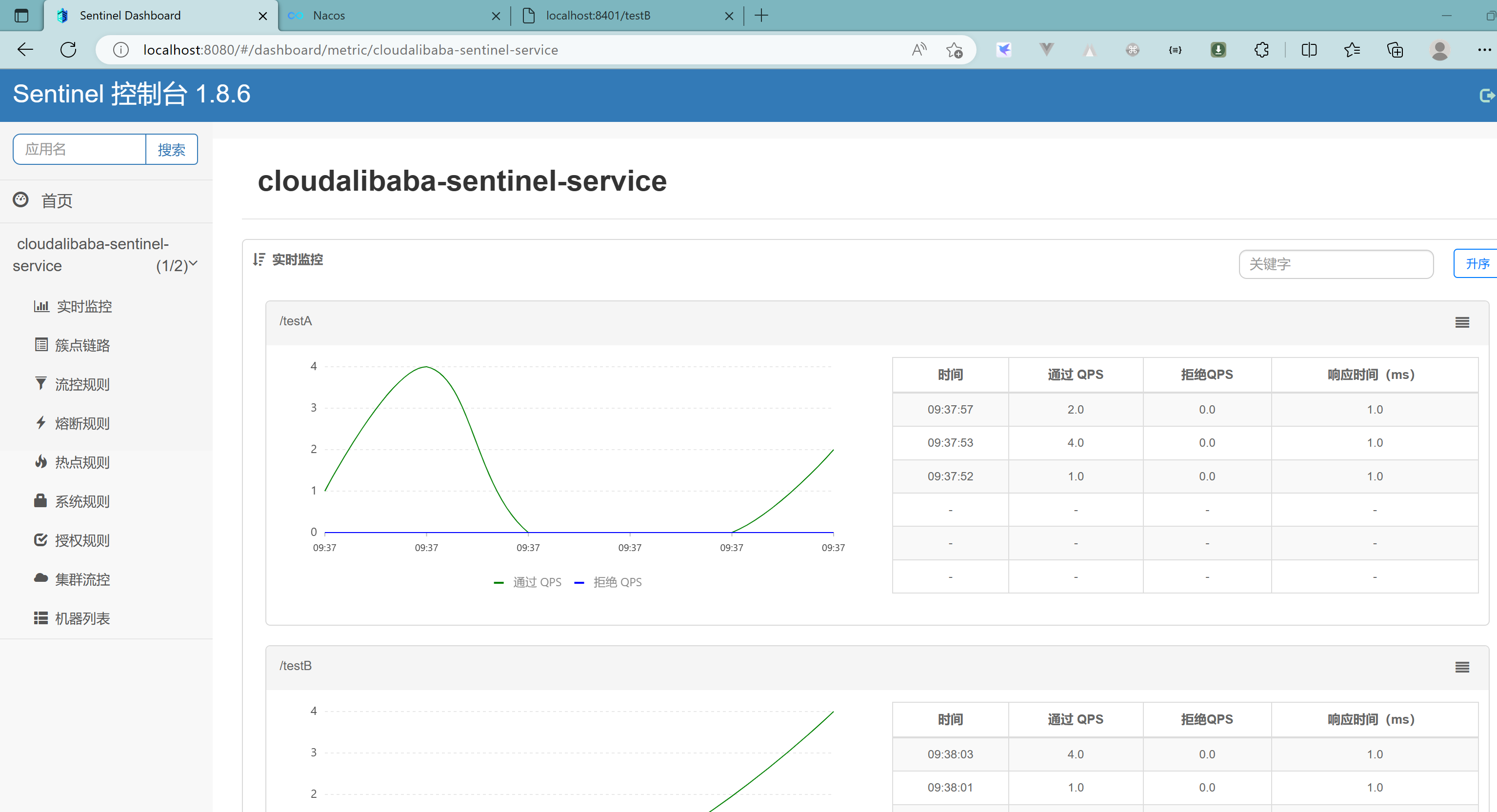
结论:
sentinel8080正在监控微服务8401
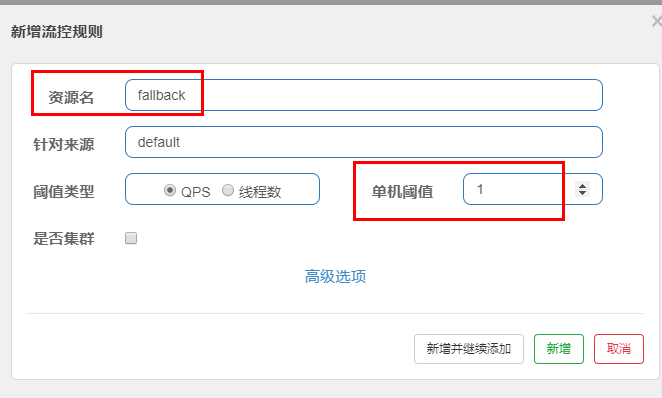
4、流控规则
4.1、基础介绍
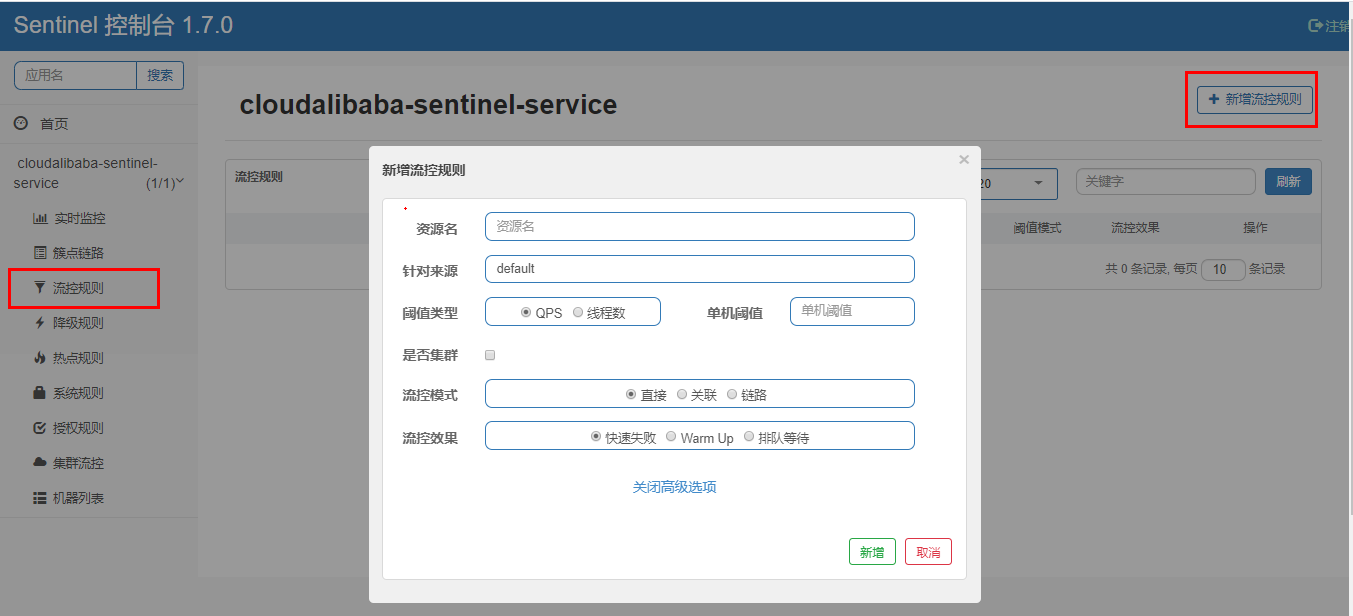
进一步解释说明:

4.2、流控模式
4.2.1、直接(默认)
直接->快速失败:系统默认
配置及说明:
表示1秒钟内查询1次就是OK,若超过次数1,就直接-快速失败,报默认错误
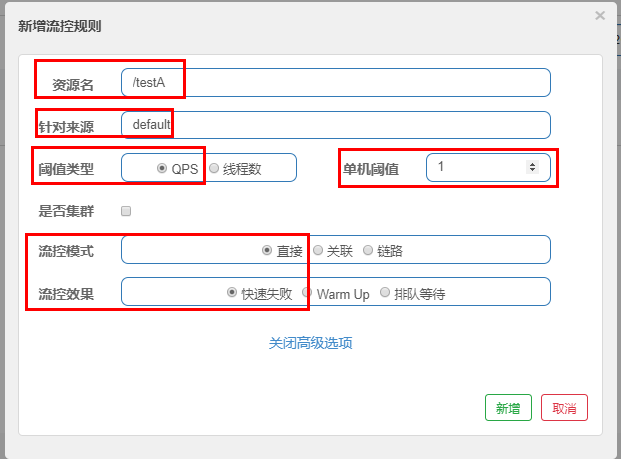
测试:
快速点击访问http://localhost:8401/testA
结果:Blocked by Sentinel (flow limiting)
思考:
直接调用默认报错信息,技术方面OK
but,是否应该有我们自己的后续处理?
类似有个fallback的兜底方法?
转到其他页面?
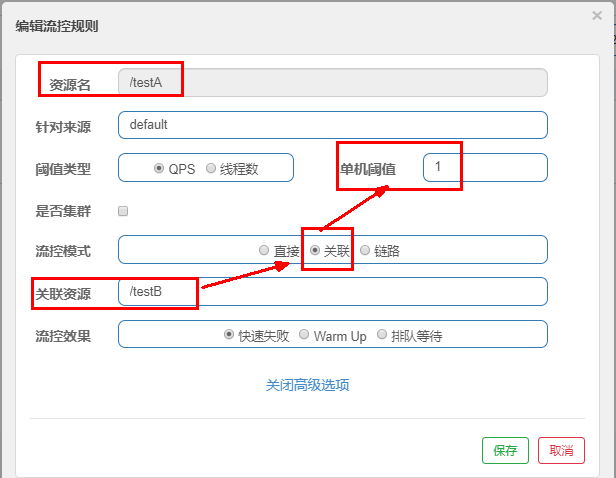
4.2.2、关联模式
是什么:
- 当关联的资源达到阈值时,就限流自己
- 当与A关联的资源B达到阀值后,就限流A自己
- B惹事,A挂了
配置A:
设置效果
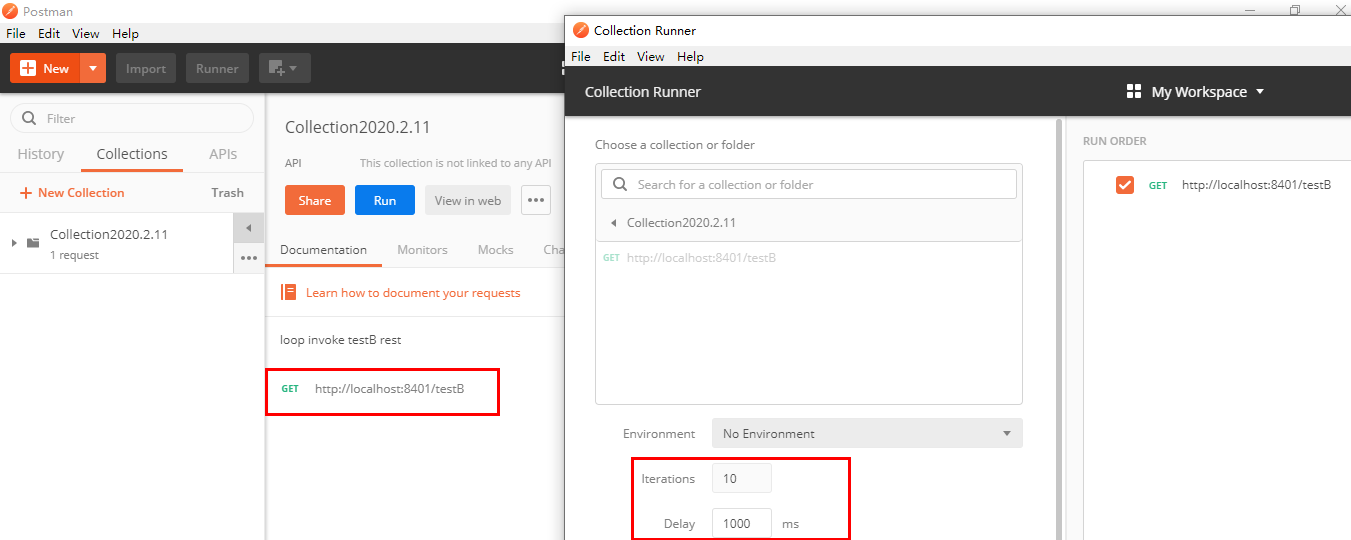
当关联资源/testB的qps阀值超过1时,就限流/testA的Rest访问地址,当关联资源到阈值后限制配置好的资源名
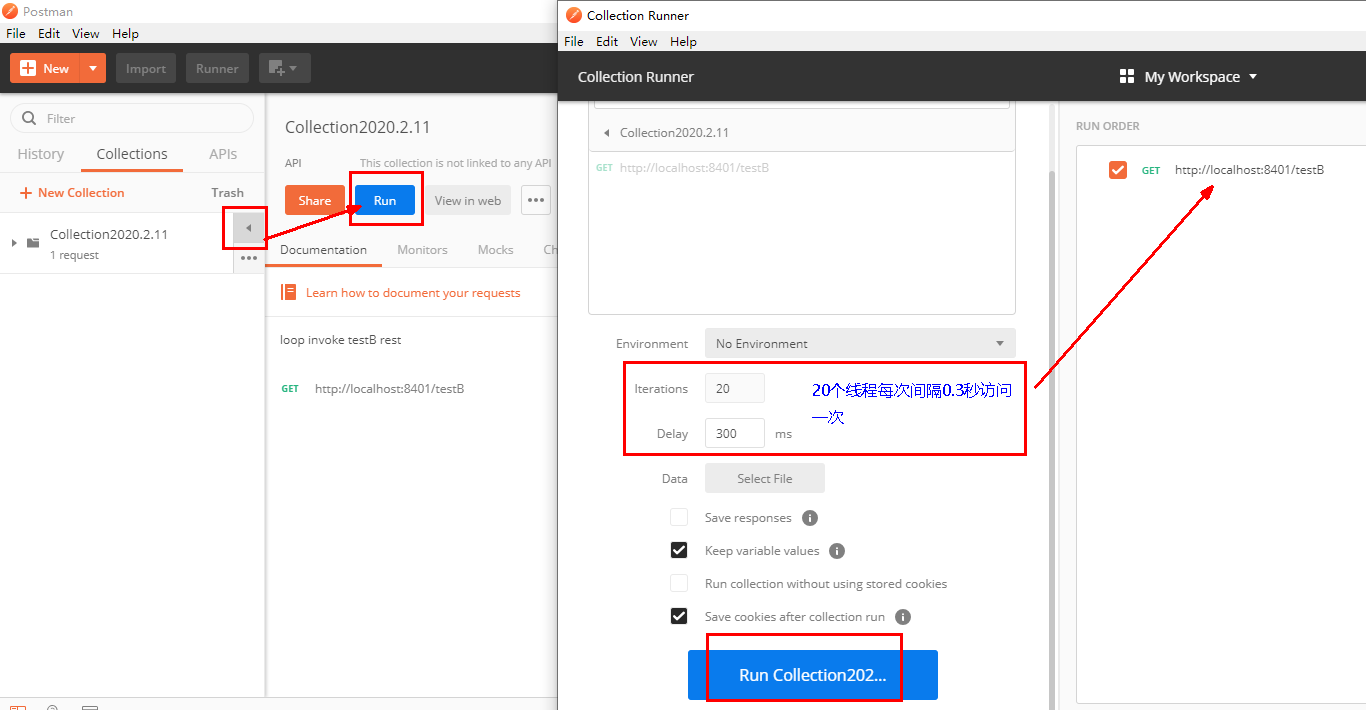
postman模拟并发密集访问testB
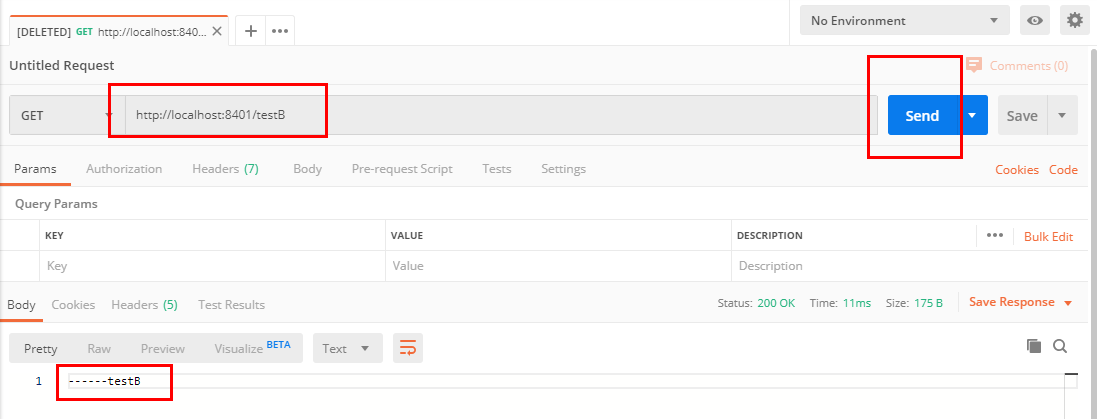
访问testB成功
postman里新建多线程集合组
将访问地址添加进新新线程组
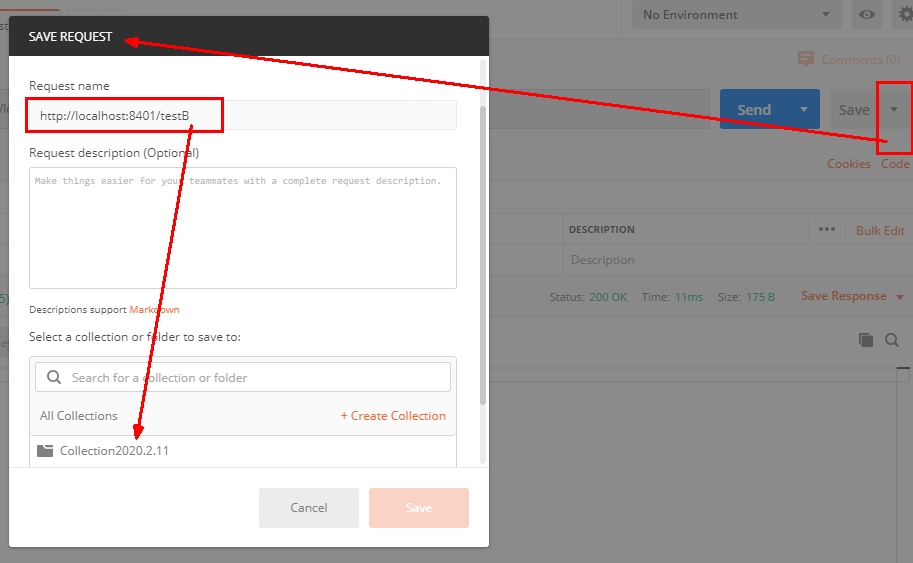
Run
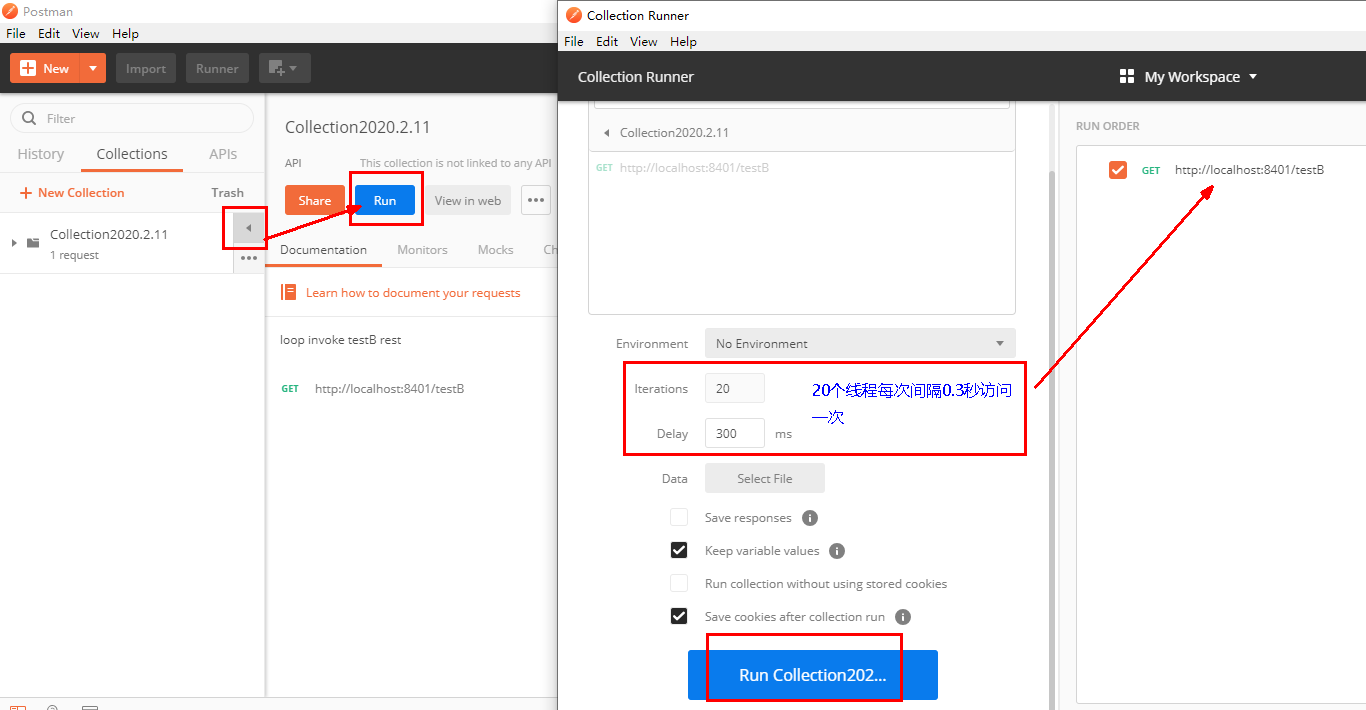
大批量线程高并发访问B,导致A失效了
运行后发现testA挂了
点击访问http://localhost:8401/testA
Blocked by Sentinel (flow limiting)
4.2.3、链路模式
多个请求调用了同一个微服务
针对上一级接口进行限流
可以对test1或test2进行限流
Sentinel-限流规则(流控模式:直接、关联、链路)_sentinel 关联 链路_其然乐衣的博客-CSDN博客
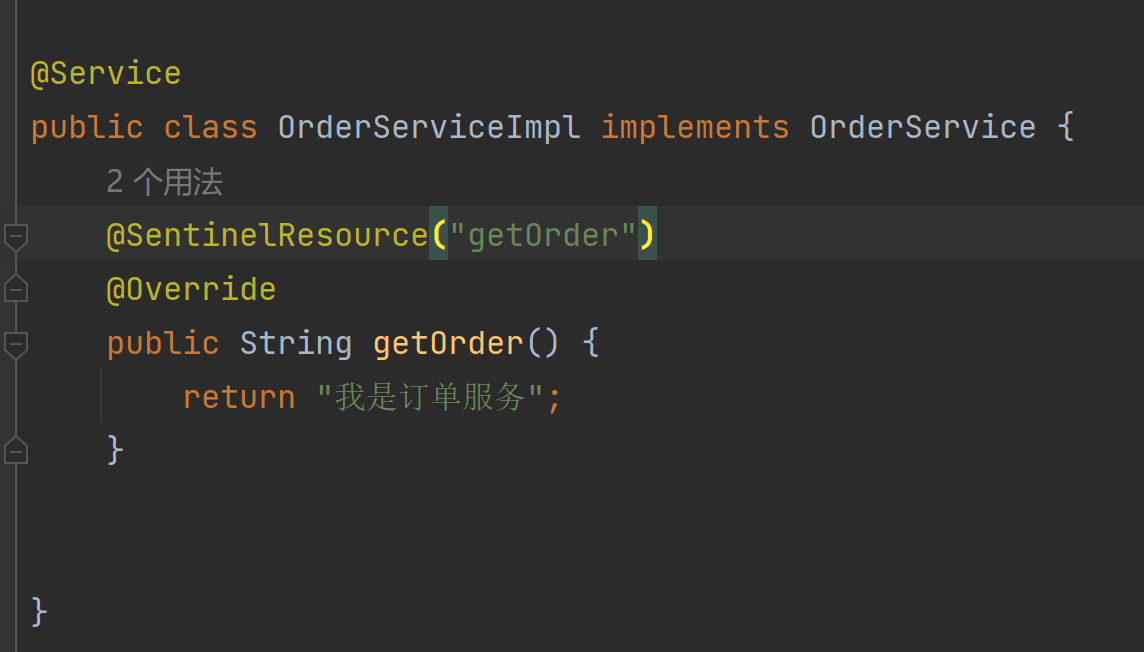
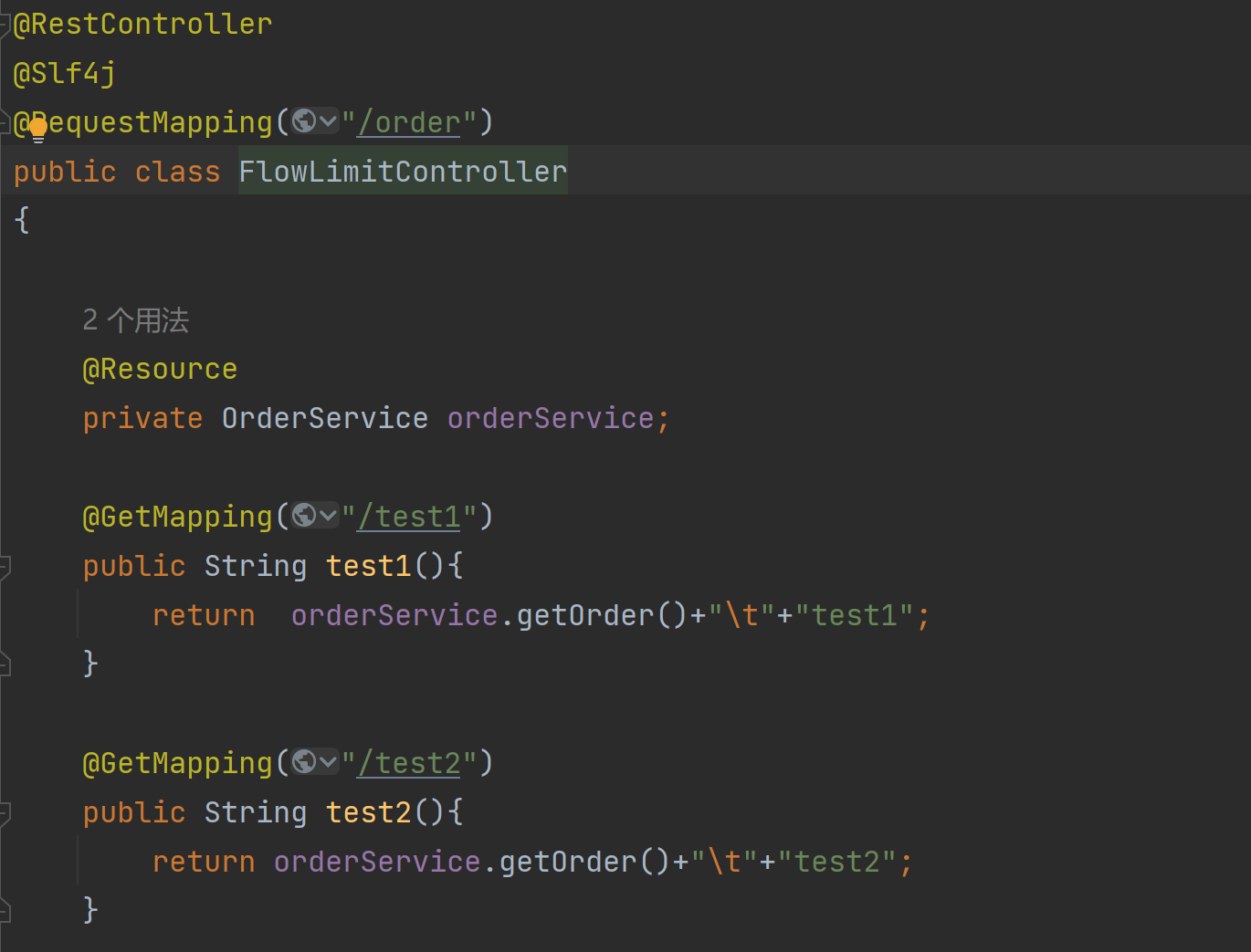
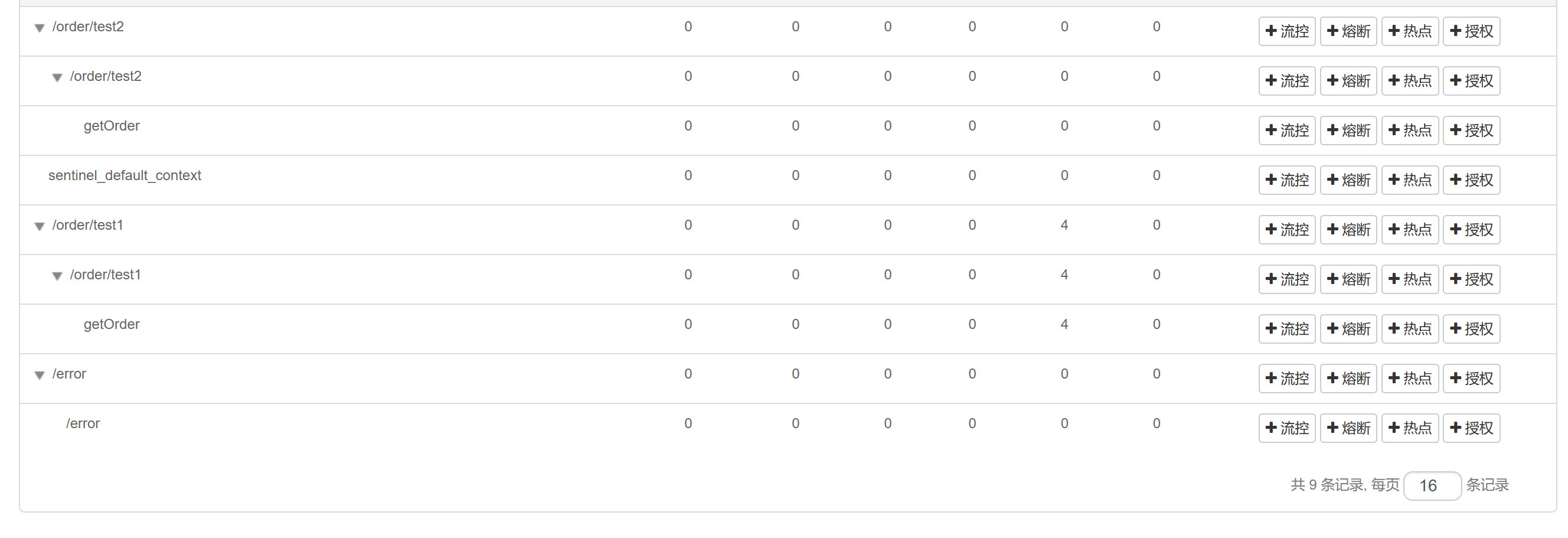
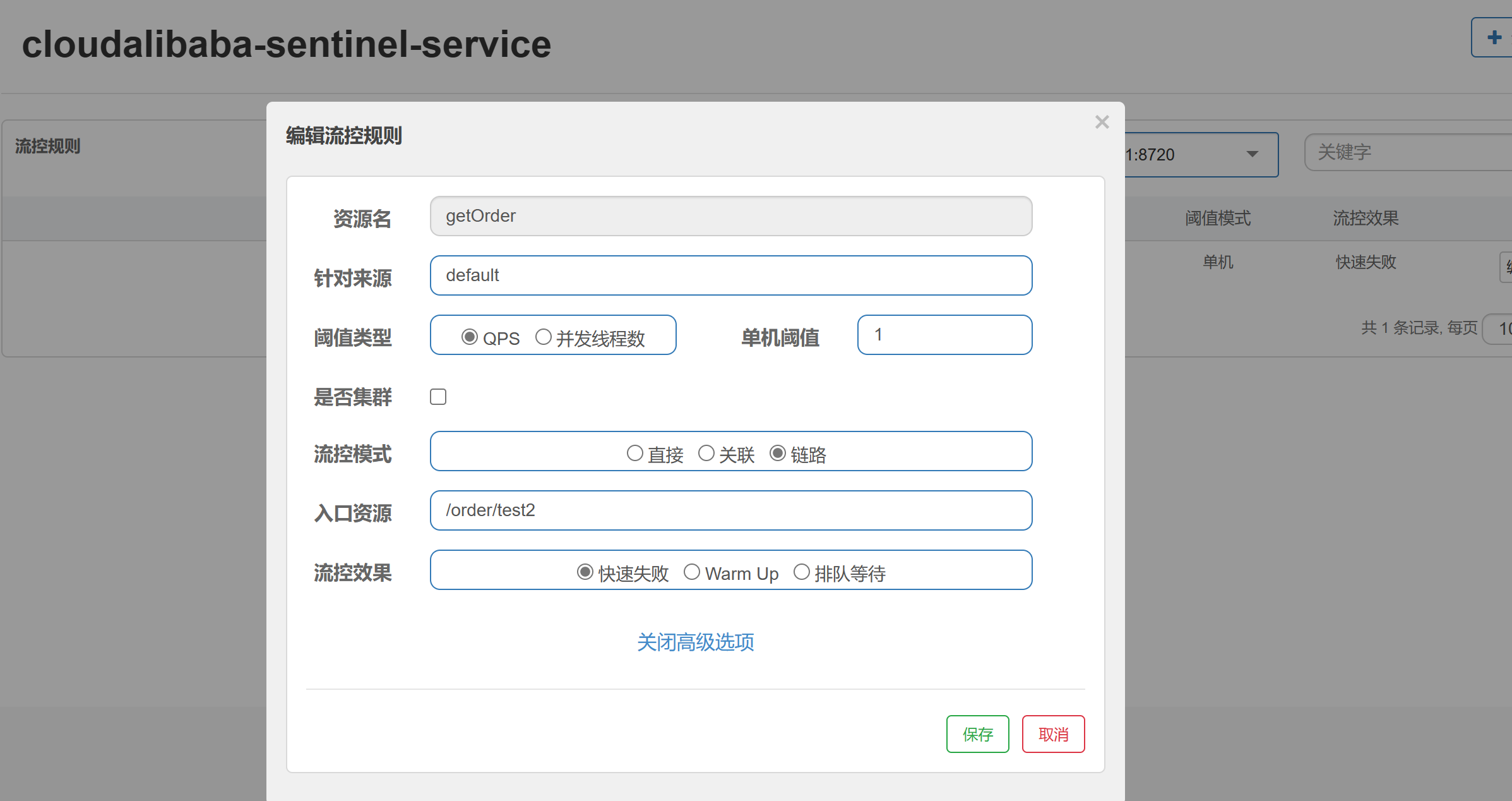
被调用的getorder服务达到阈值时,限制/order/test2,而/order/test1没事
5、流控效果
5.1、直接->快速失败
直接失败,抛出异常:Blocked by Sentinel (flow limiting)
源码:com.alibaba.csp.sentinel.slots.block.flow.controller.DefaultController
5.2、预热
5.2.1、说明:
公式:阈值除以coldFactor(默认值为3),经过预热时长后才会达到阈值
5.2.2、官网:
https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
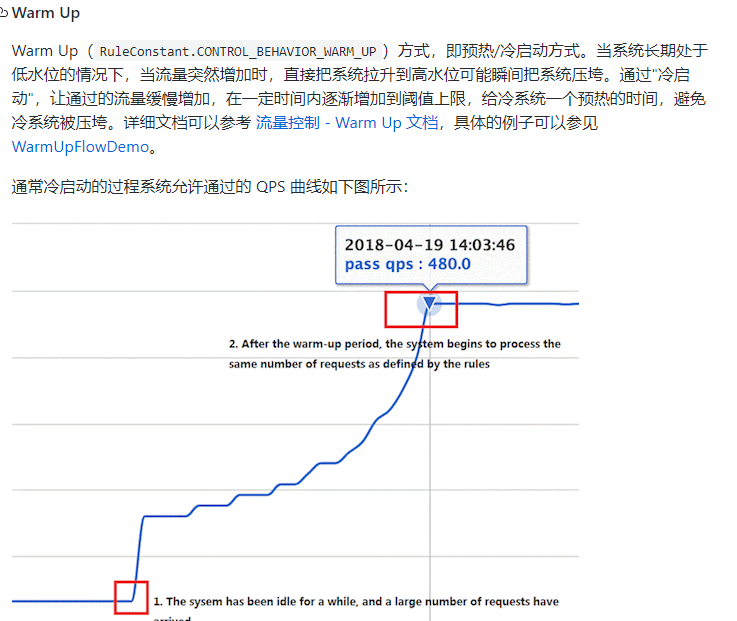
默认coldFactor为3,即请求 QPS 从 threshold / 3 开始,经预热时长逐渐升至设定的 QPS 阈值。
限流 冷启动:限流 冷启动 · alibaba/Sentinel Wiki · GitHub
5.2.3、源码
com.alibaba.csp.sentinel.slots.block.flow.controller.WarmUpController

5.2.4、warmup配置
默认 coldFactor 为 3,即请求QPS从(threshold / 3) 开始,经多少预热时长才逐渐升至设定的 QPS 阈值。
案例,阀值为10+预热时长设置5秒。
系统初始化的阀值为10 / 3 约等于3,即阀值刚开始为3;然后过了5秒后阀值才慢慢升高恢复到10
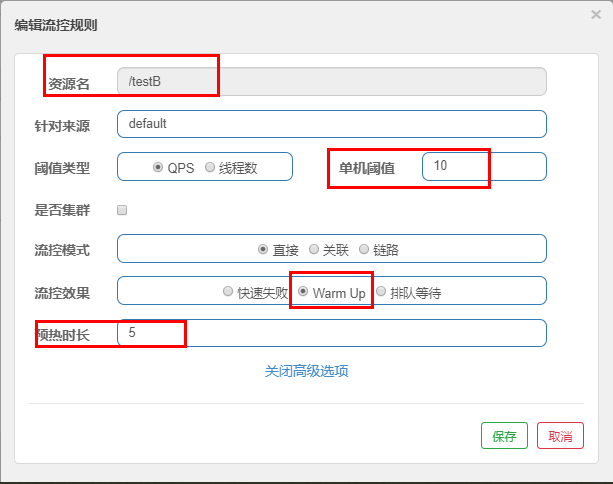
多次点击http://localhost:8401/testB
刚开始不行,后续慢慢OK
5.2.5、应用场景
如:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阀值增长到设置的阀值。
5.3、排队等待
匀速排队,阈值必须设置为QPS
5.3.1、官网

流量控制 匀速排队模式 · alibaba/Sentinel Wiki · GitHub
5.3.2、源码
com.alibaba.csp.sentinel.slots.block.flow.controller.RateLimiterController
5.3.3、测试
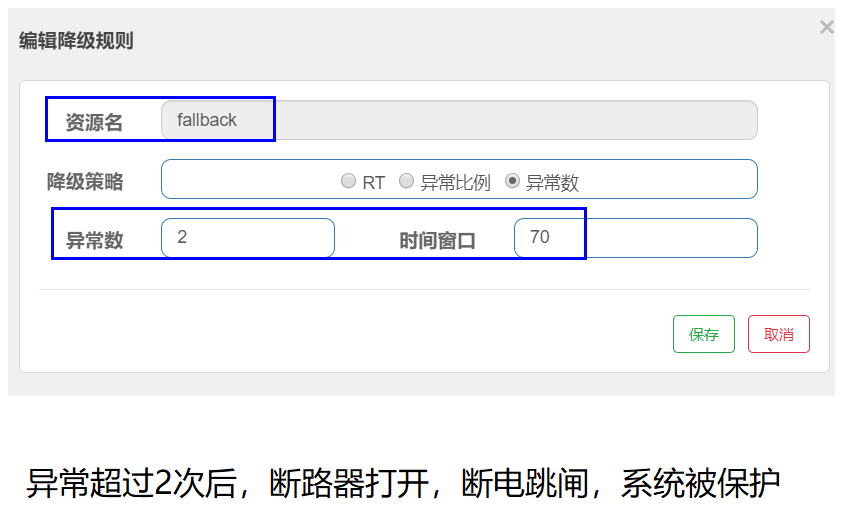
6、降级规则
6.1、官网、
熔断降级 · alibaba/Sentinel Wiki · GitHub
6.2、基本介绍
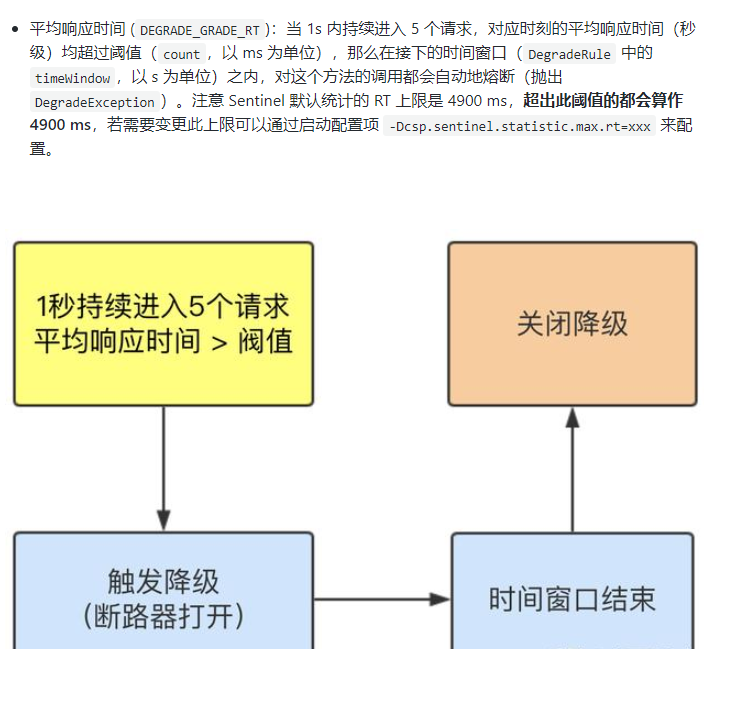
旧版:
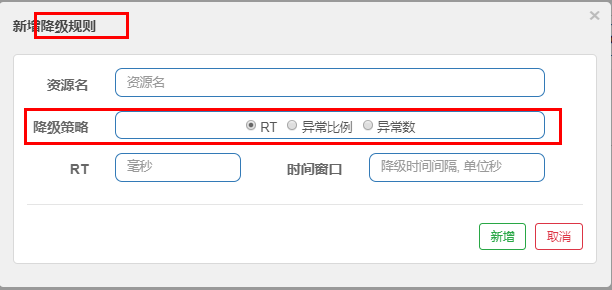
RT(平均响应时间,秒级)
平均响应时间 超出阈值 且 在时间窗口内通过的请求>=5,两个条件同时满足后触发降级
窗口期过后关闭断路器
RT最大4900(更大的需要通过-Dcsp.sentinel.statistic.max.rt=XXXX才能生效)
异常比列(秒级)
QPS >= 5 且异常比例(秒级统计)超过阈值时,触发降级;时间窗口结束后,关闭降级
异常数(分钟级)
异常数(分钟统计)超过阈值时,触发降级;时间窗口结束后,关闭降级
新版
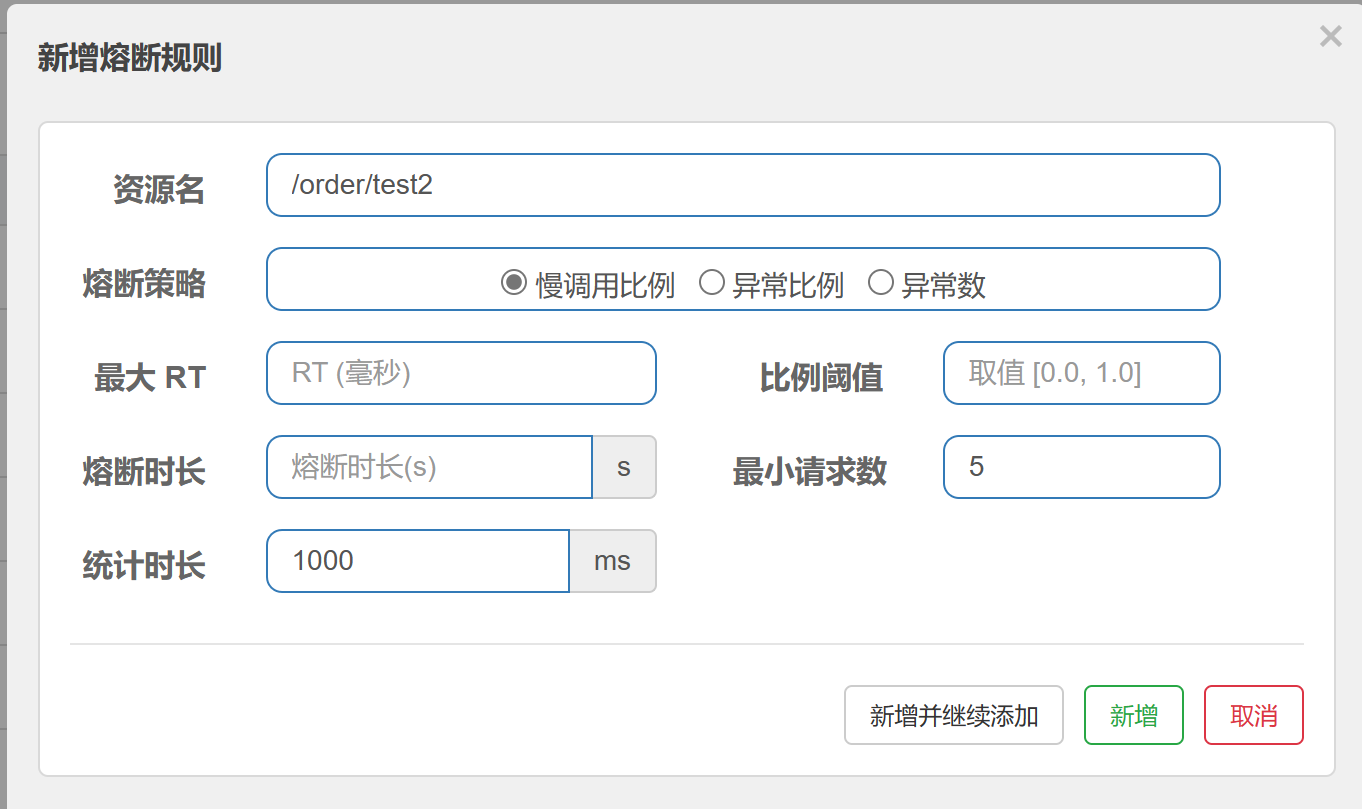
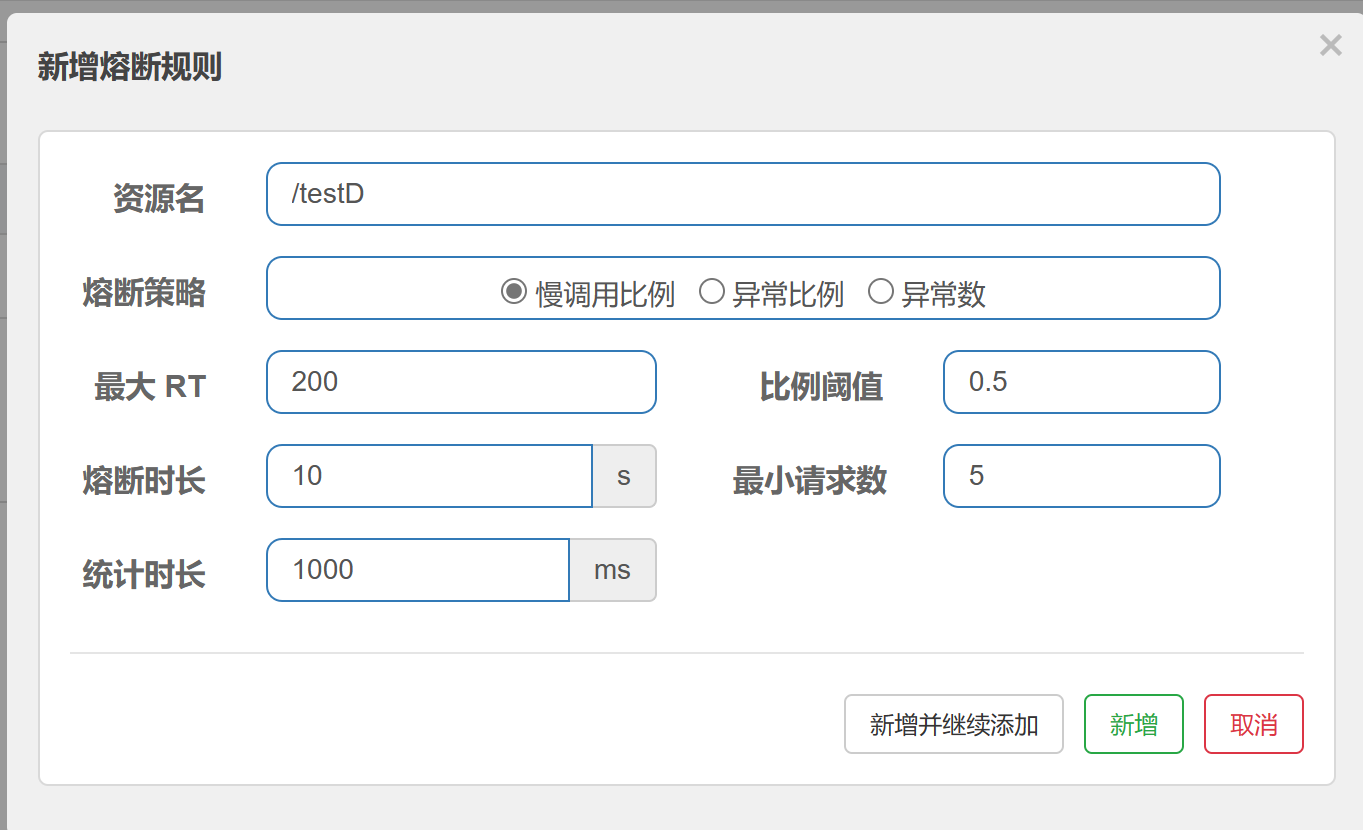
- 慢调用比例 (
SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。 - 异常比例 (
ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是[0.0, 1.0],代表 0% - 100%。 - 异常数 (
ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
6.2.1、进一步说明
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,
让请求快速失败,避免影响到其它的资源而导致级联错误。
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
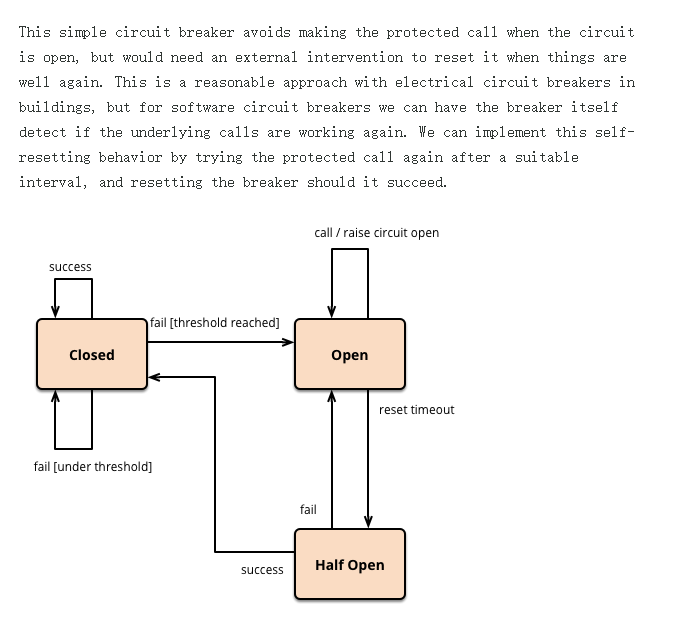
6.2.2、旧版Sentinel的断路器是没有半开状态的:
半开的状态系统自动去检测是否请求有异常,
没有异常就关闭断路器恢复使用,
有异常则继续打开断路器不可用。(这样再过窗口期设置时间过才能转到半开状态)具体可以参考Hystrix
复习Hystrix:
6.3、降级策略实战
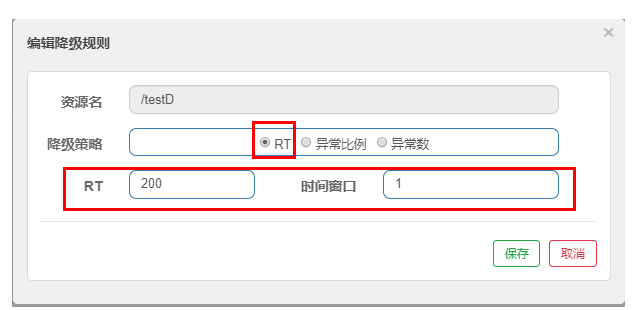
6.3.1、RT(老版)
是什么:
测试:
代码:
1 |
|
配置:
jmeter压测:
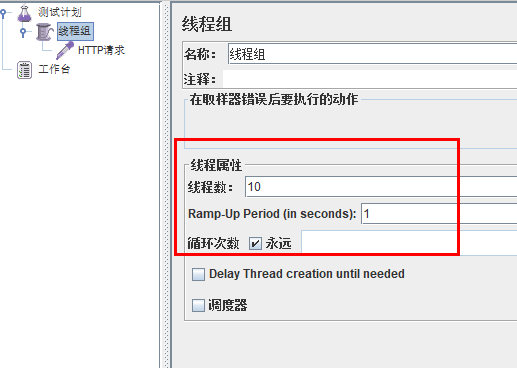
结论:
按照上述配置,
永远一秒钟打进来10个请求(大于5个了)调用testD,我们希望200毫秒处理完本次任务,
如果超过200毫秒还没处理完,在未来1秒钟的时间窗口内,断路器打开(保险丝跳闸)微服务不可用,保险丝跳闸断电了
后续我停止jmeter,没有这么大的访问量了,断路器关闭(保险丝恢复),微服务恢复OK
6.3.2、慢调用比例(新版)
1.调用:一个请求发送到服务器,服务器给与响应,一个响应就是一个调用。
2.RT:响应时间,指系统对请求作出响应的时间。
3.慢调用:当调用的时间(响应的实际时间)>设置的RT的时,这个调用叫做慢调用。
4.慢调用比例:在所以调用中,慢调用占有实际的比例,= 慢调用次数 / 调用次数
5.比例阈值:自己设定的 , 慢调用次数 / 调用次数=比例阈值
统计时长:时间的判断依据
最小请求数:设置的调用最小请求数
进入熔断状态判断依据:当统计时常内,实际请求数目大于最小请求数目,慢调用比例> 比例阈值 ,进入熔断状态
熔断状态:在接下来的熔断时长内请求会自动被熔断
探测恢复状态:熔断时长结束后进入探测恢复状态
结束熔断:在探测恢复状态,如果接下来的一个请求响应时间小于设置的慢调用 RT,则结束熔断
否则继续熔断。
sentinel降级策略:慢调用比例_海滩超人的博客-CSDN博客
Sentinel熔断策略-慢调用比例_紫荆之后-的博客-CSDN博客
6.3.3、异常比例
是什么:
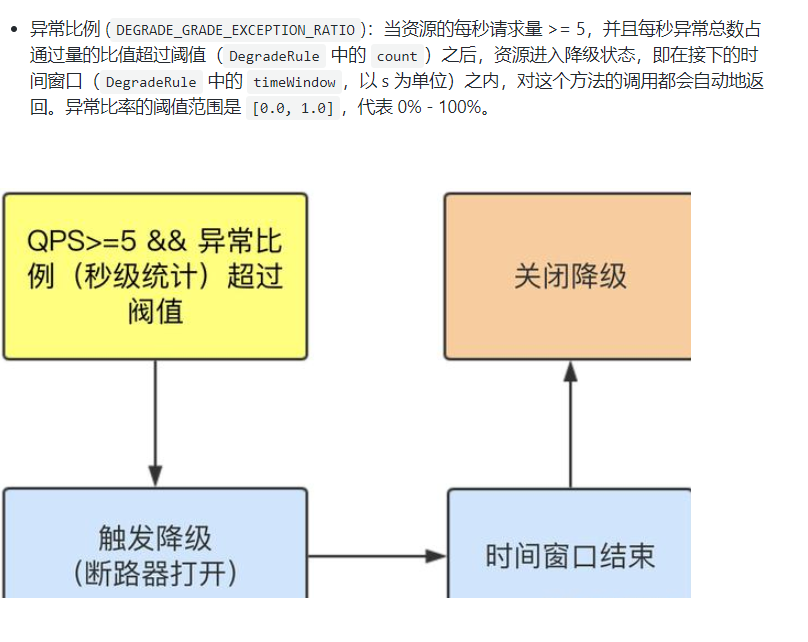
异常数是按照分钟统计的
测试:
代码:
1 |
|
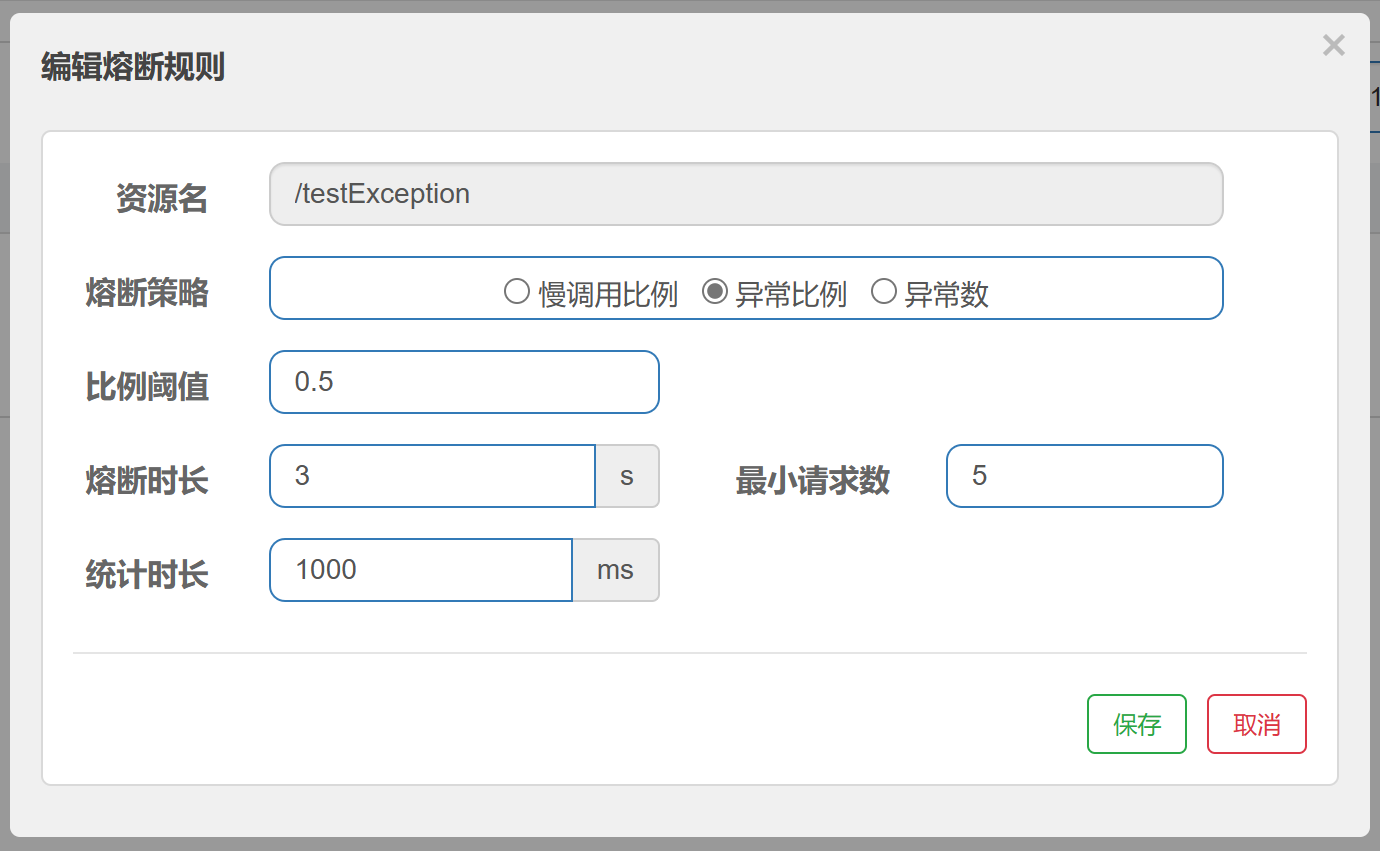
浏览器狂发请求,发现会进入熔断状态
由于每一次都是异常,半开尝试后仍然是异常,就继续熔断
6.3.3、异常数
是什么:
异常数 (ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
测试:
代码:
1 |
|
配置:
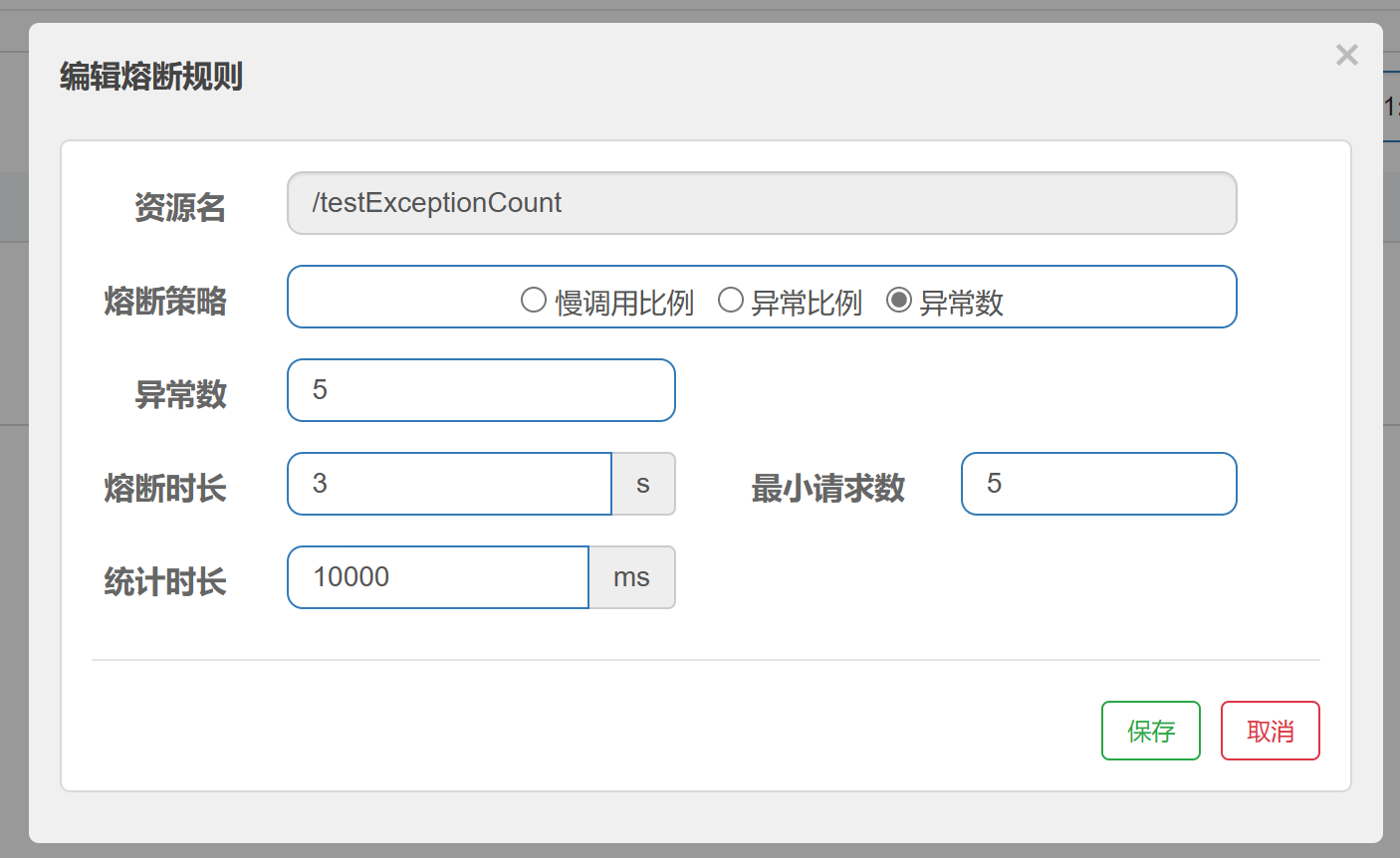
10秒内请求数大于5,且这些请求中有5个是异常即会进入熔断状态,等3秒后进入半开状态,如果下一个请求还异常就继续熔断3秒,如果正常就取消熔断,重新判断
7、热点key限流
7.1、基本介绍
是什么:
何为热点
热点即经常访问的数据,很多时候我们希望统计或者限制某个热点数据中访问频次最高的TopN数据,并对其访问进行限流或者其它操作
7.2、官网:
热点参数限流 · alibaba/Sentinel Wiki (github.com)
7.3、承上启下复习start
兜底方法
分为系统默认和客户自定义,两种
之前的case,限流出问题后,都是用sentinel系统默认的提示:Blocked by Sentinel (flow limiting)
我们能不能自定?类似hystrix,某个方法出问题了,就找对应的兜底降级方法?
结论
从HystrixCommand 到@SentinelResource
7.4、代码
1 |
|
com.alibaba.csp.sentinel.slots.block.BlockException
7.5、配置
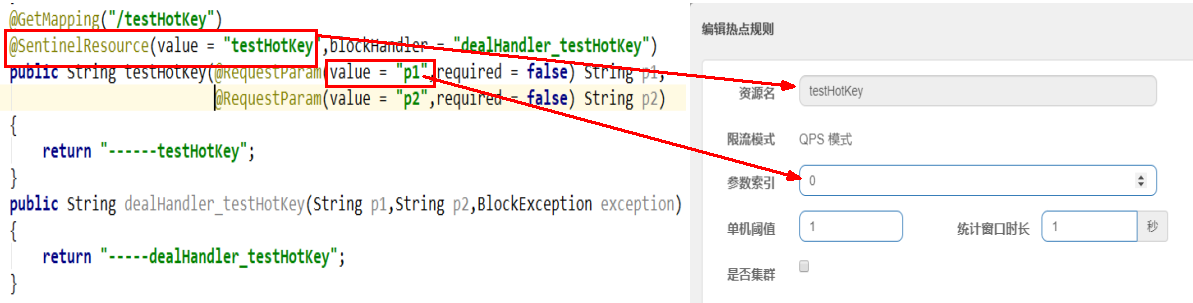
限流模式只支持QPS模式,固定写死了。(这才叫热点)
@SentinelResource注解的方法参数索引,0代表第一个参数,1代表第二个参数,以此类推
单机阀值以及统计窗口时长表示在此窗口时间超过阀值就限流。
上面的抓图就是第一个参数有值的话,1秒的QPS为1,超过就限流,限流后调用dealHandler_testHotKey支持方法。

@SentinelResource(value = “testHotKey”)
异常打到了前台用户界面看到,不友好
@SentinelResource(value = “testHotKey”,blockHandler = “dealHandler_testHotKey”)
方法testHotKey里面第一个参数只要QPS超过每秒1次,马上降级处理
用了我们自己定义的
7.6、测试
error:http://localhost:8401/testHotKey?p1=abc
error:http://localhost:8401/testHotKey?p1=abc&p2=33
right:http://localhost:8401/testHotKey?p2=abc
7.7、参数例外项
7.7.1、配置
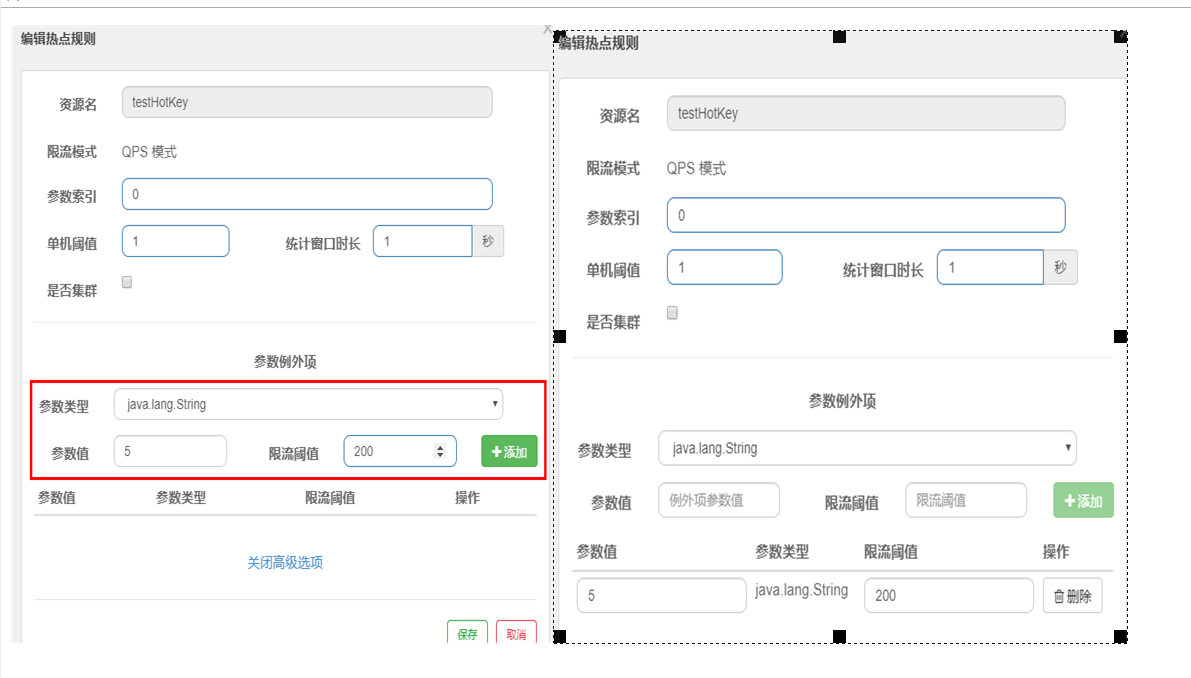
添加按钮不能忘
7.7.2、测试
right:http://localhost:8401/testHotKey?p1=5
error:http://localhost:8401/testHotKey?p1=3
当p1等于5的时候,阈值变为200
当p1不等于5的时候,阈值就是平常的1
前提条件:热点参数的注意点,参数必须是基本类型或者String
7.8、其他
手贱添加异常看看……/(ㄒoㄒ)/~~
1 | @SentinelResource |
8、系统规则
8.1、是什么
系统自适应限流 · alibaba/Sentinel Wiki (github.com)
8.2、各项配置参数说明

配置全局QPS
9、@SentinelResource
9.1、按资源名称限流+后续处理
启动Nacos成功:http://localhost:8848/nacos/#/login
启动Sentinel成功:java -jar sentinel-dashboard-1.8.6.jar
9.1.1、修改cloudalibaba-sentinel-service8401
pom:(新增以下内容)
1 | <dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --> |
yml不变
controller:
1 | package com.lxg.springcloud.controller; |
9.1.2、配置规则
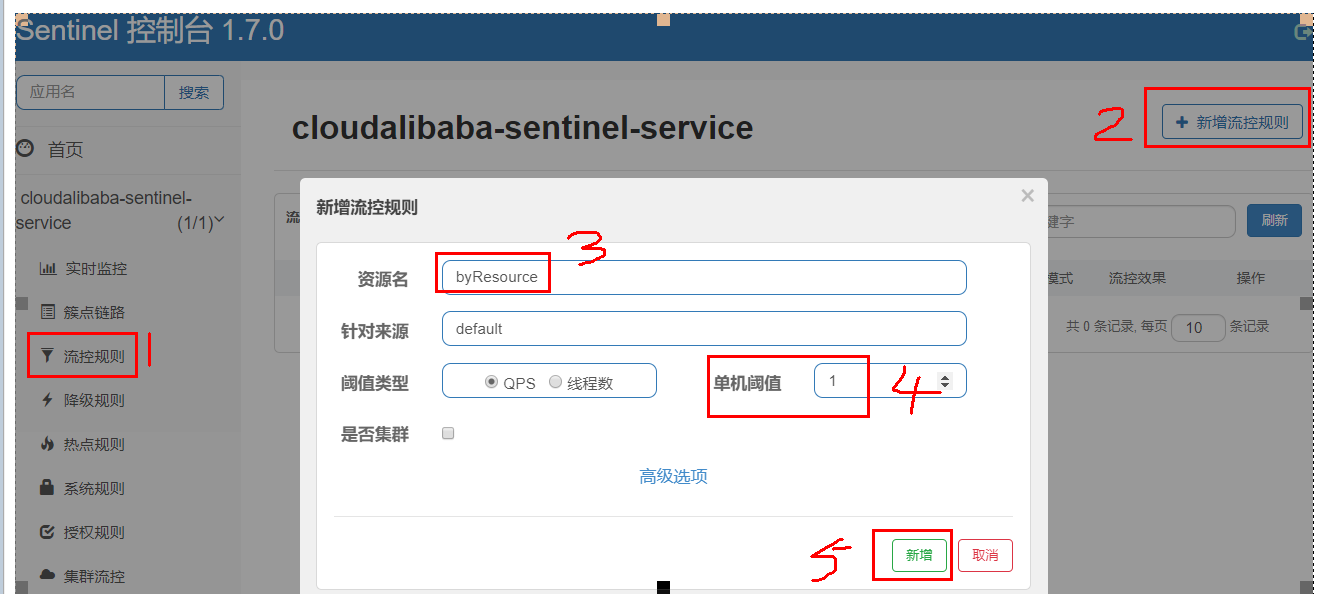
图形配置和代码关系
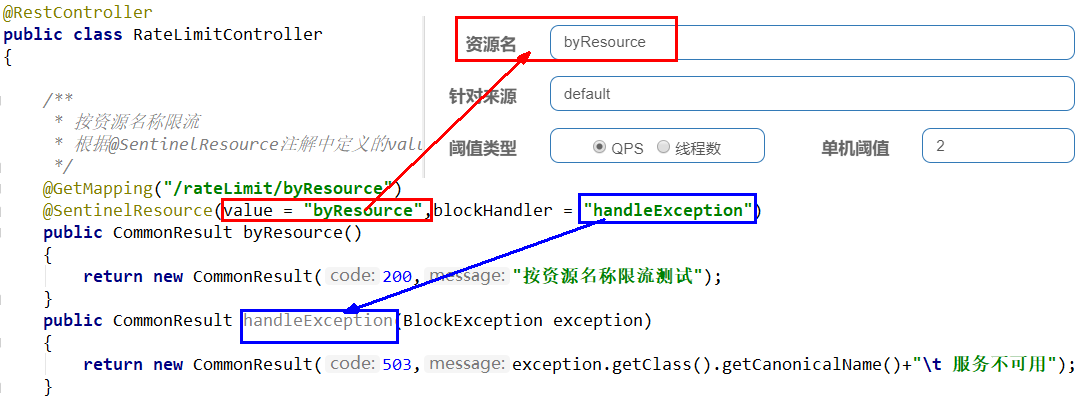
表示1秒钟内查询次数大于1,就跑到我们自定义的处流,限流
9.1.3、测试
1秒钟点击1下,OK
超过上述,疯狂点击,返回了自己定义的限流处理信息,限流发生
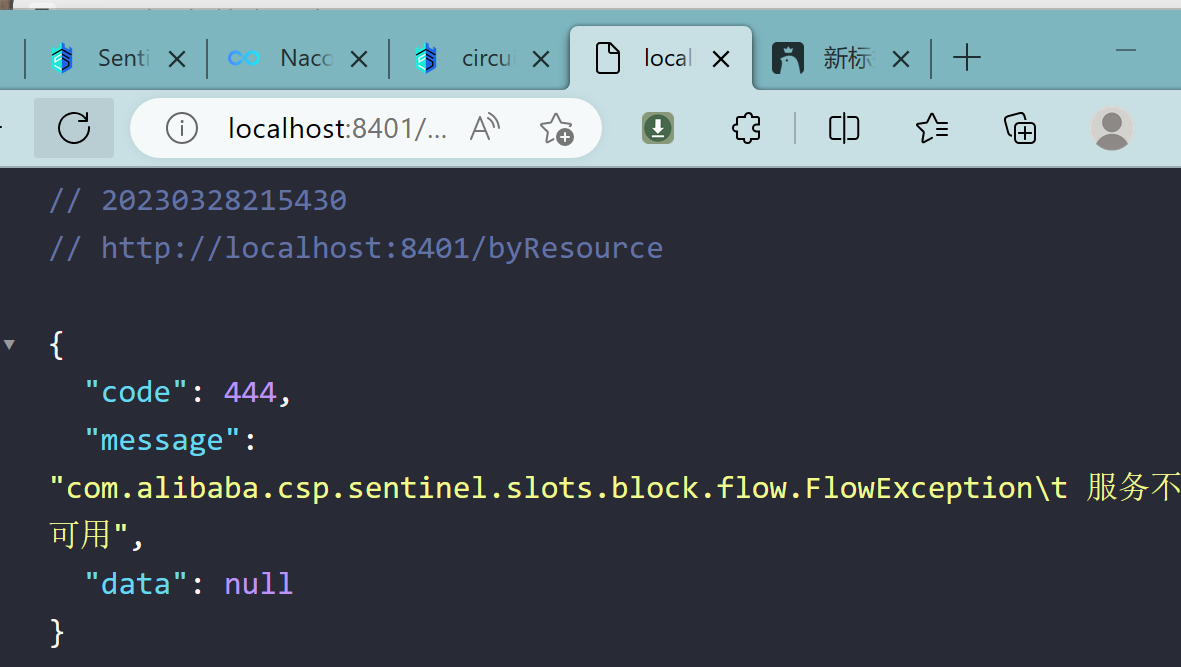
9.1.4、额外问题
此时关闭问服务8401看看
Sentinel控制台,流控规则消失了?????
临时/持久?
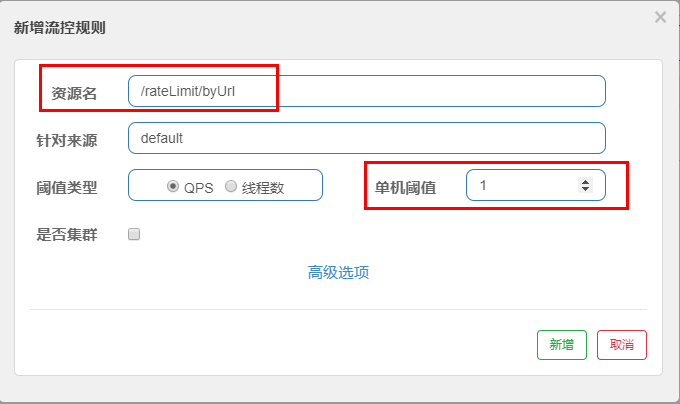
9.2、按照Url地址限流+后续处理
通过访问的URL来限流,会返回Sentinel自带默认的限流处理信息
访问一次http://localhost:8401/rateLimit/byUrl
sentinel配置:
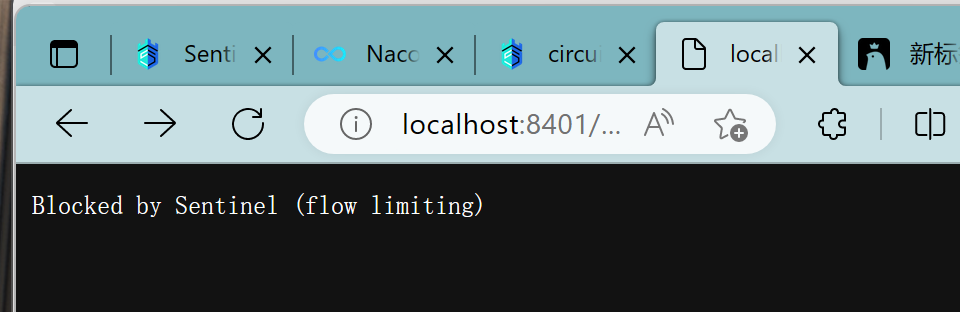
测试:
疯狂点击http://localhost:8401/rateLimit/byUrl
9.3、上面兜底方案面临的问题
- 系统默认的,没有体现我们自己的业务要求。
- 依照现有条件,我们自定义的处理方法又和业务代码耦合在一块,不直观。
- 每个业务方法都添加一个兜底的,那代码膨胀加剧
- 全局统一的处理方法没有体现。
9.4、客户自定义限流处理逻辑
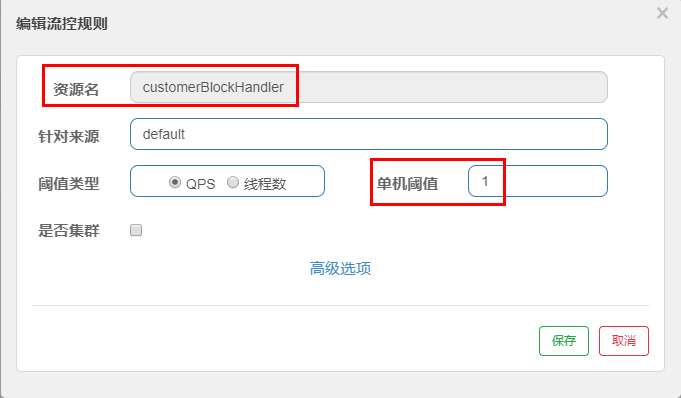
9.4.1、创建CustomerBlockHandler类用于自定义限流处理逻辑
1 | package com.lxg.springcloud.handler; |
9.4.2、RateLimitController
1 | /** |
9.4.3、启动微服务后先调用一次
9.4.4、配置
9.4.5、狂刷
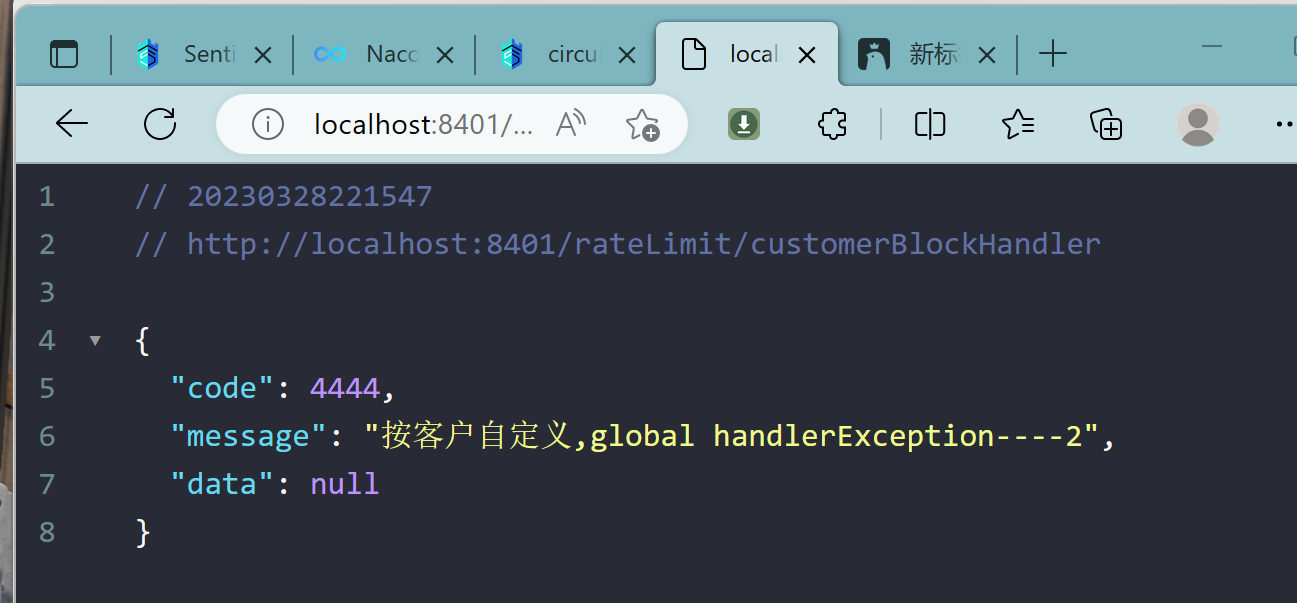
9.4.6、进一步说明

9.5、更多注解属性说明

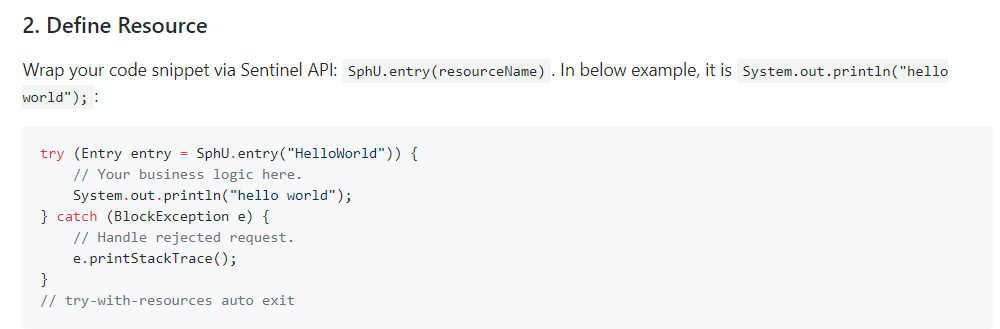
所有的代码都要用try-catch-finally方式进行处理,o(╥﹏╥)o
Sentinel主要有三个核心Api:
- SphU定义资源
- Tracer定义统计
- ContextUtil定义了上下文
10、服务熔断功能
10.1、sentinel整合ribbon+openFeign+fallback
10.2、Ribbon系列
10.2.1、启动nacos和sentinel
10.2.2、新建9003/9004模块
新建cloudalibaba-provider-payment9003/9004两个一样的做法
1、pom文件
1 |
|
2、application.yml
1 |
|
3、主启动类
1 | package com.lxg.springcloud; |
4、业务类
1 | package com.lxg.springcloud.controller; |
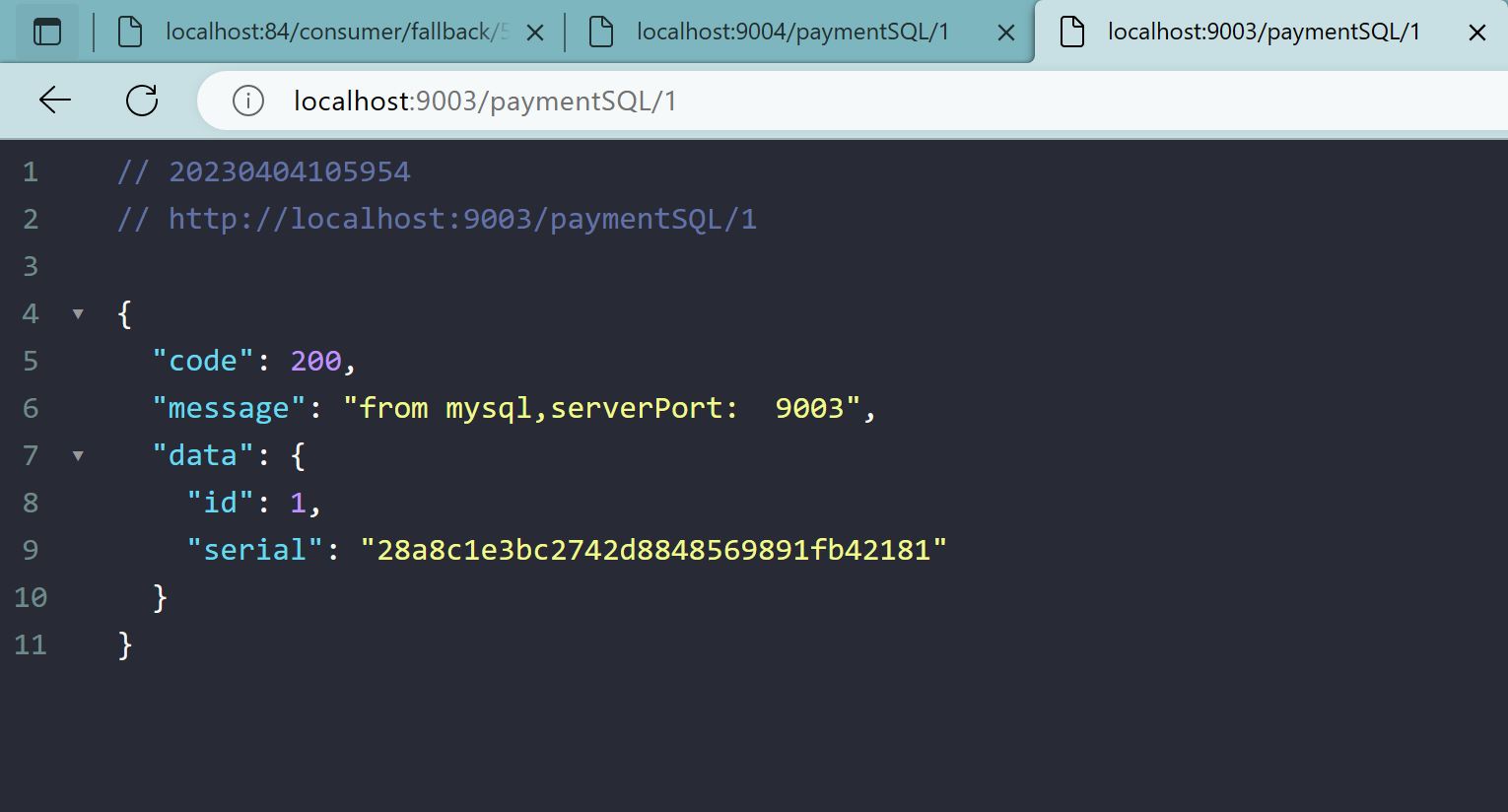
5、测试地址
http://localhost:9003/paymentSQL/1
10.2.3、新建消费者84模块
新建cloudalibaba-consumer-nacos-order84
1、pom文件
1 |
|
2、application.yml
1 | server: |
3、主启动类
1 | package com.lxg.springcloud; |
4、业务类
1 | package com.lxg.springcloud.controller; |
5、ApplicationContextConfig
1 | package com.lxg.springcloud.config; |
6、修改后重启微服务
热部署对java代码级生效及时
对@SentinelResource注解内属性,有时效果不好
7、目的
fallback管运行异常
blockHandler管配置违规
8、测试地址
http://localhost:84/consumer/fallback/1
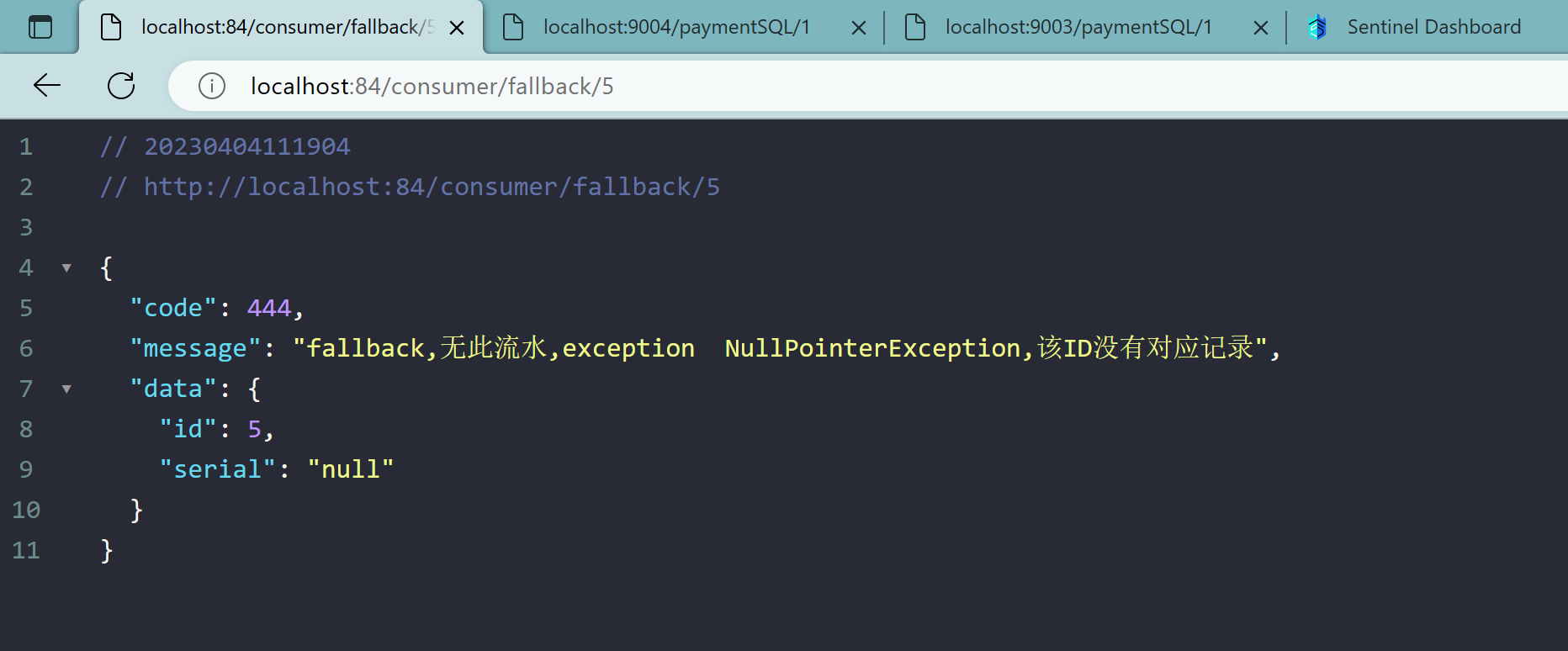
9、无任何配置情况
给客户error页面,不友好
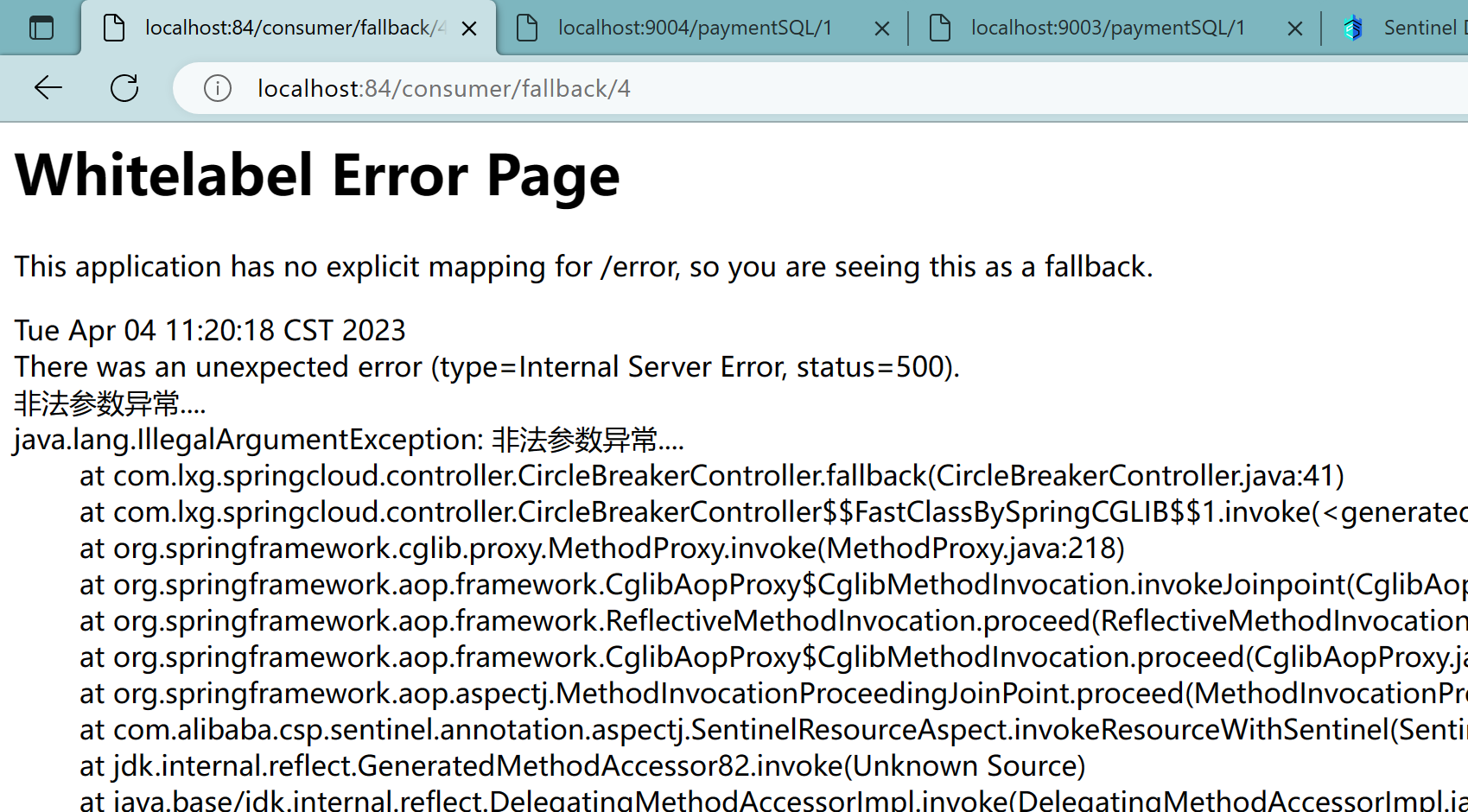
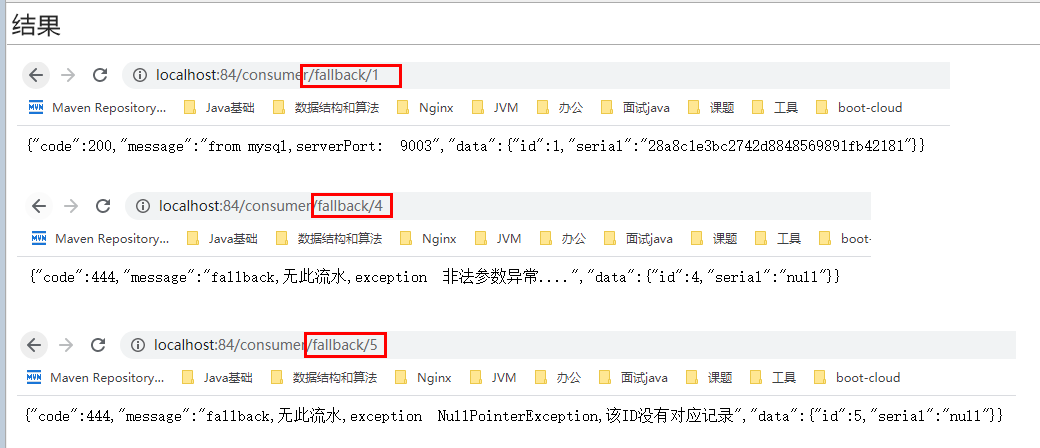
10、只配置fallback
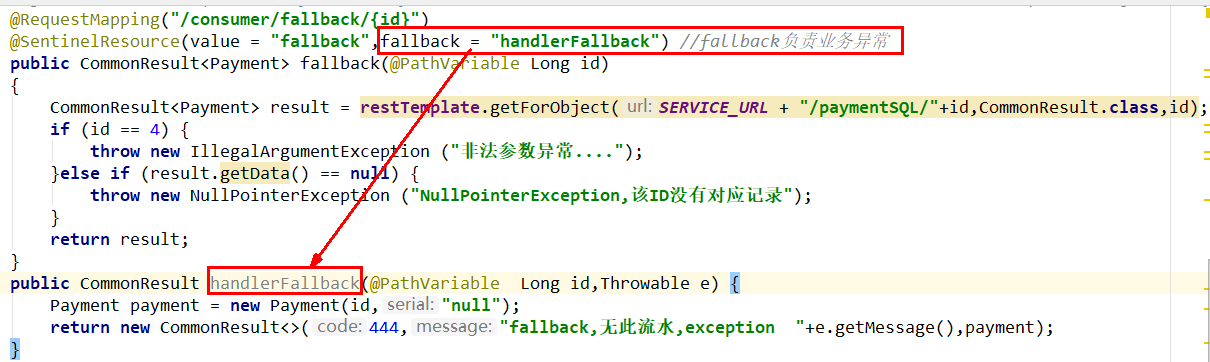
本例sentinel无配置
11、只配置blockHandler
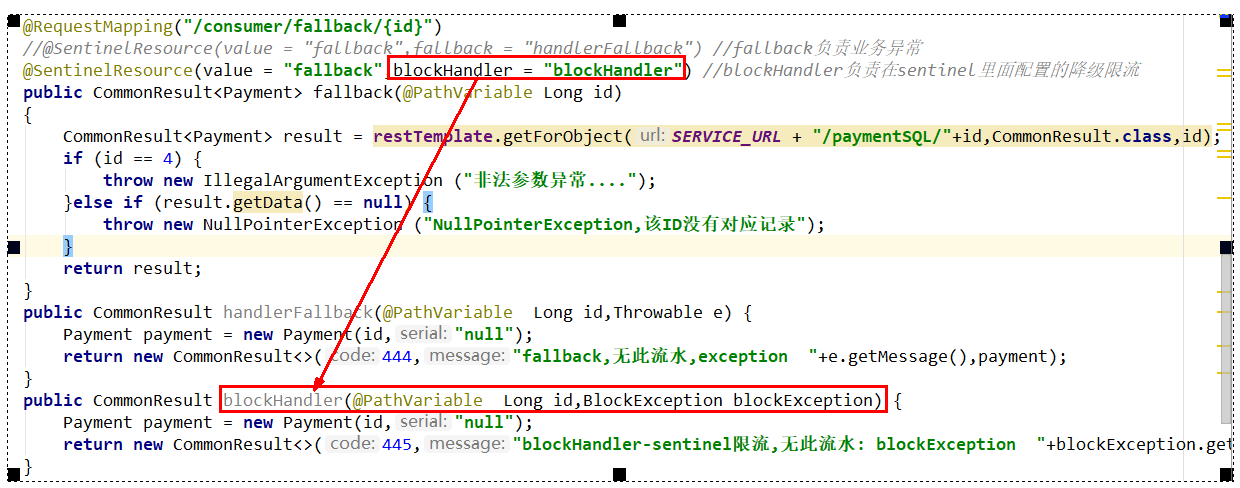
本例sentinel需配置:

12、fallback和blockHandler都配置

本例sentinel需配置

13、忽略属性…….
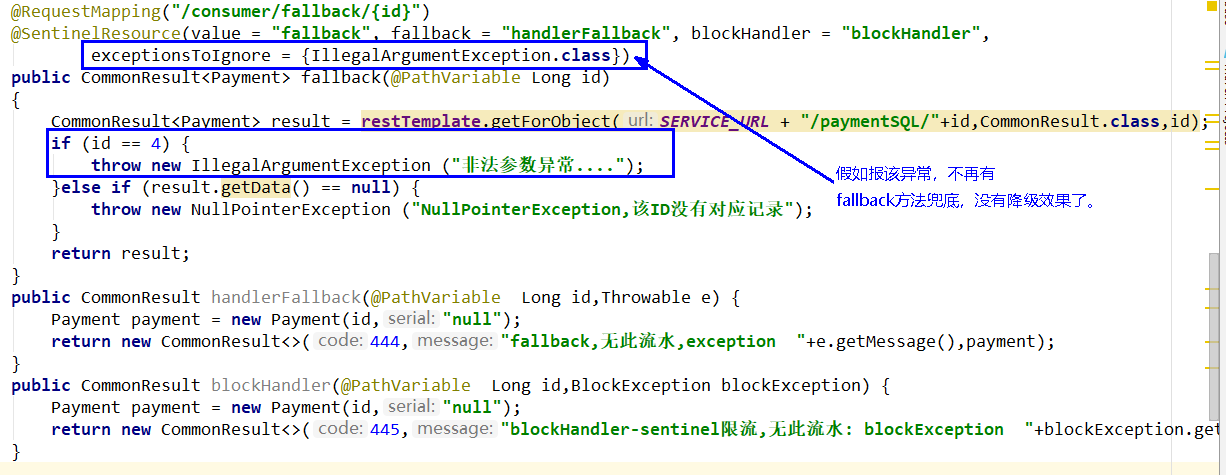
本例sentinel无配置
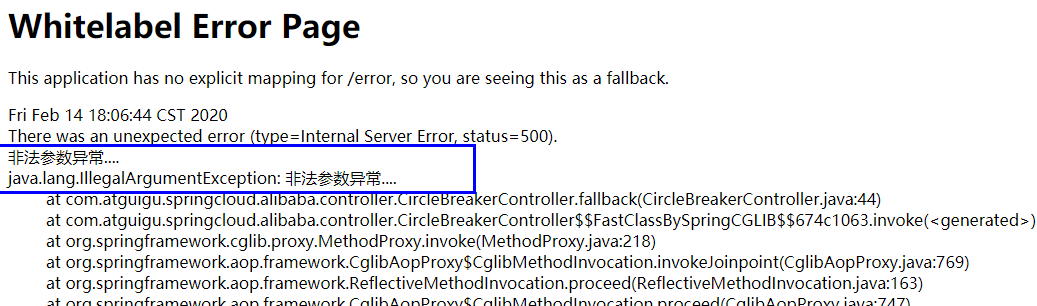
程序异常打到前台了,对用户不友好
10.3、Feign系列
10.3.1、修改84模块
84消费者调用提供者9003
Feign组件一般是消费侧
1、pom文件新增
1 | <!--SpringCloud openfeign --> |
2、yml修改
1 | server: |
激活Sentinel对Feign的支持
3、主启动添加注解
1 |
|
添加@EnableFeignClients启动Feign的功能
4、业务类
PaymentService
1 | package com.lxg.springcloud.service; |
PaymentFallbackService
1 | package com.lxg.springcloud.service; |
Controller
1 | package com.lxg.springcloud.controller; |
5、访问
http://localhost:84/consumer/paymentSQL/1
测试84调用9003,此时故意关闭9003微服务提供者,看84消费侧自动降级,不会被耗死
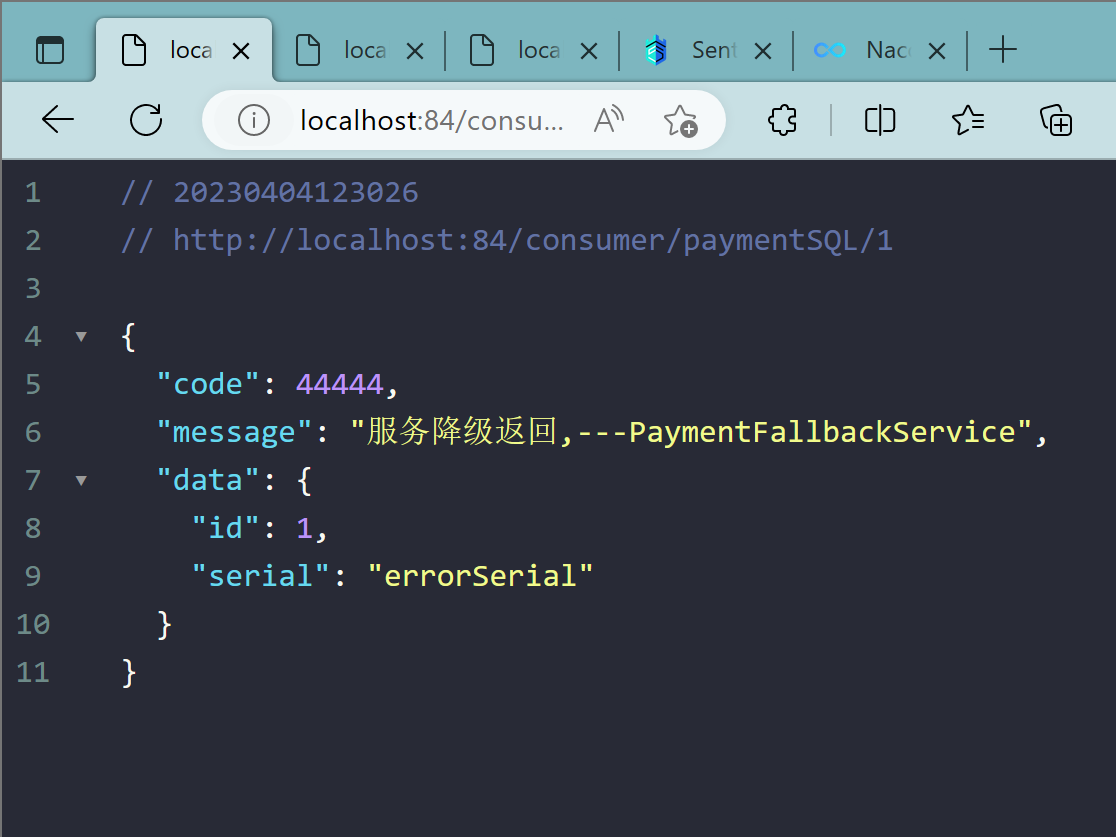
10.3.2、熔断框架比较
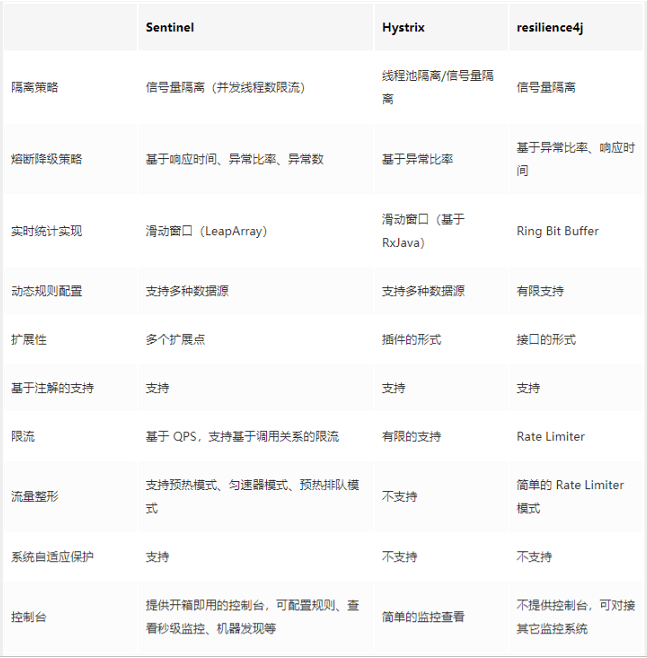
11、规则持久化
11.1、是什么
一旦我们重启应用,sentinel规则将消失,生产环境需要将配置规则进行持久化
11.2、怎么玩
将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台
的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上sentinel上的流控规则持续有效
11.3、步骤
11.3.1、修改cloudalibaba-sentinel-service8401
1、pom文件
1 | <!--SpringCloud ailibaba sentinel-datasource-nacos --> |
2、yml
1 | server: |
11.3.2、添加Nacos业务规则配置
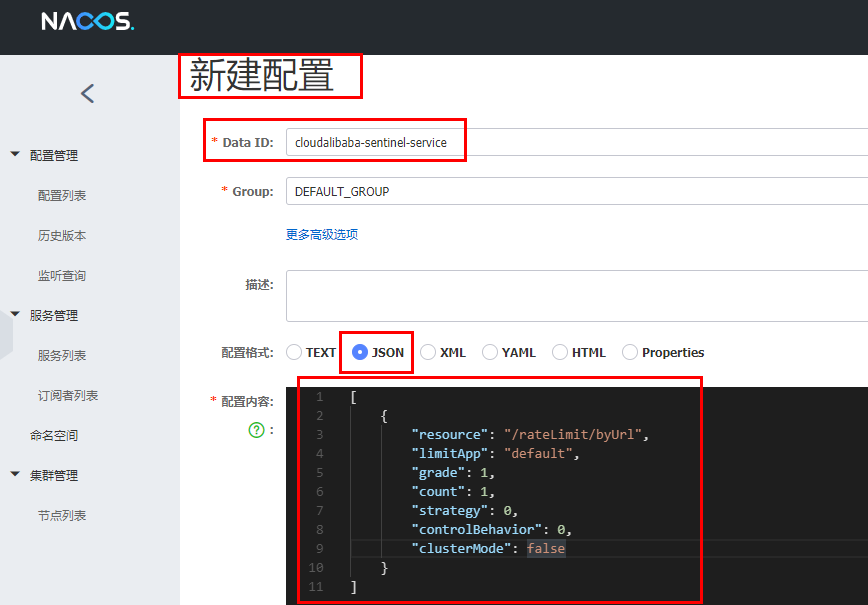
1 |
|
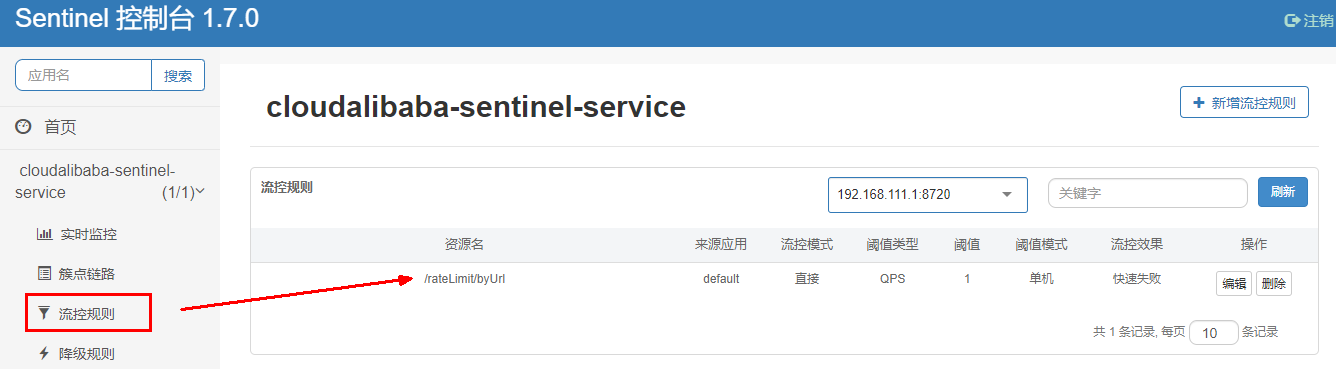
11.3.3、启动8401后刷新sentinel发现业务规则有了
11.3.4、快速访问测试接口
http://localhost:8401/rateLimit/byUrl

11.3.5、停止8401再看sentinel
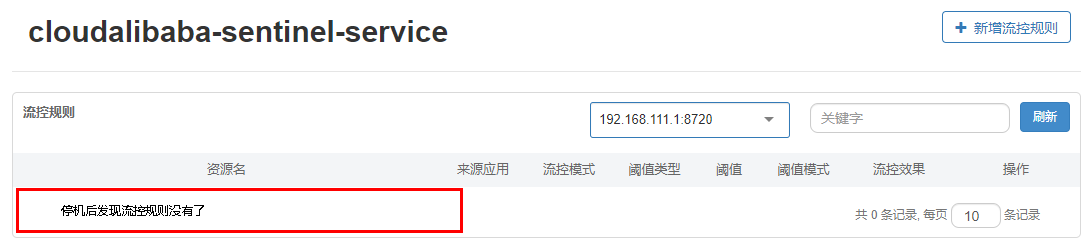
11.3.6、重新启动8401再看sentinel
乍一看还是没有,稍等一会儿
多次调用:http://localhost:8401/rateLimit/byUrl
配置重新出现了,持久化验证通过
四、SpringCloud Alibaba
1、分布式事务问题\
1.1、分布式前
单机单库没这个问题
从1:1 -> 1:N -> N:N
1.2、分布式之后
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,
业务操作需要调用三个服务来完成。此时每个服务内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证。
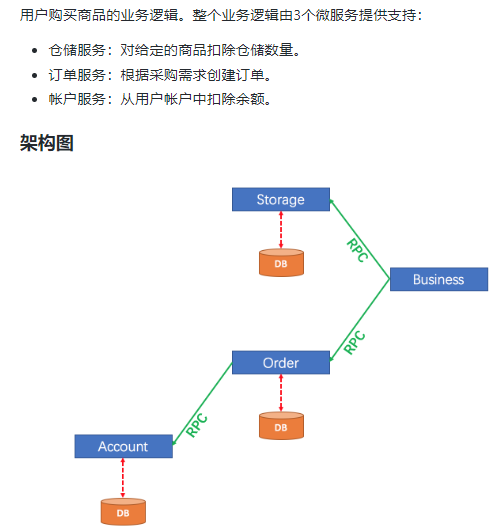
一句话:一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题
2、Seata简介
2.1、是什么
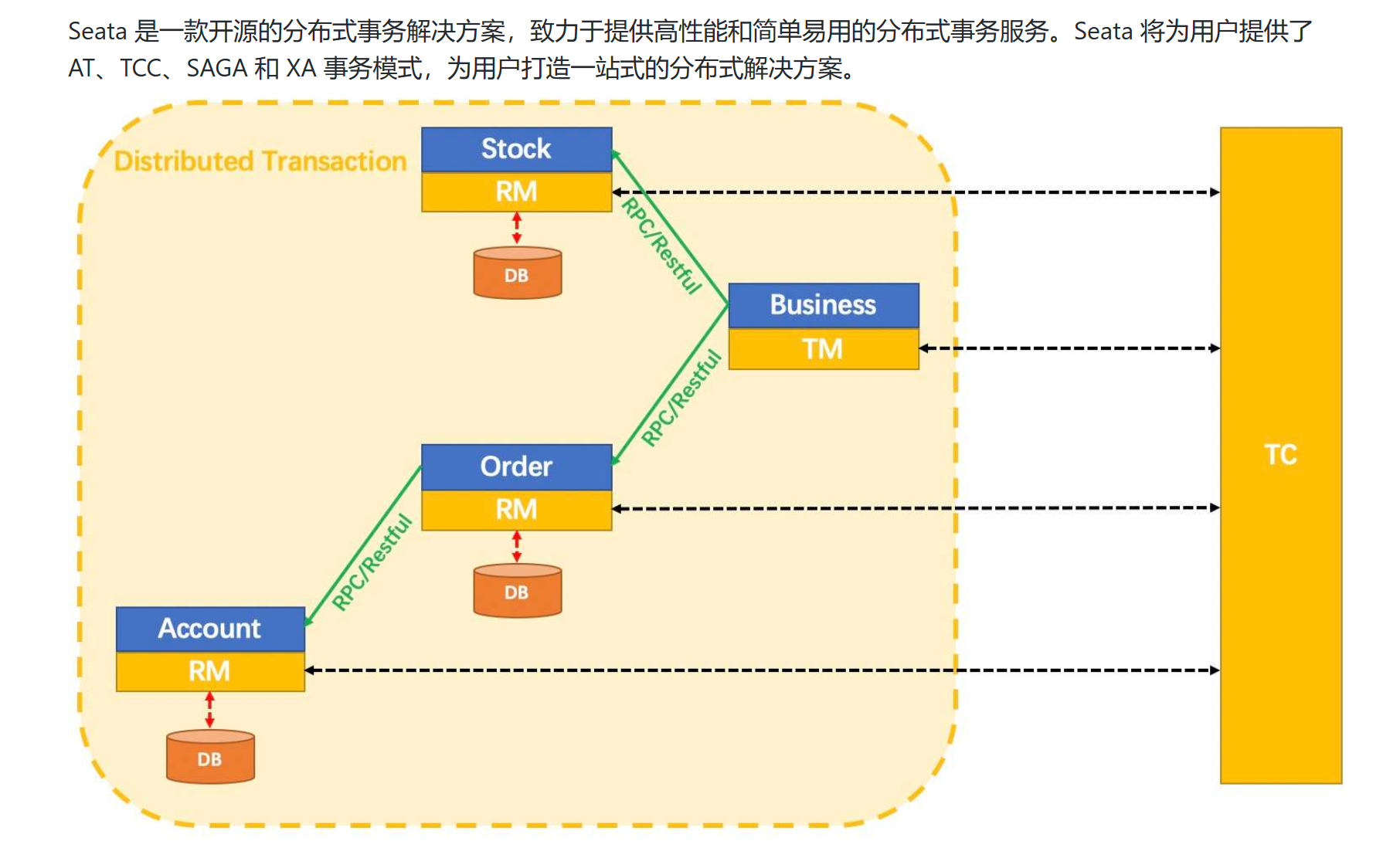
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
2.2、能干嘛
一个典型的分布式事务过程:
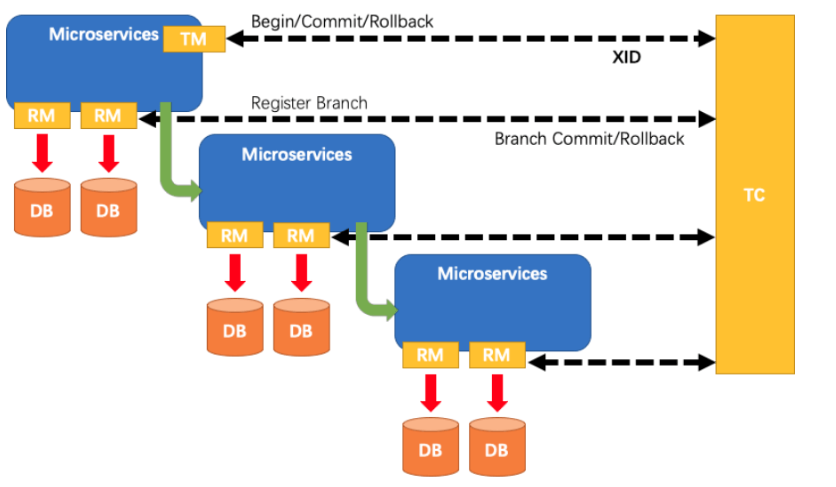
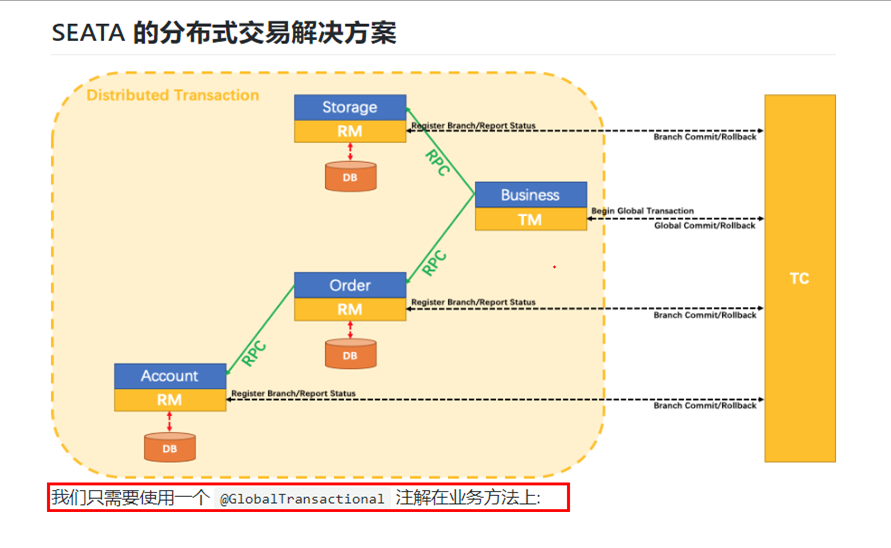
2.2.1、分布式事务处理过程的一ID+三组件模型:
- Transaction ID XID:全局唯一的事务ID
- 3组件概念:
- Transaction Coordinator (TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
- Transaction Manager (TM):控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
- Resource Manager (RM):控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
2.2.2、处理过程
1 | 1、TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID; |
2.3、去哪下
发布说明: https://github.com/seata/seata/releases
2.4、怎么玩
本地@Transactional
全局@GlobalTransactional
SEATA 的分布式交易解决方案:
3、Seata-Server安装
3.1、官网地址
3.2、下载版本
https://github.com/seata/seata/releases
下载的是seata-server-1.6.0.zip
3.3、seata-server-1.6.0.zip解压到指定目录并修改conf目录下的application.yml配置文件
先备份application.yml
主要修改:事务日志存储模式为db+数据库连接信息
application.yml:
1 | server: |
3.4、mysql5.7数据库新建库seata
3.5、在seata库里建表
建表sql在/seata/script/server/db/mysql.sql
1 | -- -------------------------------- The script used when storeMode is 'db' -------------------------------- |
3.6、启动nacos端口号8848
3.7、启动seata-server
双击即可
3.8、以上配置可参考
4、订单/库存/账户业务数据库准备
以下演示都需要先启动Nacos后启动Seata,保证两个都OK
Seata没启动报错:no available server to connect
4.1、分布式事务业务说明
4.1.1、业务说明
这里我们会创建三个服务,一个订单服务,一个库存服务,一个账户服务。
当用户下单时,会在订单服务中创建一个订单,然后通过远程调用库存服务来扣减下单商品的库存,
再通过远程调用账户服务来扣减用户账户里面的余额,
最后在订单服务中修改订单状态为已完成。
该操作跨越三个数据库,有两次远程调用,很明显会有分布式事务问题。
下订单—>扣库存—>减账户(余额)
4.2、创建业务数据库
seata_order:存储订单的数据库;
seata_storage:存储库存的数据库;
seata_account:存储账户信息的数据库。
建库SQL:
1 |
|
4.3、按照上述3库分别建对应业务表
seata_order库下建t_order表:
1 |
|
seata_storage库下建t_storage 表:
1 |
|
seata_account库下建t_account 表:
1 |
|
4.4、按照上述3库分别建对应的回滚日志表
订单-库存-账户3个库下都需要建各自的回滚日志表
建表sql:seata/script/client/at/db at master · seata/seata · GitHub
1 | -- for AT mode you must to init this sql for you business database. the seata server not need it. |
4.5、最终效果
5、订单/库存/账户业务微服务准备
5.1、业务需求
下订单->减库存->扣余额->改(订单)状态
5.2、新建订单seata-order-service2001
5.2.1、pom
1 |
|
5.2.2、yml
1 | server: |
5.2.3、file.conf(可能是没有配置nacos配置中心)
1 | transport { |
5.2.4、registry.conf(可在yml直接配置)
1 | # registry { |
yml配置
1 | registry: |
5.2.5、domain
1、CommonResult
1 | package com.lxg.springcloud.domain; |
2、Order
1 | package com.lxg.springcloud.domain; |
5.2.6、Dao接口
1 | package com.lxg.springcloud.dao; |
OrderMapper:
1 |
|
5.2.7、Service
AccountService接口:
1 | package com.lxg.springcloud.service; |
OrderService:
1 | package com.lxg.springcloud.service; |
StorageService:
1 | package com.lxg.springcloud.service; |
OrderServiceImpl:
1 | package com.lxg.springcloud.service.impl; |
5.2.8、controller
1 | package com.lxg.springcloud.controller; |
5.2.9、config
MyBatisConfig
1 | package com.lxg.springcloud.config; |
DataSourceProxyConfig:新版配置就启动报错
1 | package com.lxg.springcloud.config; |
5.2.10、主启动类
1 | package com.lxg.springcloud; |
如果数据源配置有效就要@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
5.3、seata-order-service2001
5.3.1、pom文件
与以上模块一致
5.3.2、yml文件
1 | server: |
5.3.3、domain
1 | package com.lxg.springcloud.domain; |
1 | package com.lxg.springcloud.domain; |
5.3.4、dao
1 | package com.lxg.springcloud.dao; |
1 |
|
5.3.5、service
1 | package com.lxg.springcloud.service; |
1 | package com.lxg.springcloud.service.Impl; |
5.3.6、controller
1 | package com.lxg.springcloud.controller; |
5.3.7、file.conf
与上模块一致
5.3.8、registry.conf
与上模块一致
5.3.9、config
与上模块一致
5.3.10、主启动类
1 | package com.lxg.springcloud; |
5.4、seata-account-service2003
5.4.1、pom
与以上一致
5.4.2、yml文件
1 | server: |
5.4.3、domain
1 | package com.lxg.springcloud.domain; |
1 | package com.lxg.springcloud.domain; |
5.4.4、file.conf
与以上一致
5.4.5、registry.conf
与以上一致
5.4.6、dao
1 | package com.lxg.springcloud.dao; |
5.4.7、service
1 | package com.lxg.springcloud.service; |
1 | package com.lxg.springcloud.service.impl; |
5.4.8、controller
1 | package com.lxg.springcloud.controller; |
5.4.9、config
与以上一致
5.4.10、主启动类
1 | package com.lxg.springcloud; |
6、Test
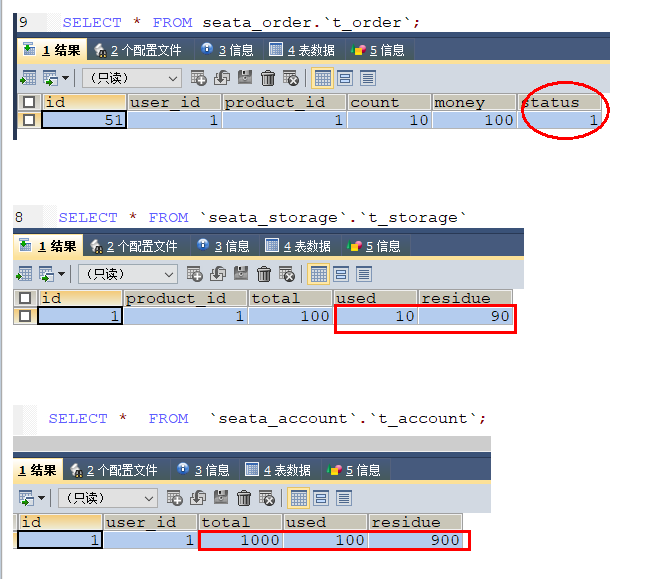
下订单->减库存->扣余额->改(订单)状态
数据库初始情况:
6.1、正常下单
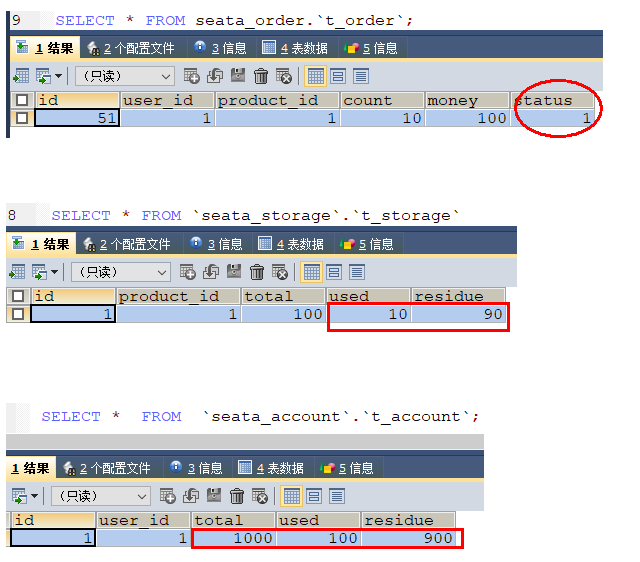
http://localhost:2001/order/create?userId=1&productId=1&count=10&money=100
数据库情况:
 6.2、超时异常,没加@GlobalTransactional
6.2、超时异常,没加@GlobalTransactional
http://localhost:2001/order/create?userId=1&productId=1&count=10&money=100
AccountServiceImpl添加超时
故障情况:
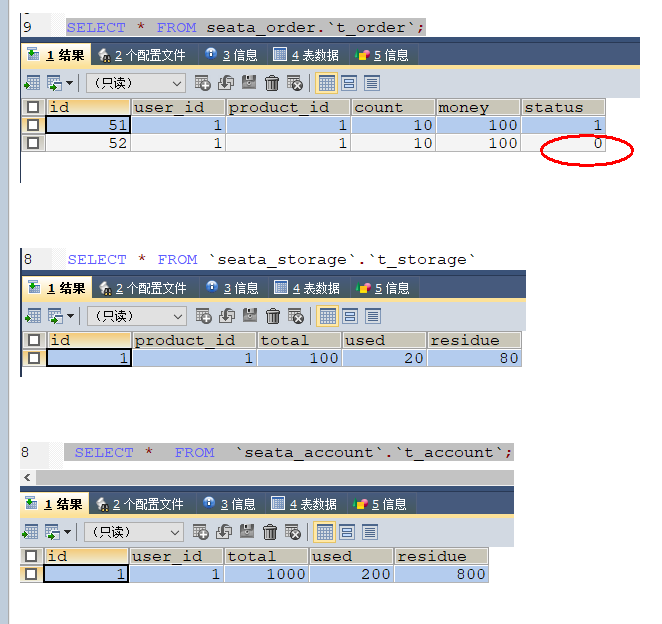
当库存和账户金额扣减后,订单状态并没有设置为已经完成,没有从零改为1
而且由于feign的重试机制,账户余额还有可能被多次扣减
6.3、超时异常,添加@GlobalTransactional
AccountServiceImpl添加超时
OrderServiceImpl@GlobalTransactional
1 |
|
下单后数据库数据并没有任何改变
记录都添加不进来
7、一部分补充
7.1、Seata
2019年1月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案
Simple Extensible Autonomous Transaction Architecture,简单可扩展自治事务框架
2020起始,参加工作后用1.0以后的版本
7.2、再看TC/TM/RM三大组件
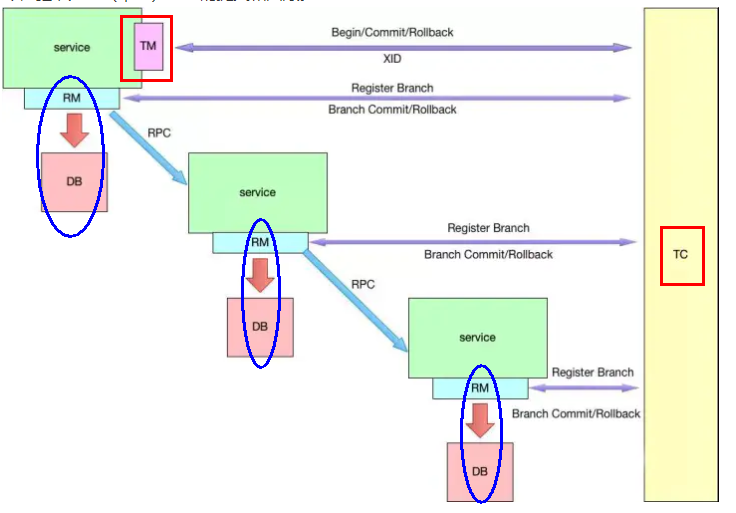
分布式事务的执行流程:
- TM 开启分布式事务(TM 向 TC 注册全局事务记录);
- 按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
- TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
- TC 汇总事务信息,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束。
7.3、AT模式如何做到对业务的无侵入
7.3.1、是什么
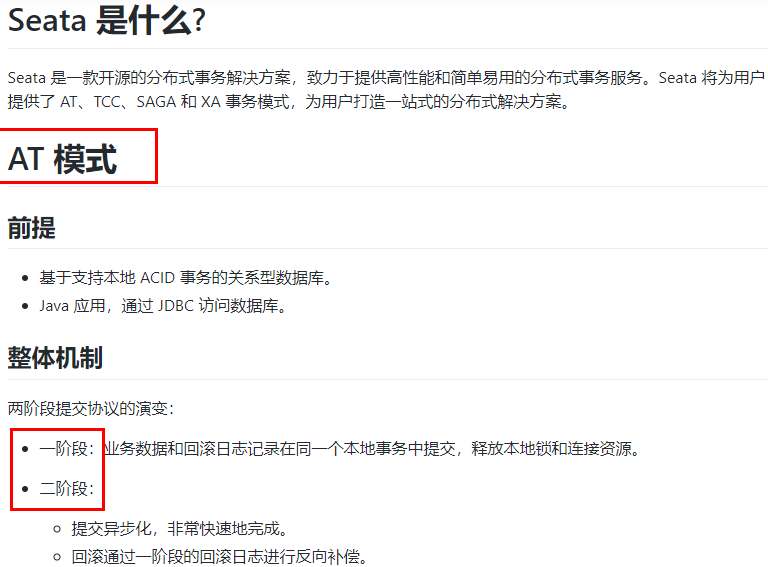
7.3.2、一阶段加载
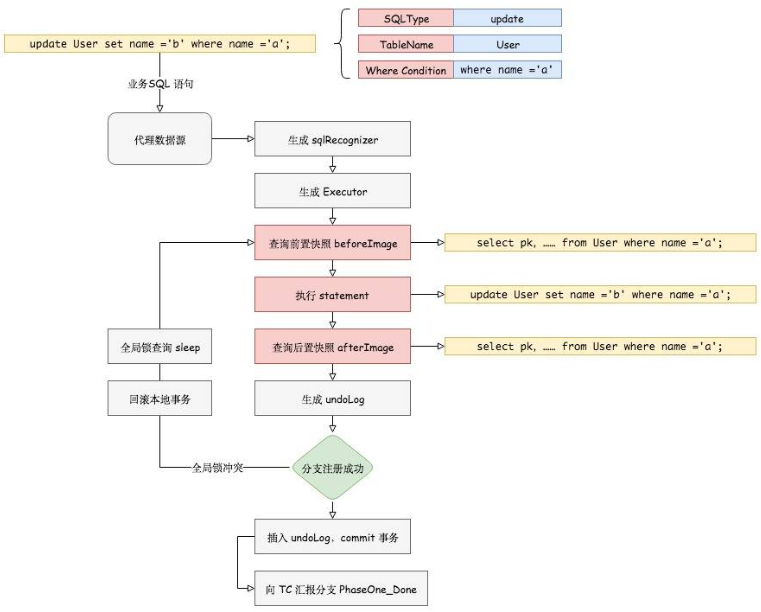
在一阶段,Seata 会拦截“业务 SQL”,
1 解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,
2 执行“业务 SQL”更新业务数据,在业务数据更新之后,
3 其保存成“after image”,最后生成行锁。
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
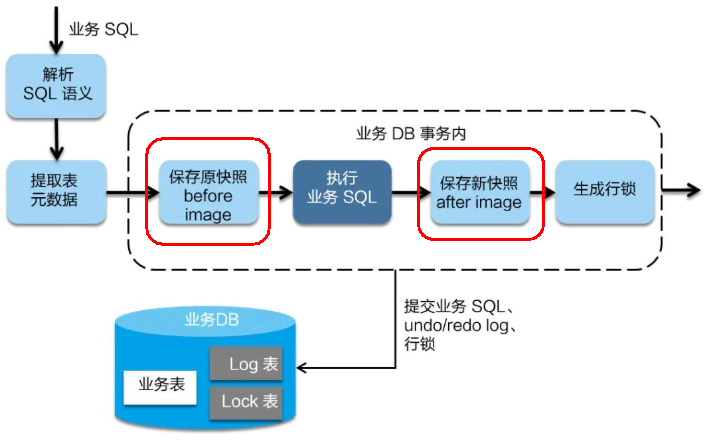
7.3.3、二阶段提交
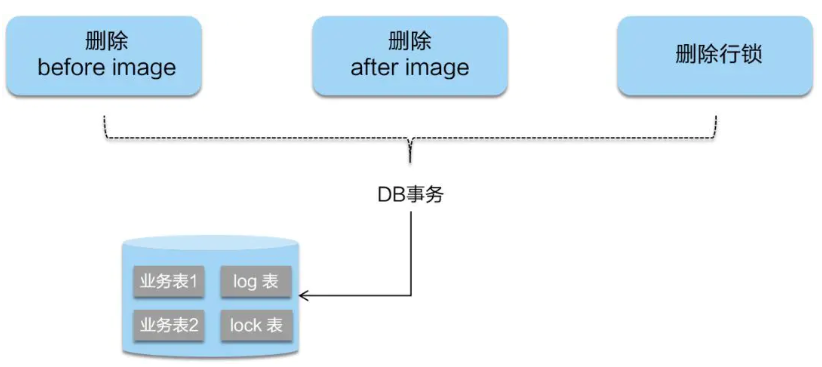
二阶段如是顺利提交的话,
因为“业务 SQL”在一阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
7.3.4、二阶段回滚
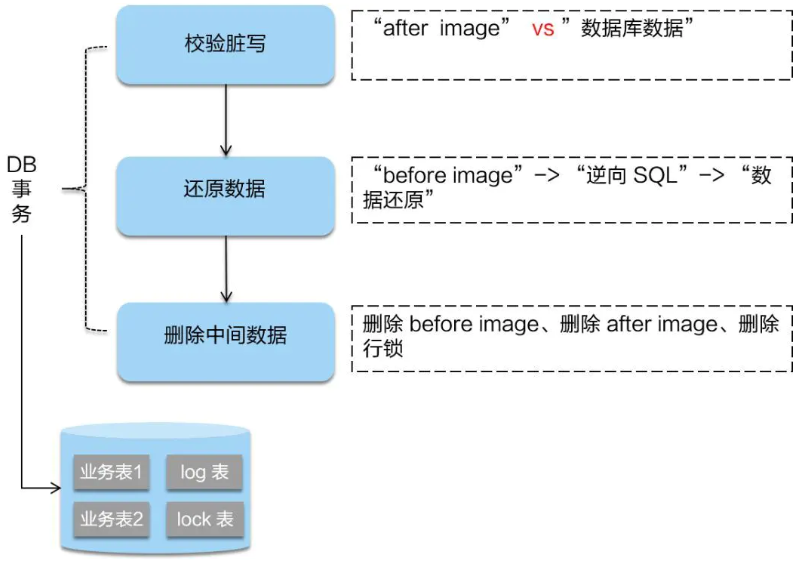
二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。
回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,
如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
7.4、自己debug
会发现seata数据库的表数据和undo.log表的数据有变化
7.5、补充
具体其他内容可以阅读官网文档:
